





CC2019. Расшифровка доклада "Комплекс автоматизатора"
 470
470

 11278
11278
 0
0



25-го августа в Питере на Chaos Construction 2019 я выступил с докладом о сетевой автоматизации.
Сразу после доклада и после него ко мне подходили несколько раз с просьбой выложить слайды. Чому-бы и нет, как говорится, тем более, что черновики в том или ином виде были.
Дисклеймер: ниже вы не найдёте структурированных систематизированных данных — только обрывки черновиков, мыслей и расшифровки.
Сами слайды доступны тут.

1. Зачем нужна автоматизация
 По статистике 80% проблем на сети случаются при изменении конфигурации.
По статистике 80% проблем на сети случаются при изменении конфигурации.
Да, бывает, что экскаватор не там покопал, подстанция выключилась или машзал сгорел, но это во-первых бывает редко, а во-вторых, обычно от таких вещей мы защищены: резервным каналом, вводом, георезервированием, планированием Disaster Recovery.
А вот обновление: софта, конфигурации. Разломать при этом сеть — это милое дело.
Есть ещё такая вещь, как баги железа и софта на сетевых коробках.
Это не очень-то предсказуемые события и не всегда запускаются руками инженера. Но на самом деле, как увидим позже, это ещё один аргумент в пользу автоматизации.
 И перед тем как мы углубимся в эту тему, хочу обратить внимание, что под автоматизацией стоит понимать не раскатку конфигурации по железкам или обновление ПО на пачке коробок.
И перед тем как мы углубимся в эту тему, хочу обратить внимание, что под автоматизацией стоит понимать не раскатку конфигурации по железкам или обновление ПО на пачке коробок.
Это гораздо более комплексный вопрос. Речь про обеспечение Life-Cycle сети глобально. Это включает в себя и Configuration Management, и Change Management, и мониторинг всего и вся на сети, начиная с базовой доступности хостов и сбора логов и, заканчивая отслеживанием путей прохождения трафика, потерь на конкретных узлах, задержек и прочего. Сюда же и контроль всего, что происходит в сети, в том числе различные виды атак, проверка работоспособности сервисов.
То есть сеть должна представлять из себя единый комплекс, который предоставляет инженерам в некотором смысле интерфейс работы с ней.
А не так что инженер пошёл на железку, ввёл команду и ждёт — позвонит ему клиент, чтобы сообщить о проблеме — или всё ок.
То есть мы как владельцы сети должны узнавать о проблемах сети раньше, чем заказчики.
И все отдельные части должны работать как единая система.
Новые версии конфигурации должны сначала тестироваться до попадания на коммерческую сеть.
При выкатке новой конфигурации, если что-то пошло не так, мгновенно должна загораться лампочка.
События мониторинга, которые требуют вполне определённых действий инженера, могут и должны запускать механизмы автоматизации, которые полечат проблему.
Подозрительная активность должна блокироваться или быть отрапортована нужному человеку.
То есть это организм с большим количеством взаимодействующих частей и обратной связью. Изменения в одном органе влекут к изменения в другом. А наружу он торчит руками, ногами и ртом.
Сегодня средние и крупные компании уже имеют разрозненные куски этой системы, которые начинают взаимодействовать.
Но вот та часть, которая про life-cycle конфигурации сети — она всё ещё в большинстве случае в зачаточном состоянии.
И сегодня мы пытаемся вслепую нащупать, что нам поможет в этом деле. Возможно, мы скоро откроем глаза и увидим, что все щупали одного слона, а может, нет. Тогда надо будет остановиться, вдохнуть и выбрать фаворита, которого дальше развивать.
Но вообще, фавориты уже начинают вырисовываться. Про это попозже.
 Итак, автоматизация нам нужна для того, чтобы настраивать разом много устройств, избегать ошибок конфигурации, следить за консистентностью и актуальностью конфигурации, детектировать аномалии в сети и как-то на них реагировать. Ну и как я уже сказал, предоставлять пользователю интерфейс работы с сетью.
Итак, автоматизация нам нужна для того, чтобы настраивать разом много устройств, избегать ошибок конфигурации, следить за консистентностью и актуальностью конфигурации, детектировать аномалии в сети и как-то на них реагировать. Ну и как я уже сказал, предоставлять пользователю интерфейс работы с сетью.
Это если глобально и абстрактно.
Нас же, людей, которые нюхают пыль OSPF и роют ямы с утра и до коммита, интересует как быть с конфигурацией.
 Тут давайте по нарастающей.
Тут давайте по нарастающей.
Во-первых, железку надо как-то инициализировать. Вот она приехала пустая на склад. Вот её надо поставить на сайт. Кто-то настраивает её руками на стенде, потом везёт, кто-то использует вендорский ZTP, кто-то придумывает своё, кто-то наливает конфигурацию уже на месте через консоль. Главное — чтобы появился SSH на коробку.
Это то, что называется Day-0 конфигурация. Потом в Day-1 железку нужно ввести в эксплуатацию. То есть накатить на неё продовый конфиг с OSPFами, BGP, LDP, политиками и ACL.
Вот до этого момента все, кто хотел, более или менее, умеют в автоматику. Нагенерить Day-1 конфигурацию очень легко.
Интересное начинается дальше — это ежедневная работа. Небольшие изменения ACL, средние изменения IP-конфигурации, большие изменения политики маршрутизации, катастрофические изменения дизайна. И вот поддерживать эти изменения в автоматическом режиме — это уже вызов для сильным духом компаний с туго набитым кошельком.
Дело в том, что это предполагает приведение конфигурации к желаемому состоянию — то есть просто пульнуть в CLI набор команд — недостаточно. В общем-то это то, что мы и делаем в своей повседневной работе — настраиваем железку, приводя её к нужной конфигурации. Вот только наш опыт очень плохо перекладывается на рельсы автоматизации. Совсем непросто научить скрипты делать то, что мы сами делали из года в год. Если вы не согласны, то ответьте на вопрос, как поменять адрес NTP-сервера, не указывая специально, что нужно создать новый и удалить старый.
Итак, любая операция должна переводить устройство из одного состояния в другое.
А что это, если не версионирование? Любое изменение конфигурации — это новая версия. Примерно, как разработка веб-сервисов.
И тогда каждый раз, как мы что-то делаем на устройстве — мы фактически катим новую версию.
А что если мы пойдём дальше? Мы будем версионировать конфигурацию не устройства, а всей сети.
Мы можем специфицировать наши дизайны сети. И любое минорное изменение — даже MTU поправить на интерфейсе — это обновление дизайна на новую версию — была 1.5.0 стала 1.5.1.
И тогда мы не устройство переводим на новую версию, а всю сеть. При этом если где-то изменения не применились, то опять же вся сеть откатывается до предыдущей версии, потому что частичный деплой — хуже, чем никакого.
Соответственно, как мы можем двигаться по цифре версии вверх, так же, можем и вниз. То есть это уже не ролбэк конфигурации на отдельных коробках, а даунгрейд сети на более раннюю — рабочую версию.
Вот такой подход помогает нам воспринимать сеть и работать с ней, как с единой сущностью, а не набором коробок.
И конфигурация устройств тут является продуктом специфицированного дизайна. Хотим что-то поменять — документируем это в дизайне, перегенерим конфигурацию сети и раскладываем это на конфигурацию устройств.
Ну и ещё один шаг, без которого автоматизация может принести больше бед, чем пользы — это тестирование и мониторинг.
Это баззворд сегодняшних разговоров о сети — CI/CD. Все хотят, кое-кто говорит, мало кто пытается, почти никто не сделал. А идея — перенять практику быстрого и частого деплоя новых версий в прод из сферы разработки. Для этого она должна пройти испытания в тестовой среде.
То есть мы раскатываем конфигурацию на тестовой топологии, прогоняем заранее написанные тесты, смотрим на мониторинги здоровья сервисов, выжидаем какой-то период стабильности, и, если всё хорошо, катим в прод, где опять же по мониторингам и тестам смотрим, всё ли в порядке.
Красиво же.
Но есть нюанс. У разработчиков всё хорошо: контейнеры, виртуалочки, SDN. По кнопке разворачивается контролируемая всегда одинаковая среда, полностью повторяющая прод. И с очень большой вероятностью если приложение работает в тестовой среде, оно заработает и в проде.
С сетью сложно. Реально сложно во всех отношениях. Полностью всё виртуализировать нельзя. Даже если закрыть глаза на то, что не у всех вендоров есть образы их металлических коробок, всё равно остаётся QoS, который исключительно аппаратно зависим, остаются вещи специфичные для чипов и разных линеек, остаются баги железа.
То, что заработало на стейжинге, не факт, что заработает на проде.
Кроме того далеко не каждая компания может позволить себе собрать отдельный аппаратный стенд для тестов.
И даже с аппаратным стендом остаётся вопрос идентичности стенда и прода.
Не очень просто по нажатию кнопки развернуть абсолютно точную копию прода в уменьшенном масштабе.
В общем касательно сетевого CI/CD-пайплайна сегодня больше вопросов, чем решений. Самые смелые и умелые чего-то пробуют.
2. Кому нужна автоматизация
 Есть мнение, что если у вас есть два сетевых устройства, уже пора.
Есть мнение, что если у вас есть два сетевых устройства, уже пора.
Имеет право на жизнь. Ведь вам уже где-то нужно хранить информацию о том, где они стоят, как называются, какие на них интерфейсы, какие IP-адреса на хостах.
Уже неплохо бы иметь какую-то программу резервного копирования.
Но да, даже если они оба два вспыхнут синим пламенем, скорее всего, ничего не будет, и восстановить это всё можно будет за один день. А хранить всё можно в эксельке, а бэкапить баш-скриптом на фтп.
На мой личный взгляд, если уж говорить о цифрах, автоматизация приобретает смысл при счёте на десятки коробок и каком-то ненулевом их росте.
Но всё же не последнюю, а, скорее, первую роль играет то, насколько важна стабильность сети и импакт на бизнес в случае проблем.
Опять же 10 длинков в домашней сети, наверно, спокойно обойдутся и без автоматизации и мониторинга.
А вот 10 цисок, обеспечивающих работу клиники — уже другая история.
Теперь что же до инструментов, которыми мы таки вслепую что-то делаем.
3. Инструменты
Точнее даже не инструментов, а подходов, техник, средств.
Во-первых, конечно, же существует огромный, огромный пласт проприетарных решений. Системы, заточенные на то, что вся ваша сеть построена на одном вендоре. Такие решения есть практически у всех. И мы говорить о них не будем.
Начнём с вещей более универсальных.
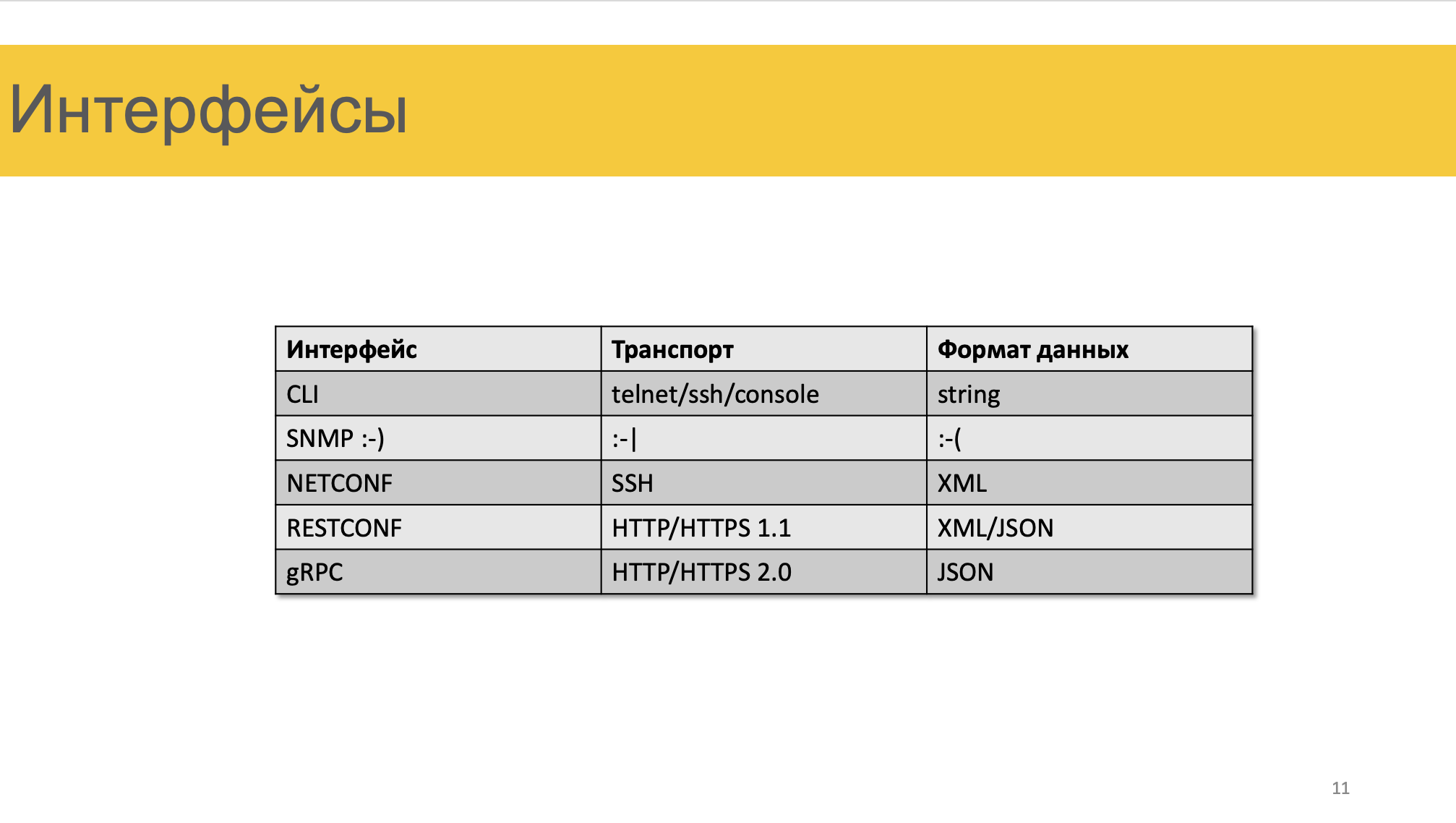 Какие у нас есть интерфейсы взаимодействия с железом?
Какие у нас есть интерфейсы взаимодействия с железом?
CLI — telnet/ssh, это строка, очевидно.
SNMP.
NETCONF — ssh, XML
RESTCONF — http 1.1, XML и JSON
gRPC — http2, JSON, бинарные данные.
Сегодня сложно сказать, на какой интерфейс делать ставку. Второй по популярности, конечно, NETCONF. RESTCONF и gRPC — вещи мало где реализованные и потому плетутся в хвосте пока, но потенциально они очень многообещающие.
Чем так хорош NETCONF?
Как минимум двумя вещами:
Во-первых, структурированные данные. С ними гораздо удобнее работать, чем со строками. И крафтить и парсить.
А, во-вторых, это операция Replace. При нормальной реализации, вся сложность с приведением конфигурации к целевой перемещается на коробку.
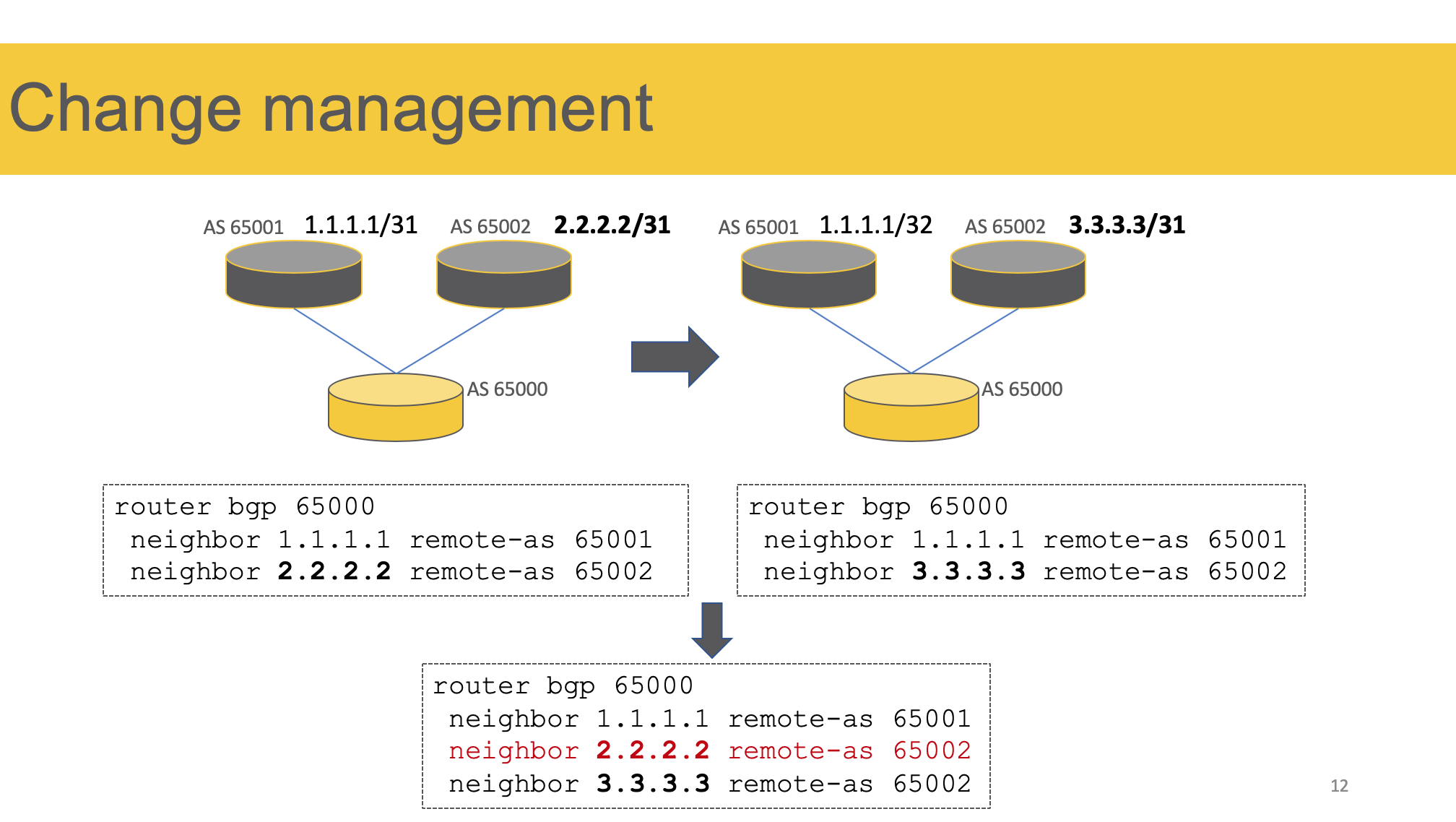 Простой пример.
Простой пример.
У нас есть вот такая сеть. С двумя BGP-пирами.
Вот такая конфигурация BGP.
На одном из них меняется IP-адрес.
Вот целевой конфиг.
Вот результат применения целевого конфига:
Мы получили три пира вместо двух.
И если это не вызывает у вас недоумения, то только потому, что позади годы работы в CLI.
Просто в нашем мозгу уже есть пророщенные синапсы, которые говорят «хочешь что-то поменять — сначала удали старое».
Доходило до смешного — для того, чтобы поменять конфигурацию интерфейса на Хуавэе, нужно было вручную выполнить undo всех недефолтных команд, применённых на нём.
А я хочу, чтобы на железе было ровно то, что я (мой код) на него отправил.
Это называется (или я так называю, пока кто-то меня не осадит) Change Management. Мы не просто хотим чего-то пушнуть на коробку, мы хотим привести её в нужное состояние.
 И здесь есть два подхода.
И здесь есть два подхода.
Первый — дорогой и болезненный — самому реализовать поддержку состояния.
То есть сгенерировать целевой конфиг, скачать текущий, скормить оба какой-то функции config_diffs, которая вернёт список команд, которые нужно выполнить. Говоря команды я имею ввиду, как команды CLI, так и структуры NETCONF.
Почему дорогой? Потому что для каждого вендора придётся писать отдельную функцию.
Почему болезненный, потому что в случае CLI появляется приятный интерактив в виде необходимости ответить на какой-то вопрос при вводе команд. А ещё быть всегда в ногу с новыми версиями ПО, где команды могут меняться. Второй подход — очень приятный — мы отправляем на железку конфиг и говорим «хочу так» и топаем ножкой.
Железка прожёвывает сама: валидирует данные, считает дельту и применяет конфиг.
Проблемы со вторым подходом две: мало кто его ещё реализовал и много ещё в эксплуатации старых коробок. А ещё бывают ситуации, когда не стоит так делать.
Control Plane сетевые коробок всё же не резиновый и если нужно будет раз в 7 минут считать дифф тысяч на 30 строк, могут быть серьёзные проблемы. Но до них ещё надо дорасти.
И вот операция replace очень со вторым подходом помогает. Хотя и понимают её вендоры немного по-разному. Хуавэй, например, считает, что в некоторых случаях для этого надо сначала удалить секцию, а потом создать её заново. Кроме просто возможности заменить кусок конфигурации хотелось бы тут иметь ещё независимость от порядка конфигурации. Тот же Хуавэй требует, например, чтобы политики маршрутизации были созданы раньше, чем они будут использованы на пирах.
 Но это всего лишь интерфейсы. Ни один из них не регламентируют, какие данные в них надо передавать.
Но это всего лишь интерфейсы. Ни один из них не регламентируют, какие данные в них надо передавать.
И это на сегодняшний день самый болезненный вопрос.
Если транспорт и формат данных стандартизированы, то с моделью данных полный швах. Тут кто во что горазд. В общем-то ситуация с CLI никуда не делась, просто это её новое прочтение.
Каждый вендор, который сделал поддержку NETCONF, зашил туда свою модель данных. И, естественно, нельзя просто так взять XML Джунипера и пихнуть его в Циску — будет RPC Error.
Но есть всё же одно качественное отличие — это та самая модель.
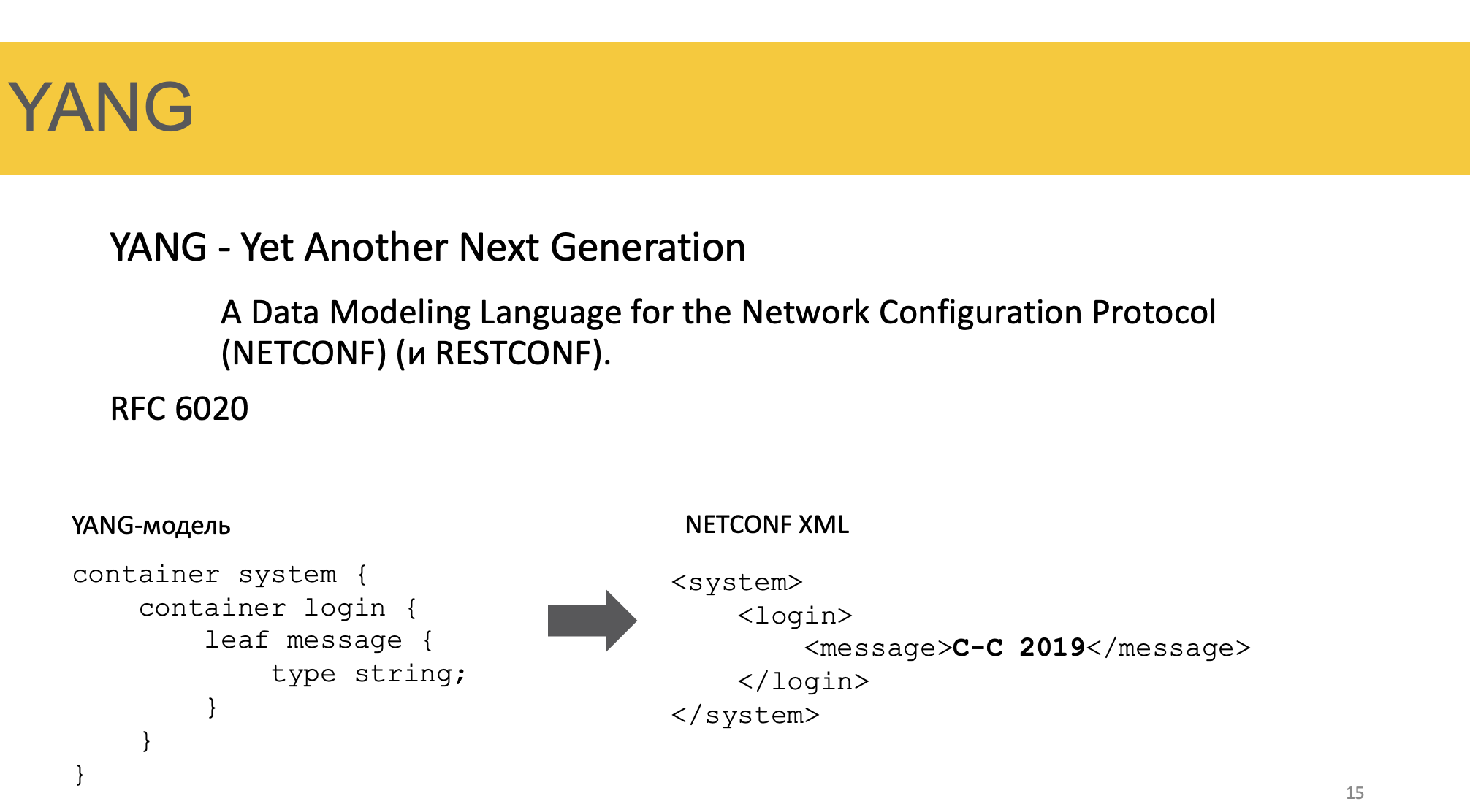
Пусть она и разная у всех, но она существует и её придерживаются. И называется она YANG — Yet Another Next Generation.
Когда появился в 2006 NETCONF, RFC никак не описывал, как должен выглядеть XML — просто XML и всё. И он рисковал стать ещё одним SNMP.
Но в 2010 вдогонку записали YANG — RFC 6020 — он сразу и NETCONF’у и RESTCONF’у предписывал работать с моделями.
Сам по себе YANG — это не готовая модель сетевых сервисов — это только мета-язык описания моделей.
Она не диктует, какие именно ключи должны быть в секции BGP. Она в общем-то не регламентирует и наличие самой секции BGP или любой другой.
То есть это именно язык описания моделей.
А вот конкретная YANG-модель уже описывает, как должен выглядеть XML или JSON, который пуляют в коробку. Соответственно коробка должна тоже понимать эту модель. То есть агент и сервер должны разговаривать на языке одной модели.
На слайде пример как YANG модель перекладывается в NETCONF XML. Внутри контейнера system есть контейнер login, а его leaf-значением является message с типом string.
Справа иерархия XML с уже конкретным значением message.
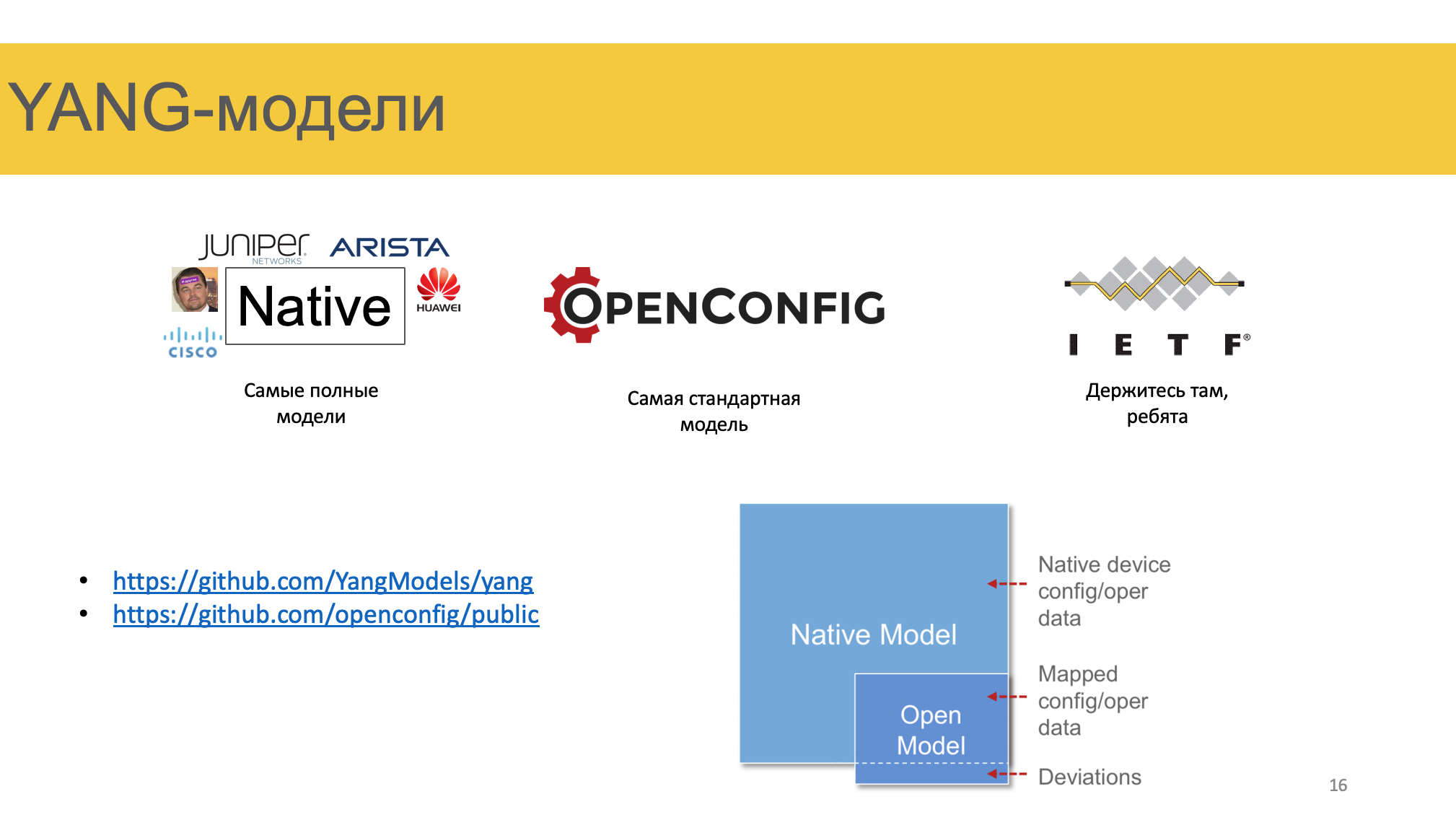 У каждого вендора она своя. Поэтому когда вы генерите конфигурацию, использовать нужно конкретную модель. Она отличается от линейки к линейке и от версии к версии софта.
У каждого вендора она своя. Поэтому когда вы генерите конфигурацию, использовать нужно конкретную модель. Она отличается от линейки к линейке и от версии к версии софта.
В этом репозитории выложены модели некоторых вендоров. Не дам руку на отсечение, что они все актуальны, а скорее даже наоборот.
То есть всё ещё работая с многовендорной сетью, придётся поддерживать несколько моделей, а соответственно в платформе автоматизации иметь разные драйверы.
Чем это качественно отличается от того, чтобы накрафтить CLI или NETCONF RPC?
Тем, что мы, во-первых, больше не думаем о том, как должен выглядеть конечный XML, во-вторых, разговариваем с коробкой на одном языке, в-третьих, наши данные уже провалидированы на агенте. Не нужно сгенерировав конфиг, отправлять его в железку и молиться, чтобы он с первого раза сработал.
Со всех сторон красота. И давайте ещё ведро мёда опрокинем в эту бочку.
IETF работает над стандартизацией модели. Ребята там не очень мотивированные, поэтому модель скупая, а дела идут медленно. Оно в целом и понятно, вендорам эта стандартизации ни с какой стороны не интересна. Но с 2015-го года набирает обороты открытый проект OpenConfig. Google, Netflix, AT&T, Facebook и ещё плеяда крупных компаний поняли, что ждать IETF нет мочи, инструменты нужны сейчас и начали сами на гитхабе составлять ту самую стандартную модель сетевых сервисов. И вендорам с этим приходится считаться. Например, Джунипер и Циска заявляют о его поддержке.
Теперь до дёгтя. Есть и проблемы — и они не из разряда закостенелые сетевики не хотят разбираться в новых штуках.
Самый серьёзный недостаток стандартных моделей сегодня в том, что всех пытаются уложить в одно прокрустово ложе. Разные производители сильно по-разному реализуют настройку и поведение протоколов.
Например, Juniper без директивы advertise-peer-as не анонсирует маршруты BGP-пиру, если в AS-Path уже есть его AS. Больше так не делает никто.
Или в том же джунипере в политике маршрутизации можно в качестве условия указать другую политику, создавая таким способом иерархию, а на хуавэе — нельзя.
А на хуавее в свою очередь есть дефолтные приоритеты — сначала RSVP, потом LDP, потом Plain IP. И существует хитрая команда в режиме глобальной конфигурации, с помощью которой можно поменять поведение. На джунипере это делается через таблицы, риб-группы и политики.
В общем пока складывается такая ситуация, что есть стандартная модель, которая описывает базовые вещи, общие для всех, а есть модули дополнения и отклонения — augmentation и deviation.
Типа вот тебе IP-интерфейсы, пожалуйста, а хочешь DHCPv6 Relay, ну извините — вот вам Native — может там поддерживается.
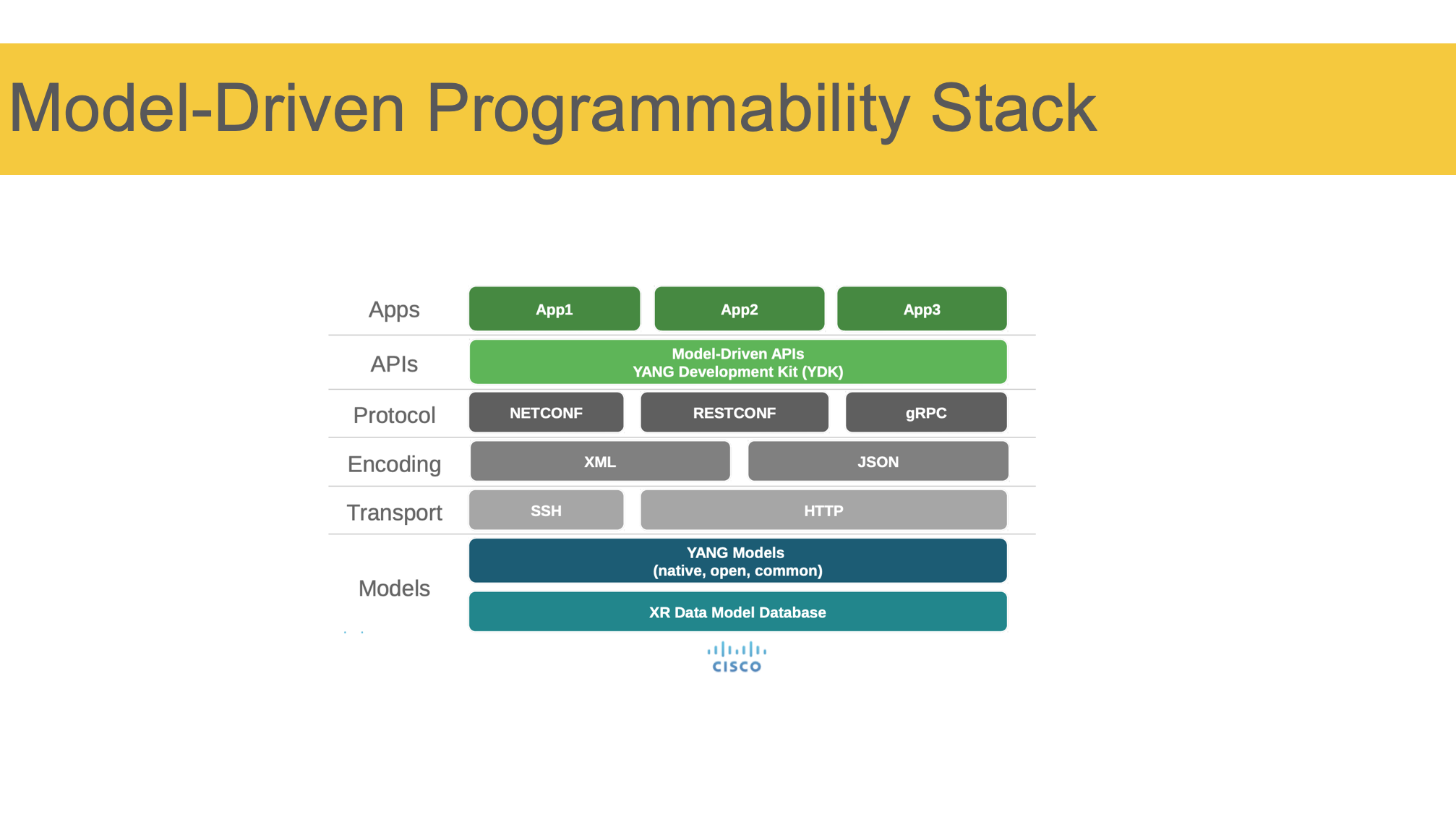 Вот так выглядит стек технологий, который лежит в основе автоматизации сети на основе моделей. Картинка тиснута мной с одной из презентаций циско, поэтому можно считать это видением циско. Хотя поспорить здесь можно разве что с двумя строчками.
Вот так выглядит стек технологий, который лежит в основе автоматизации сети на основе моделей. Картинка тиснута мной с одной из презентаций циско, поэтому можно считать это видением циско. Хотя поспорить здесь можно разве что с двумя строчками.
Сверху вниз — у нас есть приложения, работающие с сетью. Это может быть как целая платформа версионирования конфигурации, так и очень простая штука, которая, например, влан на порту дёргает, или забирает телеметрию.
Приложение идёт в API сети, который в этом стеке представлен YDK — и тут как раз могут быть альтернативы. API, грубо говоря, здесь — это набор ендпоинтов и методов, чего можно сделать с сетью.
Далее у нас есть плеяда протоколов, через которые система может взаимодействовать с коробкой в Machine-to-Machine режиме. По понятным причинам тут нет CLI.
Далее перечислены форматы данных, в которых можно представлять изначальные API вызовы и ответ.
Соответственно, транспорт — SSH/HTTP.
И на стороне коробки данные в формате XML/JSON должны быть разобраны согласно той же модели, что была использована в API.
 Теперь действительно инструменты. Поскольку мы сегодня не совсем про этот стек, а про вообще подходы, то и инструменты будут разного характера.
Теперь действительно инструменты. Поскольку мы сегодня не совсем про этот стек, а про вообще подходы, то и инструменты будут разного характера.
Как уже сказал выше, отбрасываем исключительно вендорские.
И начнём с самых простых.
Замечу, что стандартом де-факто в области сетевой автоматизации на сегодня стал Питон. И большинство библиотек написано для него. Есть, конечно и много проектов на Го, на плюсах, но всё же Питон тут с большим отрывом.
Jinja2
 Это то, что позволит скрафтить что угодно.
Это то, что позволит скрафтить что угодно.
Составляем словарь переменных, описываем конфиг с помощью шаблонов джинджи. Натравливаем в скрипте одно на другое — на выходе получаем текст конфигурации.
Например, из IPAM-системы мы взяли IP-адреса, hostname и локацию и на основе вот такого темплейта сренедерили вот такой конфиг.
Netmiko
 Это библиотека на основе paramiko, которая позволяет взаимодействовать с сетевыми устройствами по SSH.
Это библиотека на основе paramiko, которая позволяет взаимодействовать с сетевыми устройствами по SSH.
Создаём подключение, отправляем в него команды, получаем ответ. Работаем.
TextFSM
TextFSM позволит удобно распарсить текстовые результаты.
Ncclient
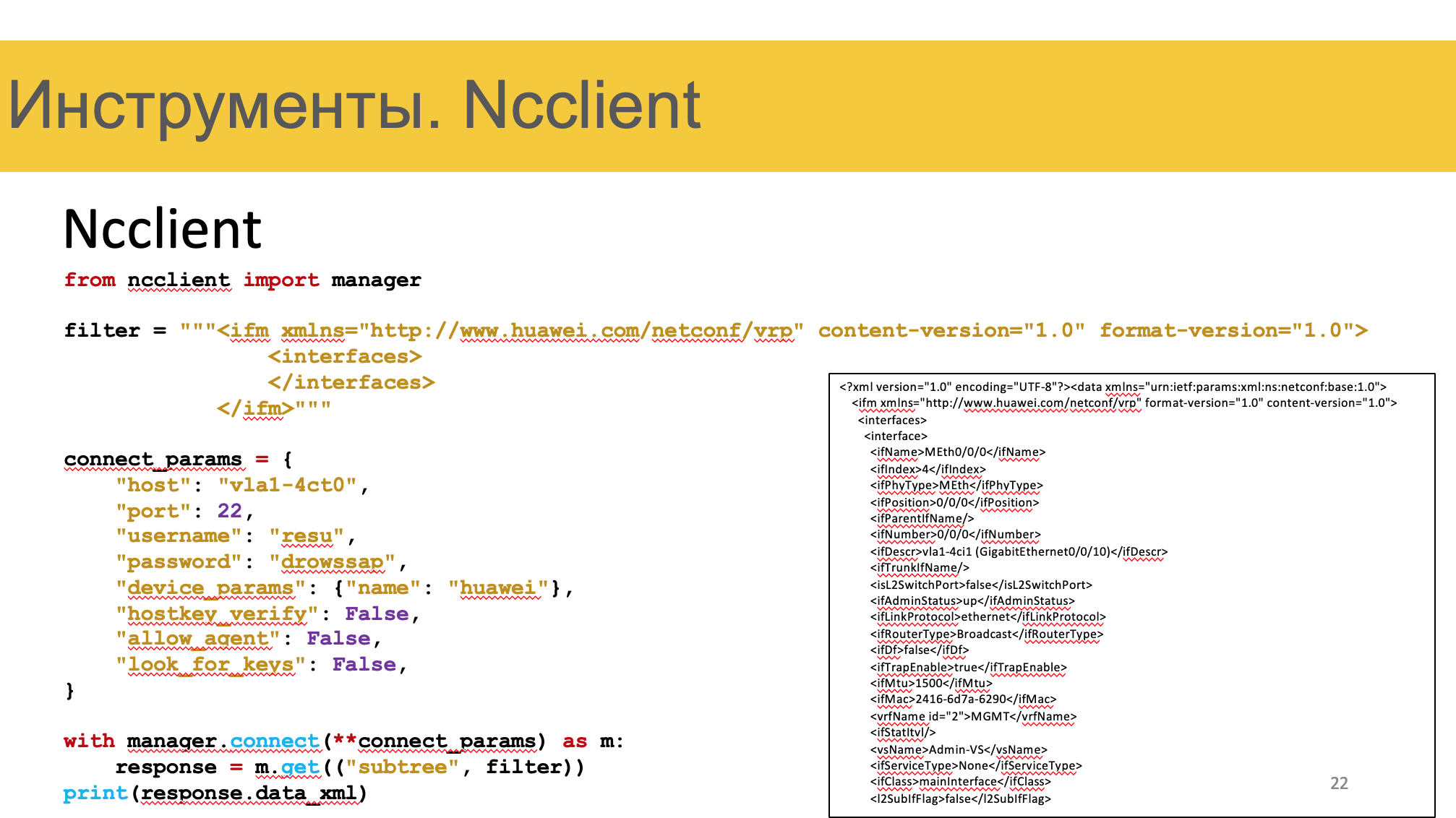 Ncclient — питоновская библиотека для работы через NETCONF.
Ncclient — питоновская библиотека для работы через NETCONF.
Открывает SSH-подключение, вызывает под систему NETCONF, отправляет RPC, возвращает ответ.
С помощью этих инструментов можно и самому сделать систему деплоймента конфигурации. Причём от совсем простенькой до полноценной платформы — это же голый Питон.
Ansible
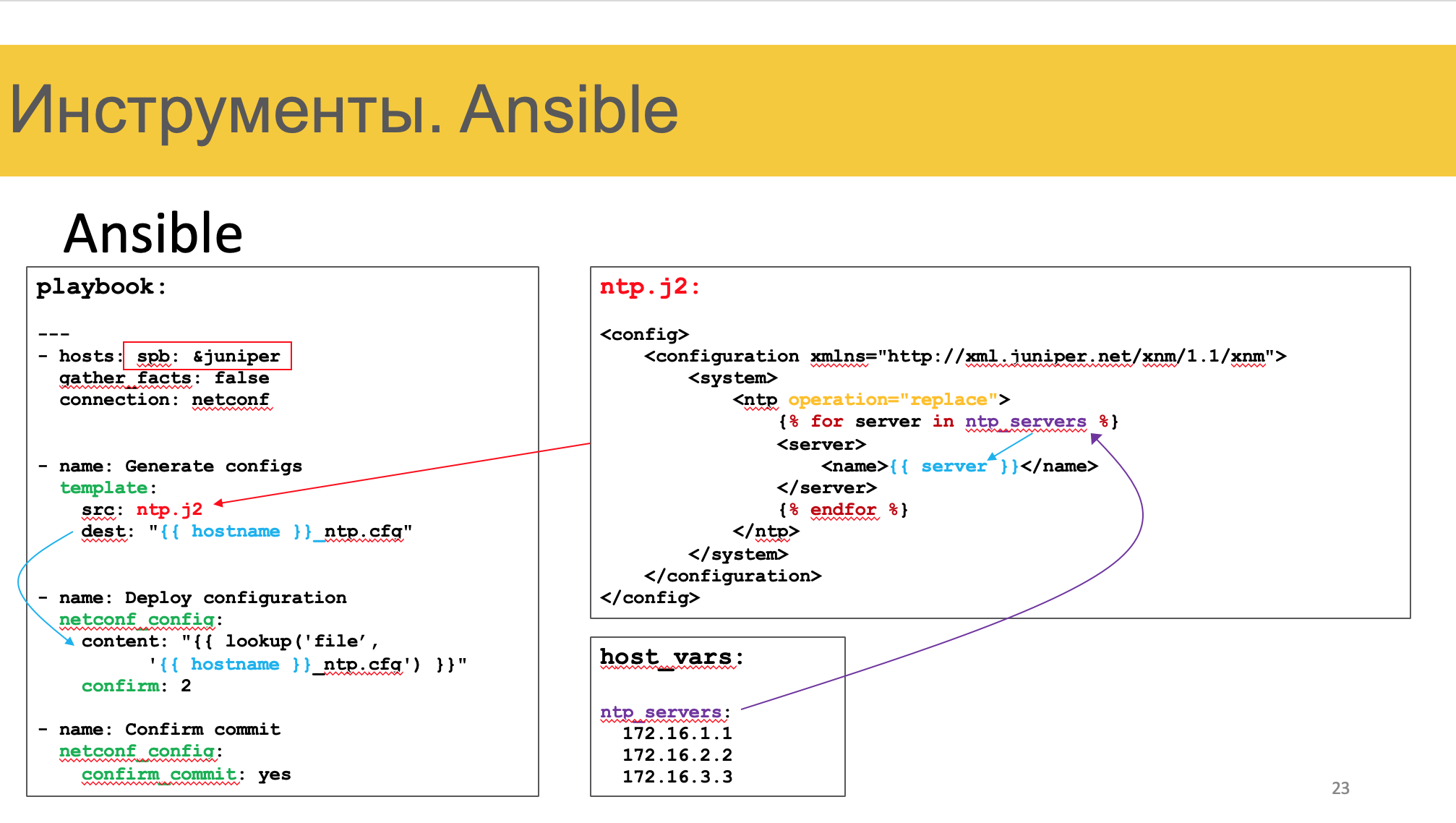 Бессменный Ansible, который позволит раскатить что угодно, куда угодно.
Бессменный Ansible, который позволит раскатить что угодно, куда угодно.
Есть три вещи, которые выгодно выделяют ансибл как стартовый тул.
1) Отсутствие агента на конечных хостах. Можно просто использовать SSH или Netconf, чтобы отправить туда что угодно.
2) Богатая и гибкая системы инвентаризации и хранения переменных
3) Тьма написанных модулей для работы с сетевым железом. Идемпотетнтность
Используя различные модули, мы можем сделать например так.
Для всех устройств Джунипер с ролью ТОР в локации Санкт-Петербург.
— Используя модуль template, сгенерировать файл конфигурации в формате XML на основе переменных и шаблонов
— Используя модуль netconf_config, отправить текст из файла на устройство.
— Сделать commit confirm
— Сделать commit
И воа-ля.
То есть Ансибль забирает здесь на себя все сложности по тому, чтобы определить список девайсов, для каждого из них выбрать правильный шаблон (джунипер, хуавэй, тор, спайн итд), пройтись по всем файлам переменных, собрать словарь с ними, нагенерить конфигов и пульнуть их в железо.
Вопрос только в том, что нужно составлять инвентарник и поддерживать актуальные файлы переменных — задача тоже не из тривиальных. Сейчас я про неё не буду рассказывать, но в статьях посвящу время.
Ансибл весьма хорош, чтобы начать и поддерживать сети, в общем-то почти любого размера. Но чем больше им пользуешься, тем больше встречаешь вещей, которых, скажем, хотелось бы избежать, сделать иначе или типа того.
Одновременно с ансиблом сосуществует Napalm. Хотя его сложно (невозможно) назвать системой деплоймента.
Ещё одна система деплоймента — это Salt. Есть умельцы, которые приспособляют её и к сети. Но вообще искоробки у неё зачаточные лишь к этому способности. Salt как раз может использовать Napalm для работы с сетью.
Соответственно, страдая от его ограниченности.
YDK
Ну и на сладкое, это YDK. 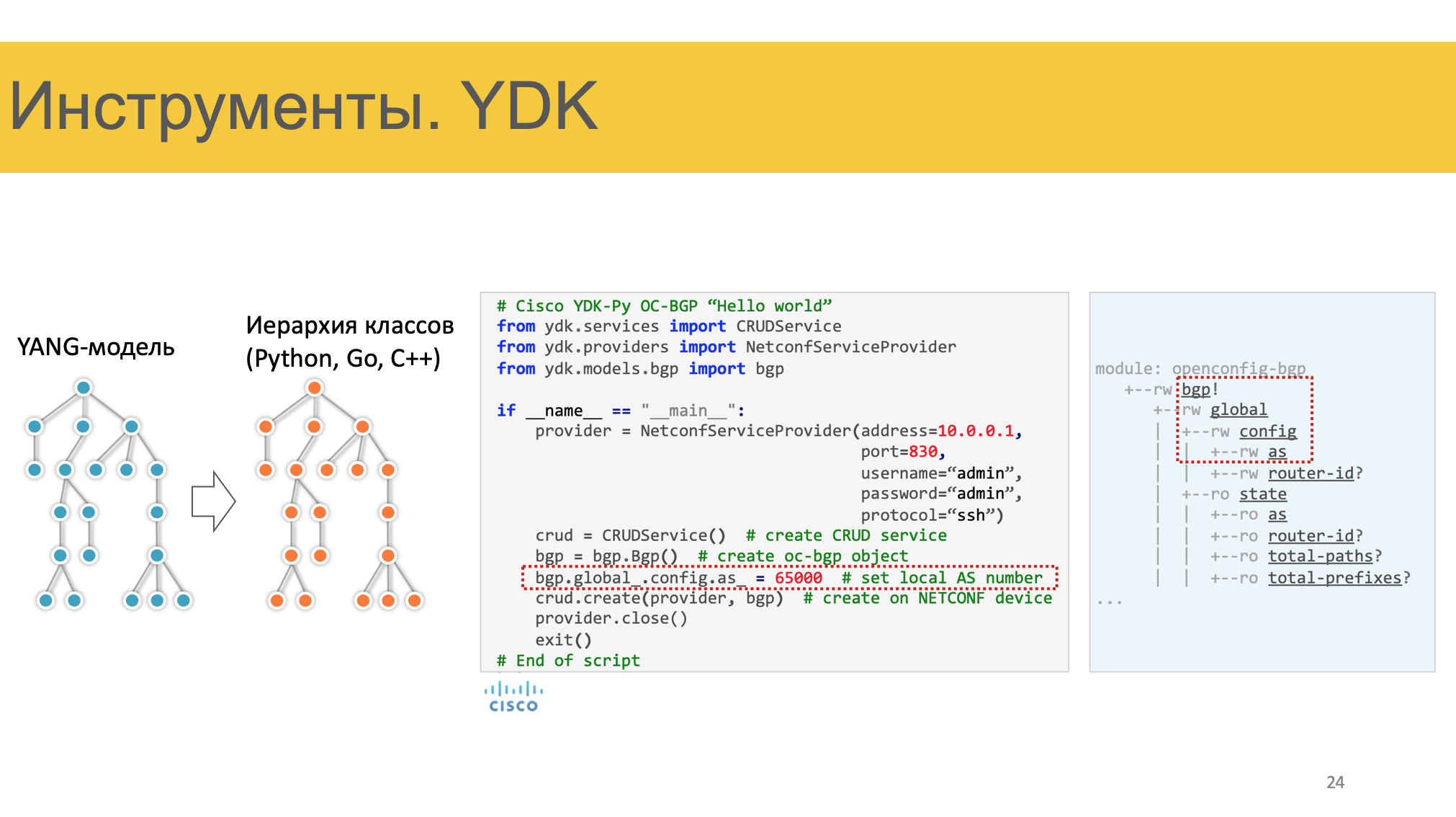 Это набор библиотек, который позволяет преобразовать YANG-модель в иерархию классов Питона/Го/плюсов, работать с ними в привычной форме, а их уже сериализовать в необходимый формат — XML, JSON, бинарный. На слайде пример применения.
Это набор библиотек, который позволяет преобразовать YANG-модель в иерархию классов Питона/Го/плюсов, работать с ними в привычной форме, а их уже сериализовать в необходимый формат — XML, JSON, бинарный. На слайде пример применения.
В общем, к цели нам тут идти ещё долгие и долгие годы. Но это не останавливает нас от того, чтобы вырабатывать практики автоматизации сегодня. Но это уже не умещается в рамки доклада. Об этом я буду писать в статьях.
 470
470
 11278
11278
 0
0
Ещё статьи


0 коментариев