





MPLS. Удачные примеры неудачных конфигураций
 85
85

 22376
22376
 8
8



Статья опубликована на телекомзе.
===================
Немного магии и обычный наш любимый понятный IP превращается в MPLS. Поначалу чуждый нам с его коммутаией на основе меток, LSP, LDP и пугающим Traffic Engineering. Этот мир кажется удивительным, незнакомым, ну как!!! казался. !!!!.. LDP тут прокладывает кратчайшие тропы, высокоскоростные TE-Туннели пронзают сеть в поисках лучших условий. И неопытные доморощенные инженеры начинают в этом мире вести себя как дикари. Не ведая, что творят, они бросаются настраивать оборудование, включают MPLS, прописывают route target и route distinguisher и после этого рождаются замысловатые труднодиагностируемые петли, потери пакетов, проблемы с маршрутизацией.
Позже, в своём цикле «Сети для самых маленьких» я обязательно опишу всё это в подробностях. А сейчас я бы хотел привести несколько интересных проблем из жизни, не ударяясь в теоретические путешествия.
Otpoin C
Inter-AS Option C — самый гибкий и масштабируемый способ передачи VPN между различным Автономными Системами. При добавлении нового VPN, вам не нужно настраивать ни ASBR, ни Route Reflector’ы — маршрутная информация автоматически и беспрепятственно распространяется между PE устройствами различных AS. Вам достаточно однажды корректно настроить всё и будет маленькое инженерное счастье.
Вот типичная схема работы Option C: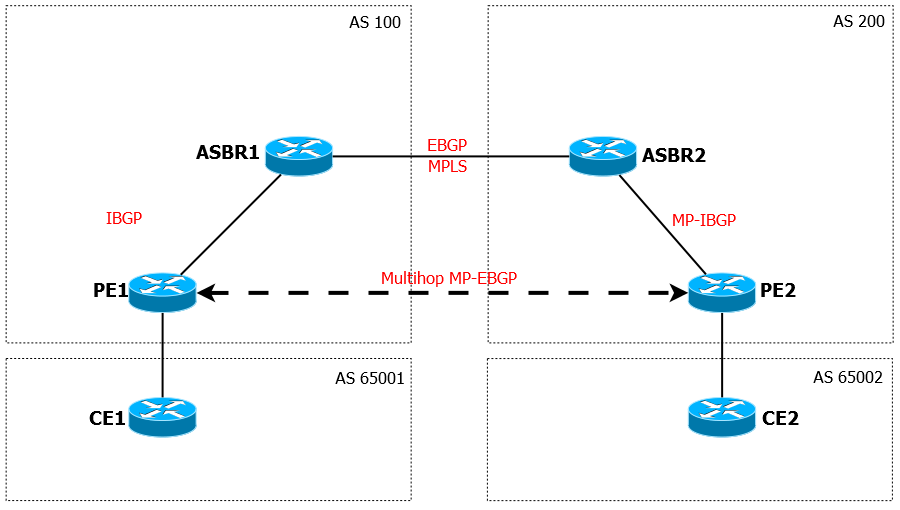 Если объяснять на словах, как это работает, то можно уложиться в пару абзацев:
Если объяснять на словах, как это работает, то можно уложиться в пару абзацев:
Между ASBR’ами устанавливается самая обычная BGP-сессия, а также на интерфейсах включается MPLS. Просто включается безо всяких LDP и RSVP. ASBR’ы не хранят информацию о впнских маршрутах, они только передают информацию от Route Reflector’ов соседу, повесив на него метку MPLS (с помощью политики).
Route-Reflector’ы разных AS устанавливают между собой Multihop MP-EBGP. Multihop, потому что они подключены не напрямую, MP-BGP, чтобы они передавали друг другу маршруты VPN.
Ну а процедура обмена маршрутами между PE и RR как бы не представляет трудности в понимании.
То есть общая схема такая: PE отправил VPN-маршрут RR. RR сохраняет его и должен распространить между своими соседями. Он отправляет этот маршрут на удалённый RR, согласно своей MP-BGP сессии. Физически он, конечно, пойдёт через ASBR, но тому дела нет до каких-то там впнов, он метку навешал, чтобы отправить данные в MPLS линк, и отправил его соседу-ASBR, который передаёт его своему RR. Последний понимает, что это VPN-маршрут и раздаёт его своим клиентам.
Зная суть процессов, здесь сложно настроить что-то неправильно — основная сложность в понимании работы политик, навешивающих метки.
А вот без знания, начинают возникать трудности.
I
Например, один из инженеров, строящих такую сеть, хотел использовать RSVP для обмена метками между RR и ASBR в пределах одной AS, вместо LDP.  В случае LDP — тут всё очень просто — включил его глобально и на портах, и всё работает. В случае RSVP нужно создавать туннельные интерфейсы на обоих концах — уже малое удовольствие. Другая проблема — целостный LSP. В случае LDP обмен информацией о метках между LDP и BGP происходит автоматически и без проблем. RSVP на использованном оборудовании такой функционал не поддерживал ни в каком виде — было необходимо обновление на более позднюю версию ПО.
В случае LDP — тут всё очень просто — включил его глобально и на портах, и всё работает. В случае RSVP нужно создавать туннельные интерфейсы на обоих концах — уже малое удовольствие. Другая проблема — целостный LSP. В случае LDP обмен информацией о метках между LDP и BGP происходит автоматически и без проблем. RSVP на использованном оборудовании такой функционал не поддерживал ни в каком виде — было необходимо обновление на более позднюю версию ПО.
Но самый главный вопрос тут: а зачем? Зачем на этом участке RSVP? Если он нужен для внутренних нужд — да пожалуйста, используйте, а для Option C добавьте LDP. Никто же не запрещает так делать.
II
Другая проблема лежала немного глубже.
Инженер хотел странного. По его задумке ASBR должен был играть роль ещё и PE-устройства, то есть к нему должны были подключаться клиенты. В принципе желание возможное, Лейбниц с ним. Начинаем разбираться. Извращение в том, что у них был свой индивидуальный взглял на Option C. Они подняли MPBGP-сессию между соседними ASBR’ами и от локального ASBR до RR. У локального RR MP-BGP сессия с локальным ASBR и RR от него получает маршруты, которые далее раздаёт клиентам. И была у них проблемка — при определённых условиях маршрутная информация доходила до ASBR, но у клиентов, подключенных к нему, как к PE-устройству, сервиса не было. На лицо проблемы с Data Plane, когда с Control Plane всё в порядке.
Ситуация усложнялась тем, что мы имели доступ только к одной половине, а вторая для нас была чёрным ящиком, о которой было известно только то, что она настроена также.
Долгие попытки убедить, что это не Option C, так строить не стоит и предложения собрать типовую схему, разбивались об один аргумент — «у нас так везде и всё работает».
Какое-то время мы пытались решить проблему, пока мне в голову не пришла одна простая мысль — а что, если инженер просто ошибается, и другая сторона предоставляет ему классический Option C, а он перевернул всё с ног на голову?
После детального разбирательства именно это и выяснилось.
То есть на самом деле на второй стороне всё чётко по схеме: RR поднимает MP-BGP с удалённой стороной, между RR и ASBR голый IBGP, от ASBR в удалённую AS тоже обычный IBGP и они слыхом не слыхивали о том, чтобы применять какие-то более запутанные схемы.
Находчивый MPLS TE
MPLS TE славен своей способностью максимально быстро находить выход из любой ситуации. Для этого у него есть hot/standby, FastReroute, Make-before-brake, которые опираются на RSVP TE и CSPF. LDP тоже вытягивает, но основываясь на информации, полученной от IGP, а он, как известно, может перестраиваться годами сходится долго.
Однако, разумеется, несмотря на всю фантастическую мощь Traffic Engineering, нельзя полагаться на автоматику без понимания, чего вы там делаете.
Ниже пара удачных примеров неудачных конфигураций.
I
Имеем вот такую незамысловатую сеть.  От R1 к R4 построен туннель. В туннеле задан Explicit-path.
От R1 к R4 построен туннель. В туннеле задан Explicit-path.
explicit-path R1R4
next-hop R4 loose
То есть указан только последний хоп с параметром loose, что означает, что RSVP должен самостоятельно с помощью CSPF (Constrained Shortest Path First) построить LSP.
При этом для резервирования на туннельных интерфейсах был настроен FastReroute.
Всё бы и хорошо, всё бы и отлично, если бы не два НО:
НО №1: FRR не является End-to-End защитой туннеля. Это не более чем временная мера, позволяющая обойти падение одного линка/узла. Временная она потому, что как только находится новый постоянный LSP, удовлетворяющий условиям канала, туннель (а соответственно и трафик) тут же переключается на него.
НО №2: Если вы обратили внимание на схему, то обнаружили, что концы туннеля находятся в разных зонах OSPF. Это, между прочим, ключевой момент в отношении CSPF. Ввиду ограничений, накладываемых OSPF TE (или ISIS TE), CSPF работает только в пределах одной зоны OSPF/ISIS. То есть при поставленных условиях End-to-End LSP не может быть построен на основе explicit-path.
В случае нескольких зон рекомендуется в Explicit-path указывать IP-адреса всех ABR на пути LSP с параметром Loose. Таким образом в рамках каждой отдельной зоны CSPF сможет успешно отработать.
II
Ну и на сладенькое свежая проблемка со странными симптомами.
Дана сеть MEN (Metropolitan Area Network), которая обеспечивает транспорт для пользовательских данных до ядра сети:  Периодически на ней возникают небольшие потери пакетов и их неупорядоченная доставка. В качестве устройств доступа здесь выступают 2G Базовые Станции сотового оператора. А они, в силу своей TDM-природы крайне чувствительны к таким событиям — теряется синхронизация и все данные полностью портятся.
Периодически на ней возникают небольшие потери пакетов и их неупорядоченная доставка. В качестве устройств доступа здесь выступают 2G Базовые Станции сотового оператора. А они, в силу своей TDM-природы крайне чувствительны к таким событиям — теряется синхронизация и все данные полностью портятся.
Эмпирически было установлено, что если вручную погасить линк R3<->R6, то ситуация исправляется.
Для инженеров весь этот огромный и важный кусок сети был как чёрный ящик, за которым они наблюдали только с помощью выходных данных — наличие сервиса и картинки из системы мониторинга. То есть понимали, что в сети происходит какая-то чертовщина, которая заставляет её перестраиваться, но жили изо дня в день, сидя на пороховой бочке.
Поэтому проблемой занялся я.
В качестве отправной точки берём данные системы мониторинга. Проверив все подозрительные линки, я выделил интересный участок:
R2<->R4  Очень явно видно, что примерно в 10:30 часть трафика ушла с интерфейса.
Очень явно видно, что примерно в 10:30 часть трафика ушла с интерфейса.
В 11:00 было падение трафика до 0. В 12:00 после скачка всё восстановилось, а примерно в 12:40 снова всё обрушилось, через несколько секунд часть трафика восстановилась, а ещё чуть позже объём резко возрос.
Зная время аварий и место, отправляемся на поиски. Поскольку оборудование провайдерского класса уровня ядра, на карте памяти хранятся подробнейшие логи событий.
Итак, со стороны R4 мы видим следующие сообщения:
Jul 31 2013 10:31:02 R4 ISIS/2/ADJ_CHANGE:OID 1.3.6.1.3.37.2.0.17 The state of IS-IS adjacency changed. (sysInstance=100, sysInstanceofLevel=100, sysLevel=2, sysInstanceofInterface=100, circuit=2, sysInstanceofAdjState=100, ifIndex=2, CircuitIfIndex=6, LspID=[01.01.84.10.40.08.00.00 (hex)], AdjState=1, IfName=E0/0/1)
Jul 31 2013 10:31:02 R4 PIM/2/NBRLOSS:OID 1.3.6.1.4.1.2011.5.25.149.4.0.1 PIM neighbor loss. (NbrIntIndex=6, NbrAddrType=1, NbrAddr=X.X.X.X, NbrUpTime=59443000, NbrIntName=Ethernet0/0/1) …
Jul 31 2013 10:31:02 R4 %%01BFD/6/STACHG_TODWN(l)[187918]:Slot=1;BFD session changed to Down. (SlotNumber=1, Discriminator=8247, Diagnostic=DetectDown, Applications=ISISL2 | PIM | RSVP, ProcessPST=False, BindInterfaceName=Ethernet0/0/1, InterfacePhysicalState=Up, InterfaceProtocolState=Up
Разрушилось соседство по IS-IS и PIM, упала BFD-сессия. Скорее всего внешние причины, проверяем сторону R2:
Jul 31 2013 10:31:02 R2 ISIS/2/ADJ_CHANGE:OID 1.3.6.1.3.37.2.0.17 The state of IS-IS adjacency changed. (sysInstance=100, sysInstanceofLevel=100, sysLevel=2, sysInstanceofInterface=100, circuit=3, sysInstanceofAdjState=100, ifIndex=3, CircuitIfIndex=7, LspID=[01.01.84.10.40.09.00.00 (hex)], AdjState=1, IfName=E0/0/0)
Jul 31 2013 10:31:02 R2 SRM_BASE/2/PORTPHYSICALDOWN: OID 1.3.6.1.4.1.2011.5.25.129.2.5.1 Physical state of the port changed to down. (EntityPhysicalIndex=16842757, BaseTrapSeverity=3, BaseTrapProbableCause=74752, BaseTrapEventType=5, EntPhysicalName=«Ethernet0/0/0»)
…
Jul 31 2013 10:31:02 R2 %%01PHY/4/PHY_STATUS_UP2DOWN(l)[167052]:Slot=1;GigabitEthernet0/0/0 change status to down.
…
Jul 31 2013 10:31:09 R2 %%01SRM/2/NODEFAULT(l)[167067]:Slot=1;PIC0 of LPU0 is failed, perhaps RXPowLowAlarm of XFP0 ALARM is abnormal. (Reason=«L2XXN0 XFP RX power low alarm, Current Rxpower is -18.76dBm. „)
Падение IS-IS и интерфейса Ethernet0/0/0.
Чуть позже видно сообщение о том, что SFP-глазок видит очень слабый сигнал лазера.
Почему сначала падение, потом сообщение о слабом сигнале спросите вы? Потому что по-разному отрабатывают планировщики — модуль, следящий за состоянием сигнала, имеет больший таймер.
Собственно, ситуация ясна, как божий день — повреждение одного из оптических волокон. Интерфейс/BFD периодически дёргается, перестраивается таблица маршрутизации, перестраиваются LSP. Решение — устранить проблему с оптической линией.
Природная лень хочет поставить на этом точку, природное же любопытство тыкает в бок острым локтём: “Ну, неужели не интересно, неужели сдашься? Почему не весь трафик возвращается назад? Откуда потери?»
«Ага, щаз» Сдамся!»
Действительно же, согласно картинке на основной линк возвращается меньше половины трафика, куда делась другая часть? Это становится ясно из ещё одного графика:  Там убыло, тут прибыло, вот они — потерянные 40 Мбит. Почему трафик пошёл не оптимальным путём, почему он не вернулся на восстановившийся линк, откуда идут потери, почему выключение линка R3<->R6 ведёт к возвращению трафика на круги своя?
Там убыло, тут прибыло, вот они — потерянные 40 Мбит. Почему трафик пошёл не оптимальным путём, почему он не вернулся на восстановившийся линк, откуда идут потери, почему выключение линка R3<->R6 ведёт к возвращению трафика на круги своя?
На эти вопросы не ответить без изучения конфигурации.
Вот так выглядят туннельные интерфейсы:
interface Tunnel0/0/14
ip address unnumbered interface LoopBack0
tunnel-protocol mpls te
destination 4.4.4.4
mpls te tunnel-id 14
mpls te record-route label
mpls te path explicit-path EP_R1R4
mpls te fast-reroute
mpls te backup hot-standby wtr 60
mpls te backup frr-in-use
mpls te reserved-for-binding
mpls te commit
statistic enable
То есть у нас активирован Fast Reroute, включен функционал hot-standby и используется make-before-break (команда frr-in-use). Кроме того, есть explicit-path, выглядящий так:
explicit-path EP_R1R4
next hop 10.0.12.2
Для начала разберёмся, как это работает пока всё хорошо.
1) Explicit-path намекает, что LSP нужно строить через R2 — это обязательное условие. Поэтому трассировка по туннелю выглядит так:  2) FRR подготовил вспомогательный туннель, который будет использоваться, если упадёт основной:
2) FRR подготовил вспомогательный туннель, который будет использоваться, если упадёт основной: 
 Но трафик, по нему, конечно, не идёт. Всё замечательно.
Но трафик, по нему, конечно, не идёт. Всё замечательно.
Тем временем монтажники проверяли/меняли оптику, и инженеры успели заметить, что после разрыва линии, сеть работает стабильно ещё в течение примерно минуты, а затем снова всё рушится в тар-тарары. Новые детали.
На следующий день собираю тестовый стенд в симуляторе и проверяю родившуюся в голове теорию.
Что происходит после обрыва линии?
1) Обе стороны детектируют разрыв основного LSP, в бой вступает FRR. Он здесь прекрасно отрабатывает:  Обратите внимание на next-hop — это уже R3. Трафик пошёл по резервному туннелю Tunnel0/0/16384
Обратите внимание на next-hop — это уже R3. Трафик пошёл по резервному туннелю Tunnel0/0/16384
2) Какое-то время трафик идёт по резервному туннелю, подготовленному FRR, но мы помним, что это лишь временная мера, а RSVP в этот момент судорожно ищет новые пути до удалённого конца. С сервисами пока всё в порядке. Скорее всего, никто даже не заметил, что была проблема — время переключения около 50 мс.
3) В чём особенность данной ситуации? У нас есть чёткое правило в explixit-path:
explicit-path EP_R1R4 next hop 10.0.12.2
Фактически оно означает, что бы ни случилось в этом сумасшедшем мире, не сдавайся! Пытайся построить LSP только через R2.
И если у R4 ну никак это не получалось — у него соответствующий интерфейс находится в состоянии Down, то R1 довольно быстро находит окольный путь: Что имеем: R4 не может перестроиться и использует туннель Tunnel0/0/16384 на постоянной основе — трафик идёт кратчайшим путём.
Что имеем: R4 не может перестроиться и использует туннель Tunnel0/0/16384 на постоянной основе — трафик идёт кратчайшим путём.  Туннель R1<->R4 идёт через R1<->R2<->R5<->R6<->R3<->R4.
Туннель R1<->R4 идёт через R1<->R2<->R5<->R6<->R3<->R4.  Как посылка из Китая в Хабаровск через сортировочный пункт в Москве. При этом на реальной сети там были и не самого лучшего качества линии, которые и вызывали неупорядоченность доставки пакетов.
Как посылка из Китая в Хабаровск через сортировочный пункт в Москве. При этом на реальной сети там были и не самого лучшего качества линии, которые и вызывали неупорядоченность доставки пакетов.
Проверили всё это ночью — бинго!
Теперь ответим на свои же вопросы.
В1: Почему трафик пошёл не оптимальным путём?
О1: explicit-path обязывает в качестве next-hop использовать R2
В2: Почему больше минуты отработало всё нормально без потерь?
О2: В течение этой минуты работал туннель FRR и строился альтернативный LSP для него. Так же тикал таймер WTR (Wait To Restore). Как только он истёк, происходит переключение на новый путь и, соответственно, начинаются проблемы.
B3: Почему не весь трафик вернулся на восстановившийся линк
О3: Интересный вопрос.
Проследим хронологию событий: 
 В 10:30 упал интерфейс (статистика сглажена, поэтому обвала не видно). Трафик ушёл с линка R4<->R2, но он появился на R4<->R3.
В 10:30 упал интерфейс (статистика сглажена, поэтому обвала не видно). Трафик ушёл с линка R4<->R2, но он появился на R4<->R3.
И так продолжалось до 12 часов, пока на R3 не выключили интерфейс в сторону R6.
Что при этом произошло?
Во-первых перестроился туннель R1<->R4, поэтому восстановился прежний объём трафика.
Во-вторых, поскольку интерфейс ушёл в down, сработал FRR и весь трафик от R3 в сторону R6 перенаправился на R4. Поэтому на одной картинке видно провал, а на другой напротив всплеск. Потом интерфейс включили и R1<->R4 остался ходить через R2, а трафик от R3 вернулся на R3<->R6.
Далее в 12:40 ситуация повторилась, но, выключив интерфейс R3-R6, его больше не включали, поэтому путь трафика от R3 пролегал через R4.
Так почему же часть трафика оставалась на линии в сторону R3. Почему он тоже не перетёк?
Вернулся на основной канал чистый IP-трафик, который при движении руководствуется таблицей маршрутизации. В MPLS TE-туннелях же трафик движется по LSP. А при конфигурации заказчика LSP раз построившись уже не поменяется, пока не будет разрушен, даже если есть более короткие и быстрые пути.
То есть пока чистый IP шёл через R2, трафик, «забинденный» на туннель, шёл по длинному пути через R3 и всю остальную сеть.
В4: Почему после выключения интерфейса между R3 и R6 проблема решилась?
О4: Теперь это уже очевидно — разрушается действующий LSP и RSVP приходится искать новый путь. Он обнаруживает, что R1<->R2<->R4 уже вполне работоспособен и выбирает его для туннеля.
Как решить проблему?
В этом нет ничего сложного — наша проблема известна и заключается в строгой привязке explicit-path к next-hop R3. FRR уже работает как надо.
То есть всё, что нам нужно сделать, настроить правильный hot/standby
Сначала создаём пару новых explicit-path — основной и резервный:
explicit-path EP_R1R4_main
next hop 10.0.12.2
explicit-path EP_R1R4_backup
next hop 10.0.13.3
Теперь указываем их в настройках TE-туннеля:
interface Tunnel0/0/14
ip address unnumbered interface LoopBack0
tunnel-protocol mpls te
destination 4.4.4.4
mpls te tunnel-id 14
mpls te record-route label
mpls te path explicit-path EP_R1R4_main
mpls te path explicit-path EP_R1R4_backup secondary
mpls te fast-reroute
mpls te backup hot-standby wtr 60
mpls te backup frr-in-use
mpls te reserved-for-binding
mpls te commit
statistic enable
В конце не забываем сделать mpls te commit. Пока этого не сделаем — настройки не применятся.
Естественно, аналогичные настройки нужны с обратной стороны.
На самом деле, что там с обратной стороны не так уж важно, потому что туннель — это однонаправленный канал, то есть он управляет только исходящим трафиком.
После таких настроек всё работает изумительно предсказуемо, без потерь сервиса в случае падения любого из линков.
Вот нормальное состояние hot/stanbdy (используется Primary LSP):  А вот в случае падения линка R2<->R4:
А вот в случае падения линка R2<->R4: 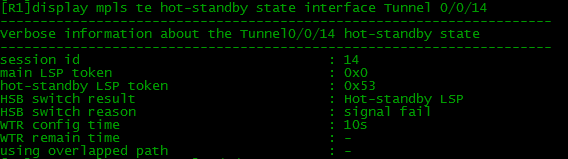 Мол, «сигнализация поломалась и потому мы переключились на Hot-Standby LSP, хозяин».
Мол, «сигнализация поломалась и потому мы переключились на Hot-Standby LSP, хозяин».
Послесловие
Можно бесконечно повторять, что если есть проблема, в первую очередь ищите причину в себе, но редко кто эту фразу слышит. Причём независимо то того, базовый это слой знаний или какая-то сложная технология.
 85
85
 22376
22376
 8
8
Ещё статьи


8 коментариев
Привет.
1. Технически, вы правы, но в условии задачи на этом акцент можно и не делать — важно, чтобы человек понял суть.
2. Предлагается что-то странное. Не знаю, как у него это сработало.
И еще…
«Между ASBR’ами устанавливается самая обычная BGP-сессия»
Если самая обычная, то какими префиксами ASBR’ы обмениваются?
По-моему все-так должна быть необычная BGP+label сессия — для того, чтобы обменяться метками для своих локальных адресов, которые будут выступать в качестве next-hop’ов для ASBR’ов соседей. Поправьте, если ошибаюсь…
«а также на интерфейсах включается MPLS. Просто включается безо всяких LDP и RSVP»
А не скажете, как включить mpls на интерфейсе роутера с например обычным IOS, не включая на нем LDP/TDP?
Не совсем понятно((( В тексте написано «Route-Reflector’ы разных AS устанавливают между собой Multihop MP-EBGP» и на картинке между PE1 и PE2 изображен MP-EBGP, далее «Ну а процедура обмена маршрутами между PE и RR как бы не представляет трудности в понимании». Какое устройство выступает на данном рисунке в качестве RR?
Router(config)# interface Ethernet#/#
Router(config-if)# mpls ip
К сожалению, не подскажу. Не приходилось настраивать MPLS на циске.
Да, конечно, вы правы. Я имел в виду, что устанавливается сессия для ipv4 family, а не для VPN.
А так да, labeled, плюс применяется дополнительная политика по навешиванию метки на маршруты.
В данном случае за RR взяты PE.
Option C ведь не обязывает вас поднимать сессию между RR — это могут быть любые два маршрутизатора внутри AS. Просто RR — это логично.
А в примере я решил не нагружать топологию лишними устройствами.
Фраза «Ну а процедура обмена маршрутами между PE и RR», возможно, и правда здесь немного непонятна — можно заменить её на «Ну а процедура обмена маршрутами между ASBR и RR» 🙂