





АДСМ2. Дизайн сети
 481
481

 27779
27779
 1
1



В первых двух статьях я поднял вопрос автоматизации и набросал её фреймворк, во второй сделал отступление в виртуализацию сети, как первый подход к автоматизации настройки сервисов.
А теперь пришло время нарисовать схему физической сети.
Если вы не на короткой ноге с устройством сетей датацентров, то я настоятельно рекомендую начать со статьи о них.
Все выпуски АДСМ…
Описанные в этой серии практики должны быть применимы к сети любого типа, любого масштаба с любым многообразием вендоров (нет). Однако нельзя описать универсальный пример применения этих подходов. Поэтому я остановлюсь на современной архитектуре сети ДЦ: Фабрике Клоза.
DCI сделаем на MPLS L3VPN.
Поверх физической сети работает Overlay-сеть с хоста (это может быть VXLAN OpenStack’а или Tungsten Fabric или что угодно другое, что требует от сети только базовой IP-связности).
 В этом случае получится сравнительно простой сценарий для автоматизации, потому что имеем много оборудования, настраивающегося одинаковым образом.
В этом случае получится сравнительно простой сценарий для автоматизации, потому что имеем много оборудования, настраивающегося одинаковым образом.
Мы выберем сферический ДЦ в вакууме:
- Одна версия дизайна везде.
- Два вендора, образующих две плоскости сети.
- Один ДЦ похож на другой как две капли воды.
Содержание
Пусть наш Сервис-Провайдер LAN_DC будет, например, хостить обучающие видео о выживании в застрявших лифтах.
В мегаполисах это пользуется бешенной популярностью, поэтому физических машин надо много.
Сначала я опишу сеть приблизительно такой, какой бы её хотелось видеть. А потом упрощу для лабы.
Физическая топология
Локации
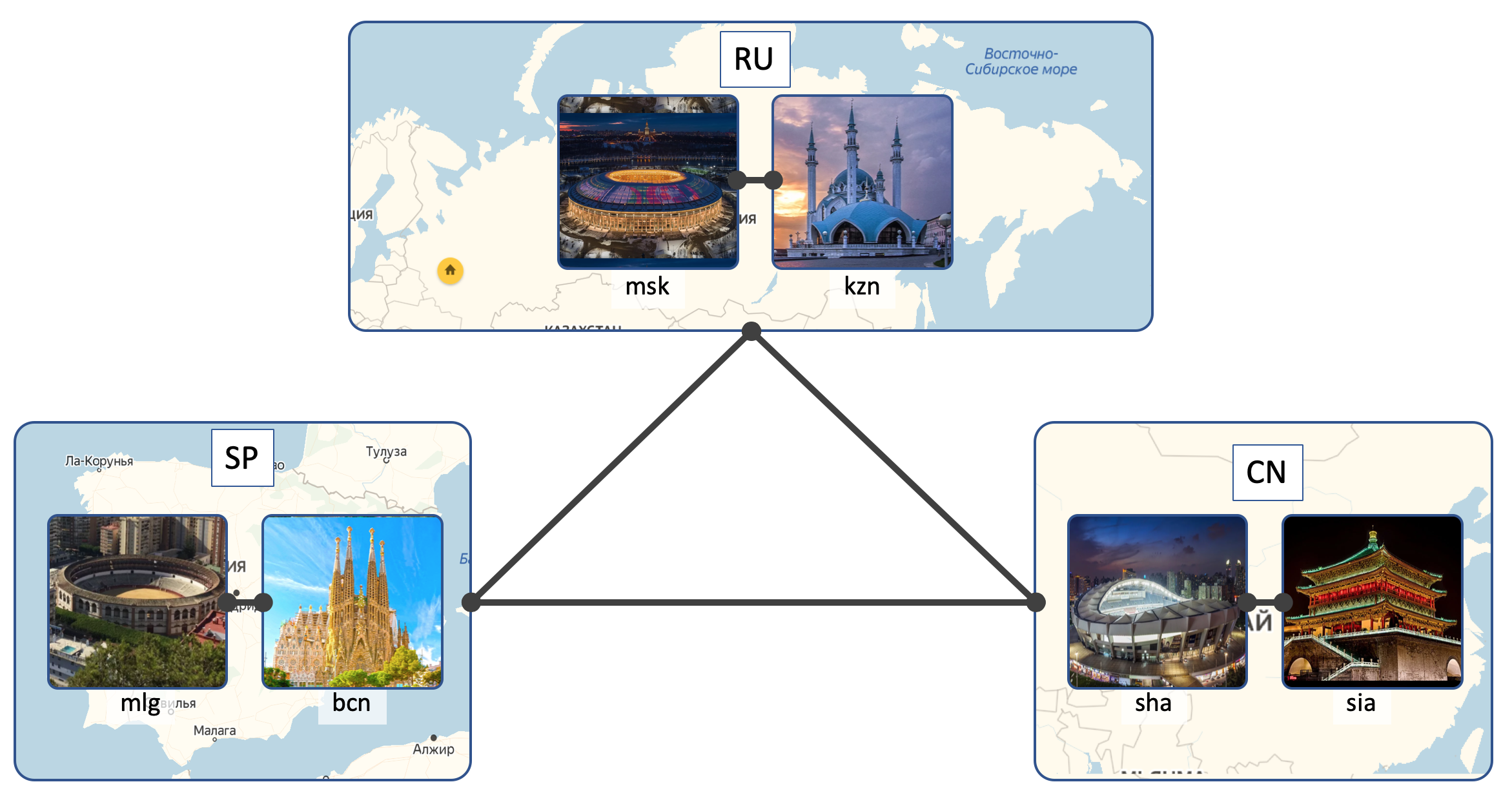
У LAN_DC будет 6 ДЦ:
- Россия (RU):
- Москва (msk)
- Казань (kzn)
- Испания (SP):
- Барселона (bcn)
- Малага (mlg)
- Китай (CN):
- Шанхай (sha)
- Сиань (sia)
Внутри ДЦ (Intra-DC)
Во всех ДЦ идентичные сети внутренней связности, основанные на топологии Клоза.
Что за сети Клоза и почему именно они — в отдельной статье.
В каждом ДЦ по 10 стоек с машинами, они будут нумероваться как A, B, C итд.
В каждой стойке по 30 машин. Они нас интересовать не будут.
Также в каждой стойке стоит коммутатор, к которому подключены все машины — это Top of the Rack switch — ToR или иначе в терминах фабрики Клоза будем называть его Leaf.
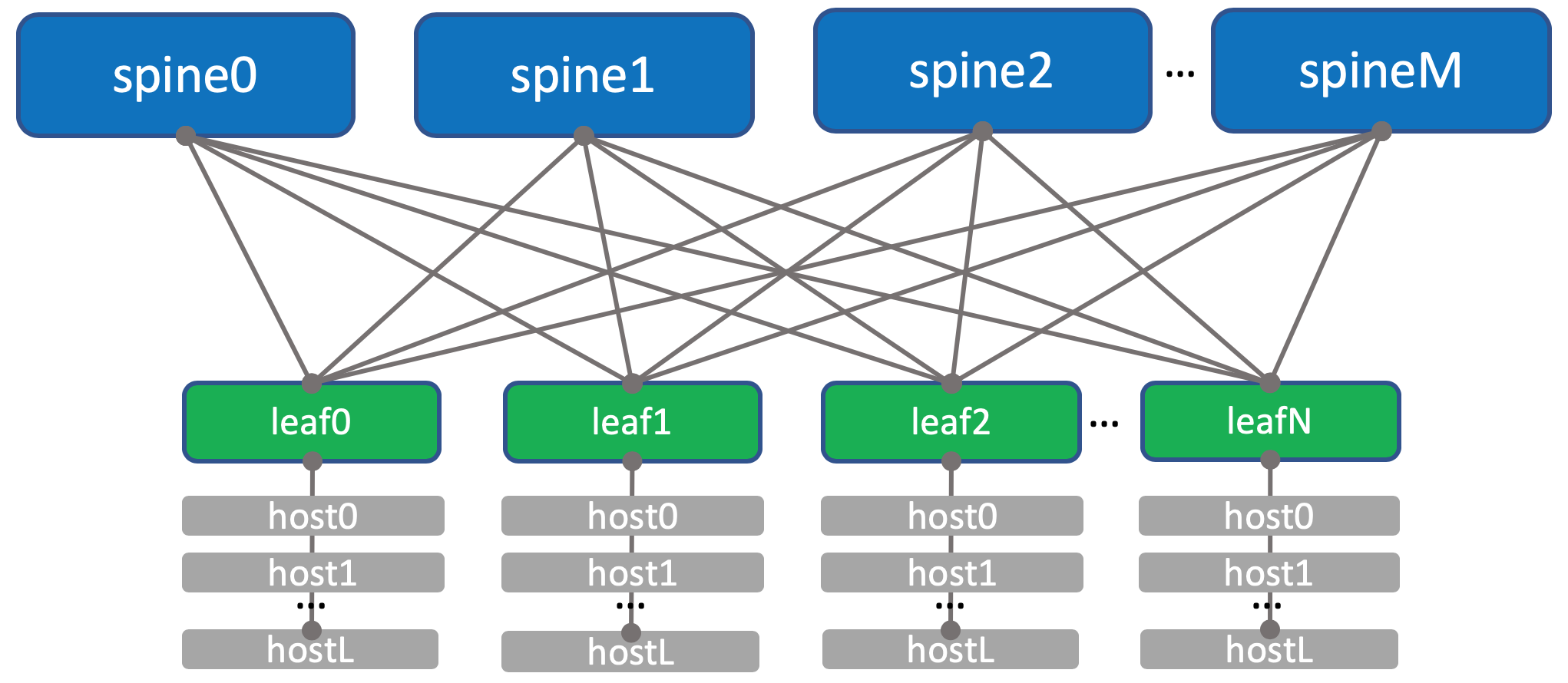 Общая схема фабрики.
Общая схема фабрики.
Именовать их будем XXX-leafY, где XXX — трёхбуквенное сокращение ДЦ, а Y — порядковый номер. Например, kzn-leaf11.
Я в статьях позволю себе достаточно фривольно обращаться терминами Leaf и ToR, как синонимами. Однако нужно помнить, что это не так.
ToR — это коммутатор, установленный в стойке, к которому подключаются машины.
Leaf — это роль устройства в физической сети или свитч первого уровня в терминах топологии Клоза.
То есть Leaf != ToR.
Так Leaf’ом может быть End Of Raw-коммутатор, например.
Однако в рамках этой статьи будем всё же обращаться ими как синонимами.
Каждый ToR-коммутатор в свою очередь соединён с четырьмя вышестоящими агрегирующими коммутаторами — Spine. Под Spine’ы выделено по одной стойке в ДЦ. Именовать будем аналогично: XXX-spineY.
В этой же стойке будет стоять сетевое оборудование для связности между ДЦ — 2 маршрутизатора с MPLS на борту. Но по большому счёту — это те же самые ToR’ы. То есть с точки зрения Spine-коммутаторов не имеет никакого значения обычный там ToR с подключенными машинами или маршрутизатор для DCI — один чёрт форвардить.
Такие специальные ToR’ы называются Edge-leaf. Мы их будем именовать XXX-edgeY.
Выглядеть это будет так.
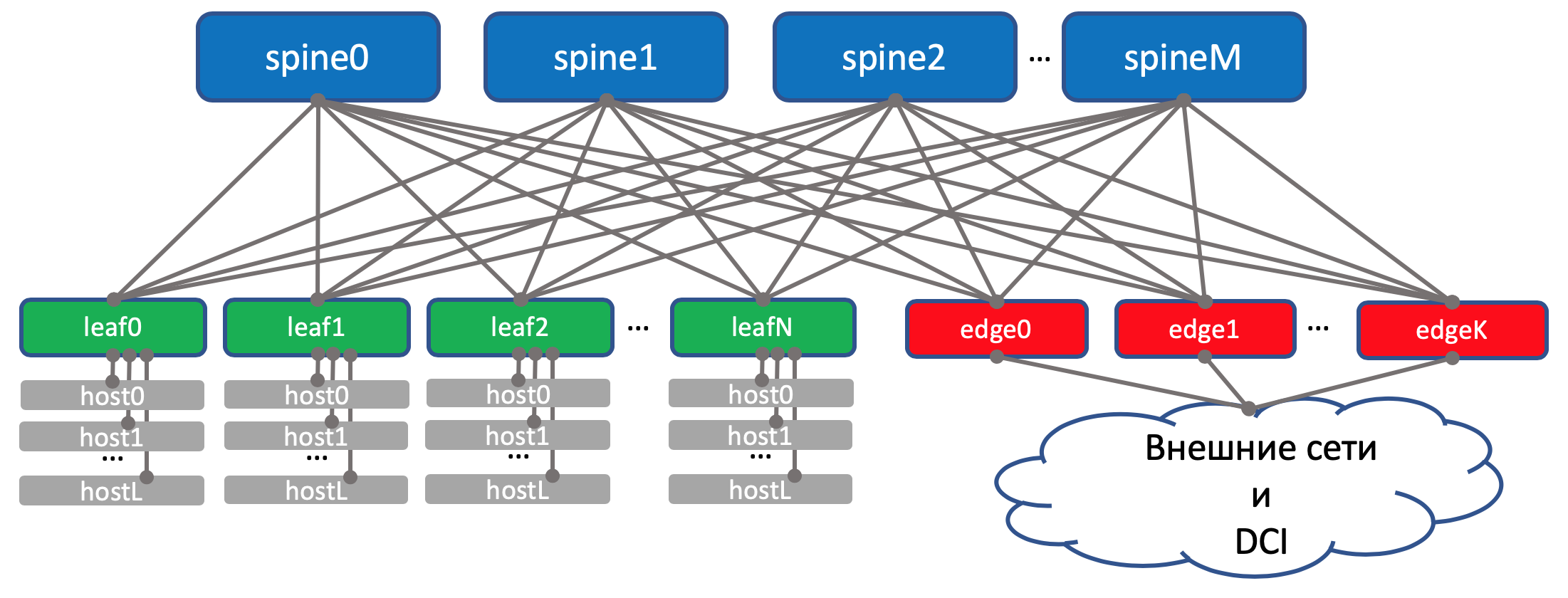 На схеме выше edge и leaf я действительно разместил на одном уровне. Классические трёхуровневые сети приучили нас рассматривать, аплинк (собственно отсюда и термин), как линки вверх. А тут получается «аплинк» DCI идёт обратно вниз, что некоторым немного ломает привычную логику. В случае крупных сетей, когда датацентры делятся ещё на более мелкие единицы — POD‘ы (Point Of Delivery), выделяют отдельные Edge-POD‘ы для DCI и выхода во внешние сети.
На схеме выше edge и leaf я действительно разместил на одном уровне. Классические трёхуровневые сети приучили нас рассматривать, аплинк (собственно отсюда и термин), как линки вверх. А тут получается «аплинк» DCI идёт обратно вниз, что некоторым немного ломает привычную логику. В случае крупных сетей, когда датацентры делятся ещё на более мелкие единицы — POD‘ы (Point Of Delivery), выделяют отдельные Edge-POD‘ы для DCI и выхода во внешние сети.
Для удобства восприятия в дальнейшем я буду всё же рисовать Edge над Spine, при этом мы будем держать в уме, что никакого интеллекта на Spine и отличий при работе с обычными Leaf и с Edge-leaf нет (хотя тут могут быть нюансы, но в целом это так).
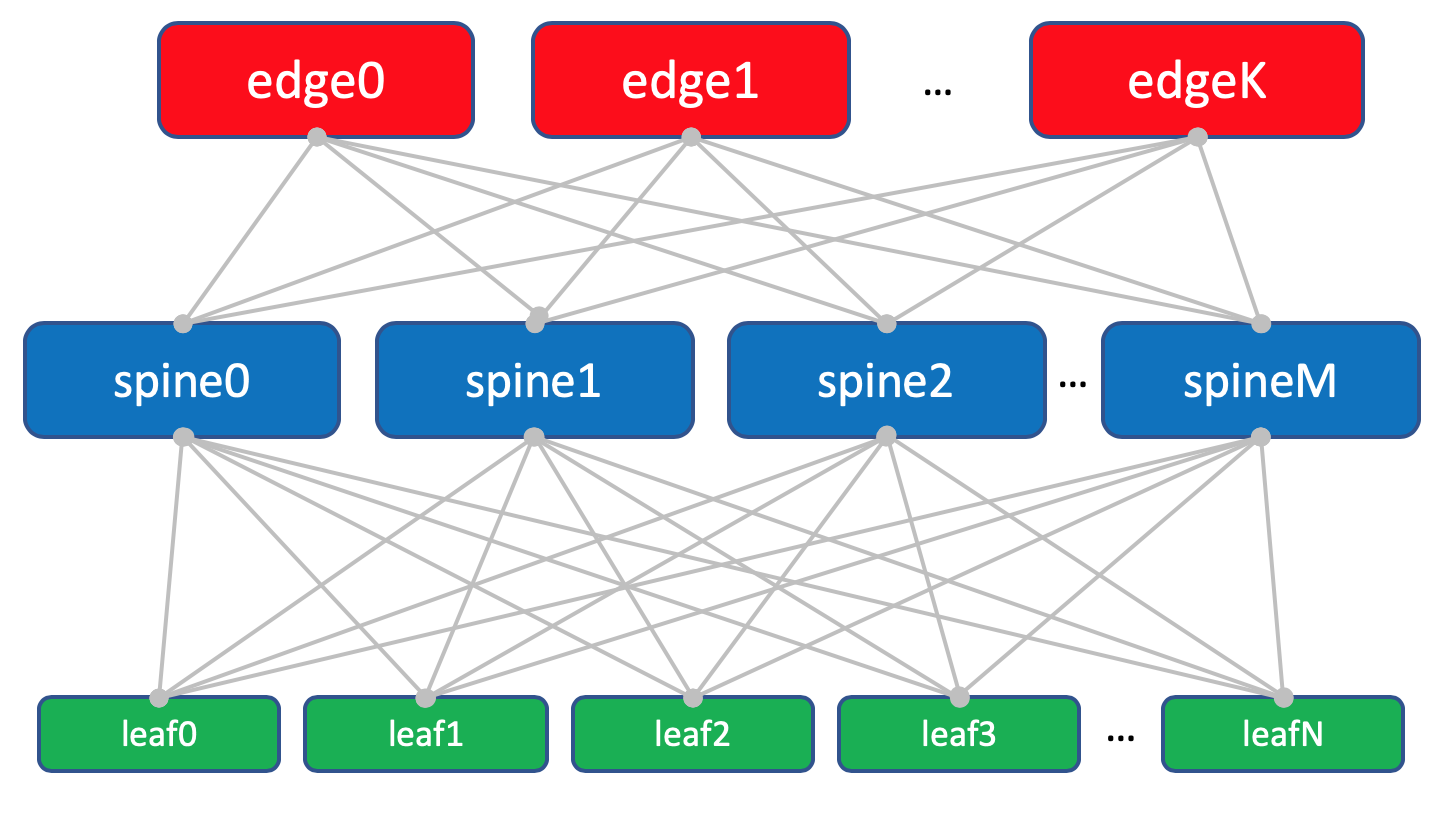 Схема фабрики с Edge-leaf’ами.
Схема фабрики с Edge-leaf’ами.
Троица Leaf, Spine и Edge образуют Underlay-сеть или фабрику.
Задача сетевой фабрики (читай Underlay), как мы уже определились в прошлом выпуске, очень и очень простая — обеспечить IP-связность между машинами как в пределах одного ДЦ, так и между.
Оттого-то сеть и называется фабрикой, так же, например, как фабрика коммутации внутри модульных сетевых коробок, о чём подробнее можно почитать в СДСМ14.
А вообще такая топология называется фабрикой, потому что fabric в переводе — это ткань. И сложно не согласиться:
Фабрика полностью L3. Никаких VLAN, никаких Broadcast — вот такие у нас в LAN_DC замечательные программисты, умеют писать приложения, живущие в парадигме L3, а виртуальные машины не требуют Live Migration c сохранением IP-адреса. И ещё раз: ответ на вопрос почему фабрика и почему L3 — в отдельной статье.
DCI — Data Center Interconnect (Inter-DC)
DCI будет организован с помощью Edge-Leaf, то есть они — наша точка выхода в магистраль.
Для простоты предположим, что ДЦ связаны между собой прямыми линками.
Исключим из рассмотрения внешнюю связность.
Я отдаю себе отчёт в том, что каждый раз, как я убираю какой-либо компонент, я значительно упрощаю сеть. И при автоматизации нашей абстрактной сети всё будет хорошо, а на реальной возникнут костыли.
Это так. И всё же задача этой серии — подумать и поработать над подходами, а не героически решать выдуманные проблемы.
На Edge-Leaf’ах underlay помещается в VPN и передаётся через MPLS-магистраль (тот самый прямой линк).
Вот такая верхнеуровневая схема получается.
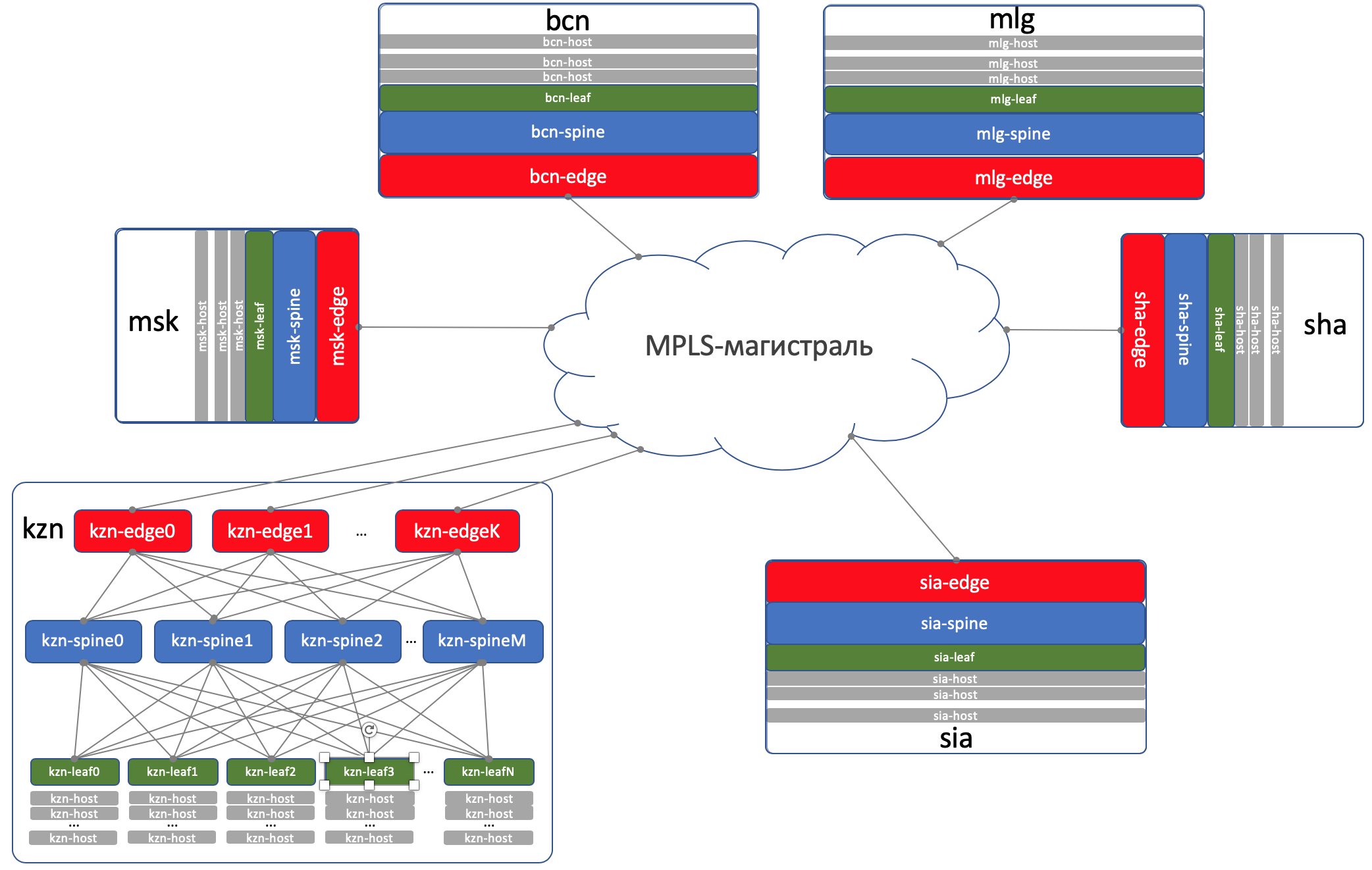
Маршрутизация
Для маршрутизации внутри ДЦ будем использовать BGP.
На MPLS-магистрали OSPF+LDP.
Для DCI, то есть организации связности в андерлее — BGP L3VPN over MPLS.
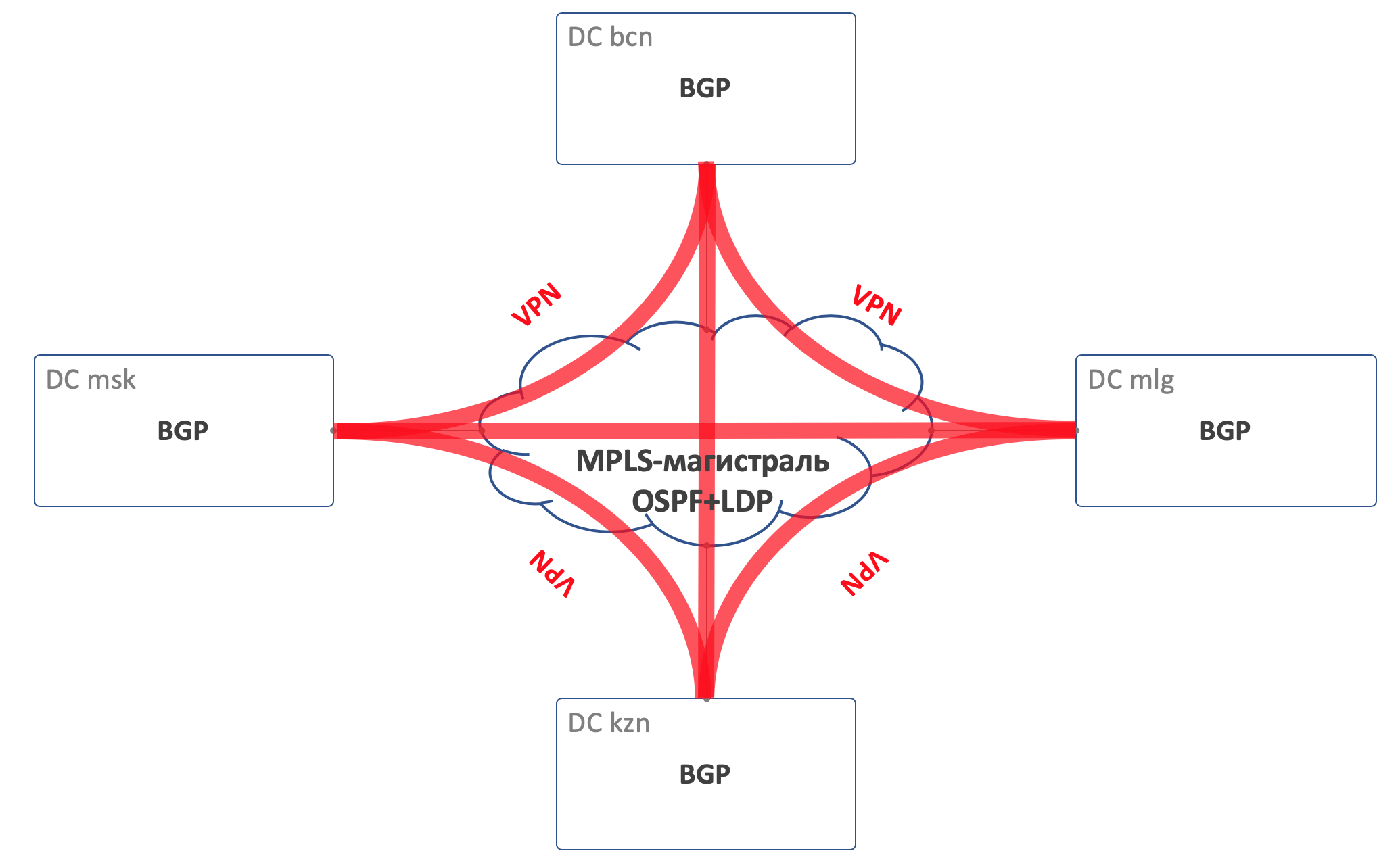 Общая схема маршрутизации
Общая схема маршрутизации
На фабрике никаких OSPF и ISIS (запрещённый в Российской Федерации протокол маршрутизации).
А это значит, что не будет Auto-discovery и вычисления кратчайших путей — только ручная (на самом деле автоматическая — мы же здесь про автоматизацию) настройка протокола, соседства и политик.
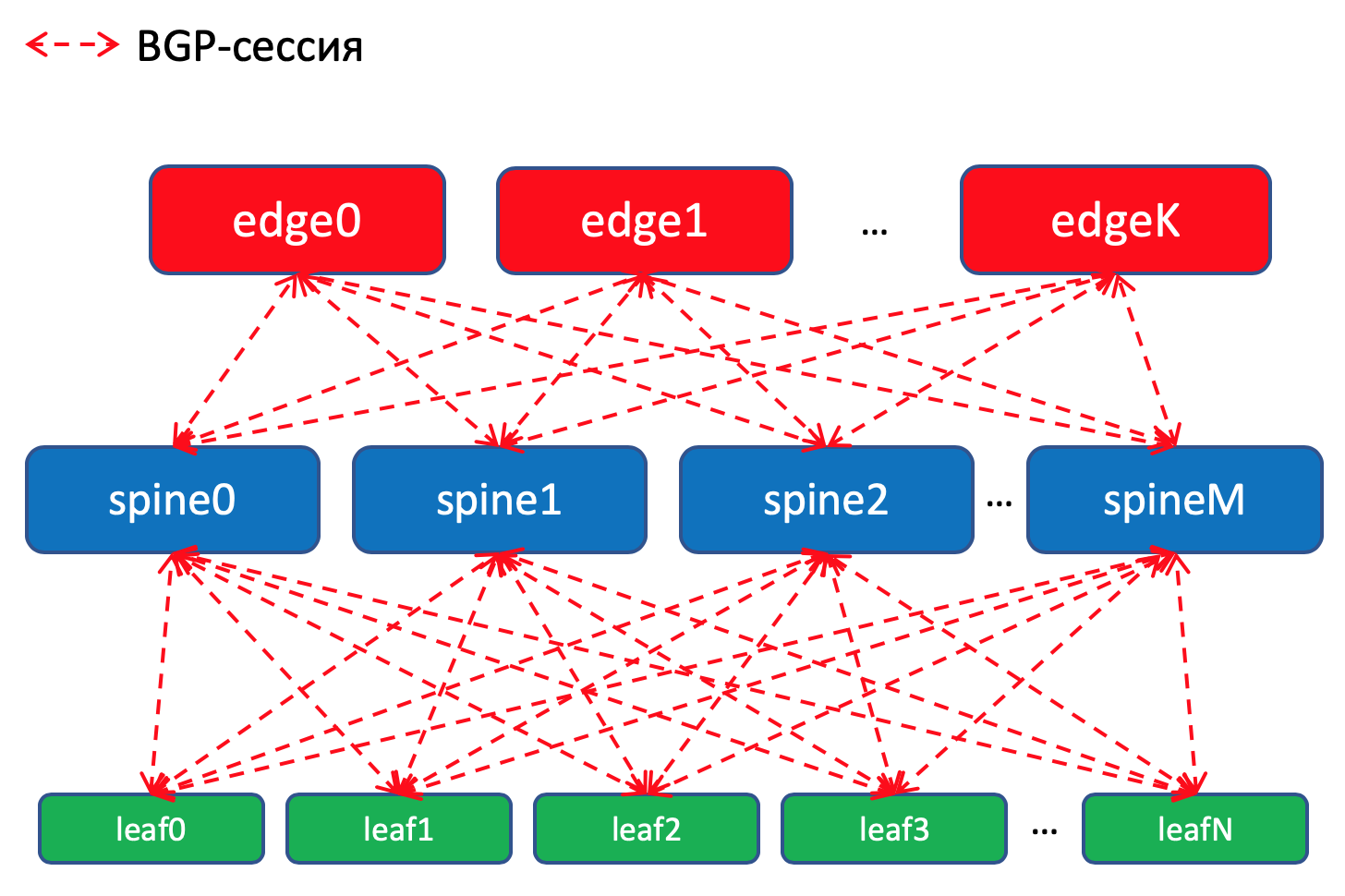 Схема маршрутизации BGP внутри ДЦ
Схема маршрутизации BGP внутри ДЦ
Почему BGP?
На эту тему есть целый RFC имени Facebook’a и Arista, где рассказывается, как строить очень крупные сети датацентров, используя BGP. Читается почти как художественный, очень рекомендую для томного вечера.
А ещё целый раздел в моей статье посвящён этому. Куда я вас и отсылаю.
Но всё же если коротко, то никакие IGP не подходят для сетей крупных датацентров, где счёт сетевым устройствами идёт на тысячи.
Кроме того использование BGP везде позволит не распыляться на поддержку нескольких разных протоколов и синхронизацию между ними.
Положа руку на сердце, на нашей фабрике, которая с большой долей вероятности не будет стремительно расти, за глаза хватило бы и OSPF. Это на самом деле проблемы мегаскейлеров и клауд-титанов. Но пофантазируем всего лишь на несколько выпусков, что нам это нужно, и будем использовать BGP, как завещал Пётр Лапухов.
Политики маршрутизации
На Leaf-коммутаторах мы импортируем в BGP префиксы с Underlay’ных интерфейсов с сетями.
У нас будет BGP-сессия между каждой парой Leaf-Spine, в которой эти Underlay’ные префиксы будут анонсироваться по сети тудыть-сюдыть.
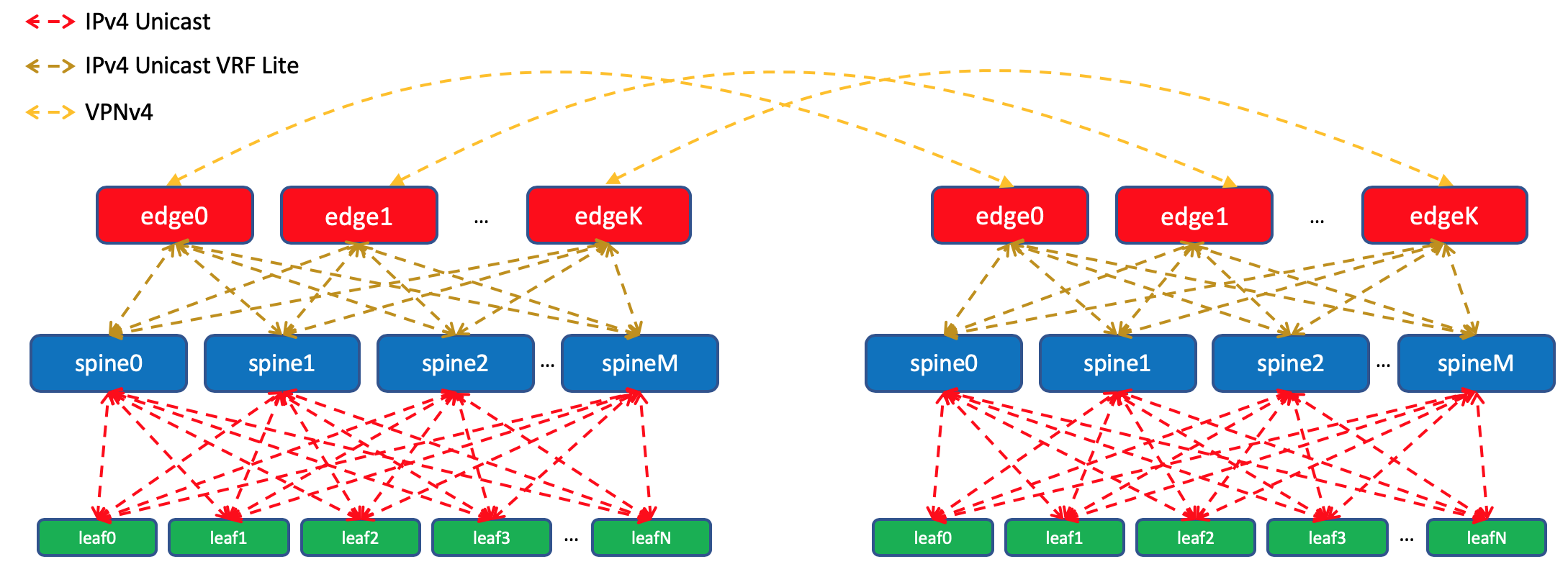 Внутри одного датацентра мы будем распространять специфики, которые импортировали на ТоРе. На Edge-Leaf’ах будем их агрегировать и анонсировать в удалённые ДЦ и спускать до ТоРов. То есть каждый ТоР будет знать точно, как добраться до другого ТоРа в этом же ДЦ и где точка входа, чтобы добраться до ТоРа в другом ДЦ.
Внутри одного датацентра мы будем распространять специфики, которые импортировали на ТоРе. На Edge-Leaf’ах будем их агрегировать и анонсировать в удалённые ДЦ и спускать до ТоРов. То есть каждый ТоР будет знать точно, как добраться до другого ТоРа в этом же ДЦ и где точка входа, чтобы добраться до ТоРа в другом ДЦ.
В DCI маршруты будут передаваться, как VPNv4. Для этого на Edge-Leaf интерфейс в сторону фабрики будет помещаться в VRF, назовём его UNDERLAY, и соседство со Spine на Edge-Leaf будет подниматься внутри VRF, а между Edge-Leaf’ами в VPNv4-family.
 А ещё мы запретим реанонсировать маршруты полученные от спайнов, обратно на них же.
А ещё мы запретим реанонсировать маршруты полученные от спайнов, обратно на них же.
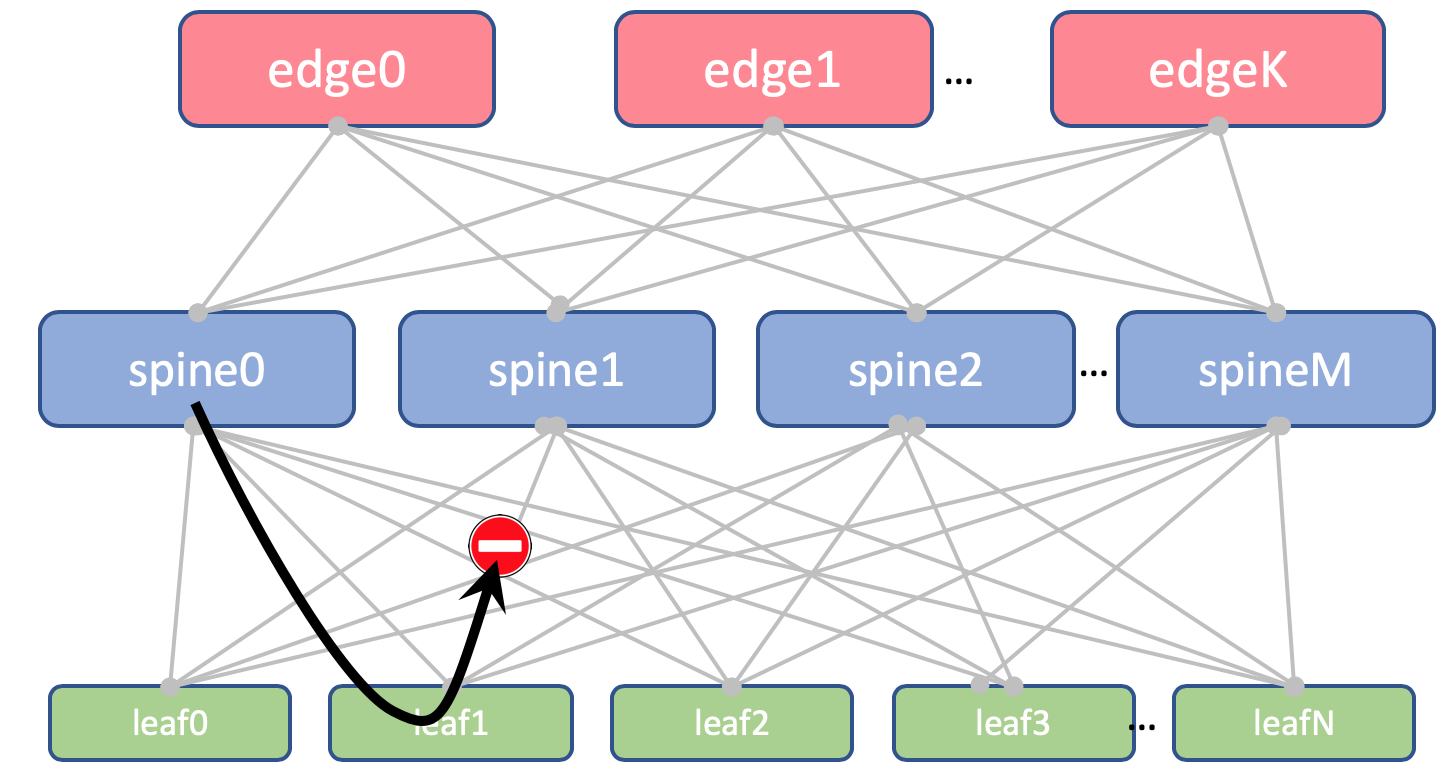 На Leaf и Spine мы не будем импортировать Loopback’и. Они нам понадобятся только для того, чтобы определить Router ID.
На Leaf и Spine мы не будем импортировать Loopback’и. Они нам понадобятся только для того, чтобы определить Router ID.
А вот на Edge-Leaf’ах импортируем его в Global BGP. Между Loopback-адресами Edge-Leaf’ы будут устанавливать BGP-сессию в IPv4 VPN-family друг с другом.
Между EDGE-устройствами у нас будет растянута магистраль на OSPF+LDP. Всё в одной зоне. Предельно простая конфигурация.
Вот такая картина с маршрутизацией.
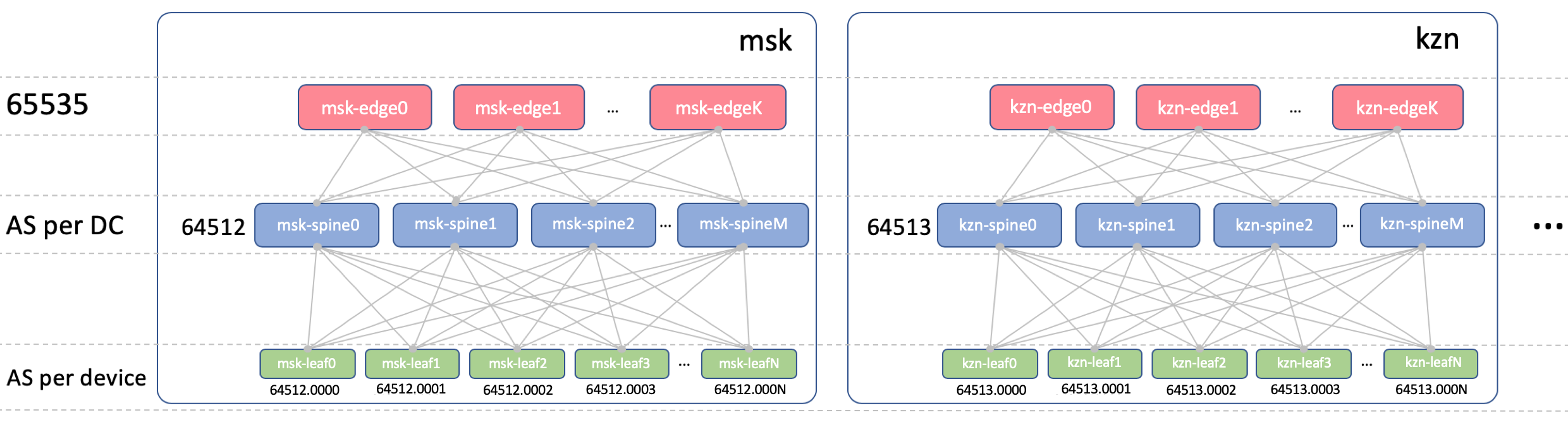
BGP ASN
Edge-Leaf ASN
На Edge-Leaf’ах будет один ASN во всех ДЦ. Это важно, чтобы между Edge-Leaf’ами был iBGP, и мы не накололись на нюансы eBGP. Пусть это будет 65535. В реальности это мог бы быть номер публичной AS.
Spine ASN
На Spine у нас будет один ASN на ДЦ. Начнём здесь с самого первого номера из диапазона приватных AS — 64512, 64513 итд.
Почему ASN на ДЦ?
Декомпозируем этот вопрос на два:
- Почему одинаковые ASN на всех спайнах одного ДЦ?
- Почему разные в разных ДЦ?
Почему одинаковые ASN на всех спайнах одного ДЦ
Вот как будет выглядеть AS-Path Андерлейного маршрута на Edge-Leaf:
[leafX_ASN, spine_ASN, edge_ASN]При попытке заанонсировать его обратно на Спайн, тот его отбросит потому что его AS (Spine_AS) уже есть в списке.
Однако в пределах ДЦ нас совершенно устраивает, что маршруты Underlay, поднявшиеся до Edge не смогут спуститься вниз. Вся коммуникация между хостами внутри ДЦ должна происходить в пределах уровня спайнов.
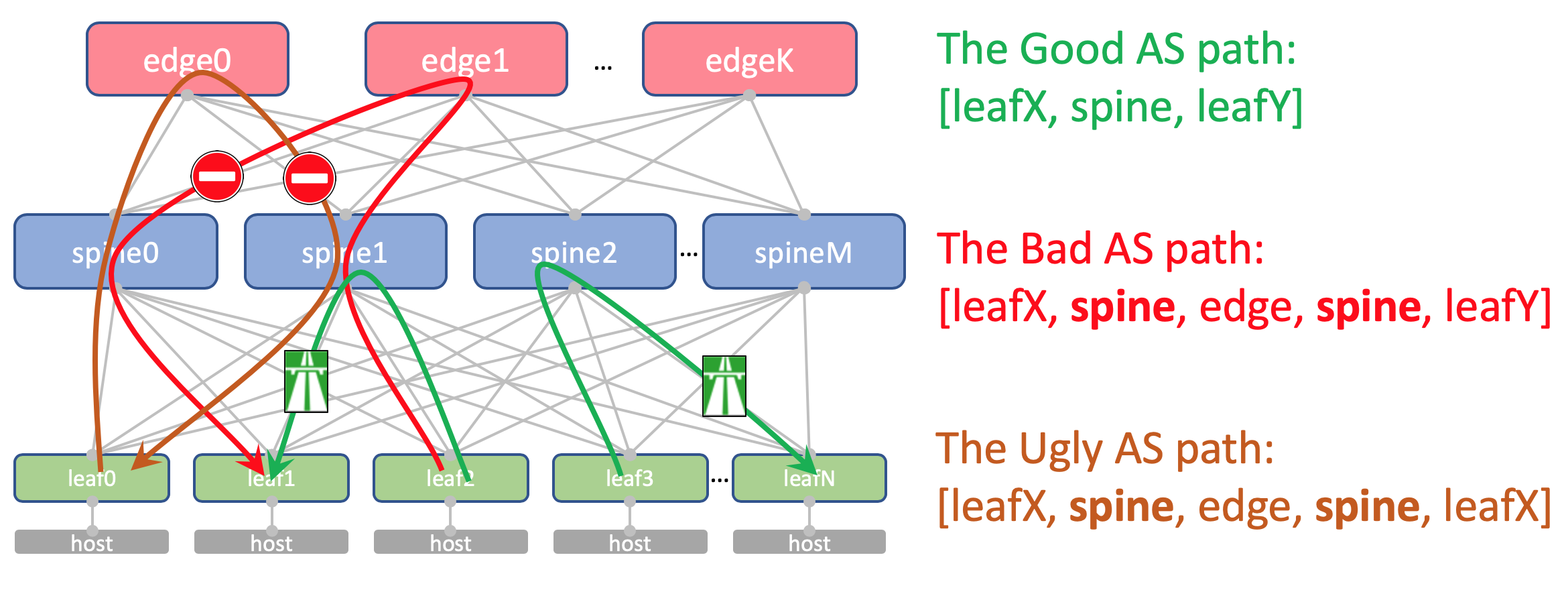 При этом агрегированные маршруты других ДЦ в любом случае беспрепятственно будут доходить до ТоРов — в их AS-Path будет только ASN 65535 — номер AS Edge-Leaf’ов, потому что именно на них они были созданы.
При этом агрегированные маршруты других ДЦ в любом случае беспрепятственно будут доходить до ТоРов — в их AS-Path будет только ASN 65535 — номер AS Edge-Leaf’ов, потому что именно на них они были созданы.
Почему разные в разных ДЦ
Теоретически нам может потребоваться протащить Loopback’и каких-нибудь сервисных виртуальных машин между ДЦ.
Например, на хосте у нас запустится Route Reflector или тот самый VNGW (Virtual Network Gateway), который по BGP запирится с ТоРом и проанонсирует свой лупбэк, который должен быть доступен из всех ДЦ.
Так вот как будет выглядеть его AS-Path:
[VNF_ASN, leafX_DC1_ASN, spine_DC1_ASN, edge_ASN, spine_DC2_ASN, leafY_DC2_ASN]И здесь нигде не должно быть повторяющихся ASN.
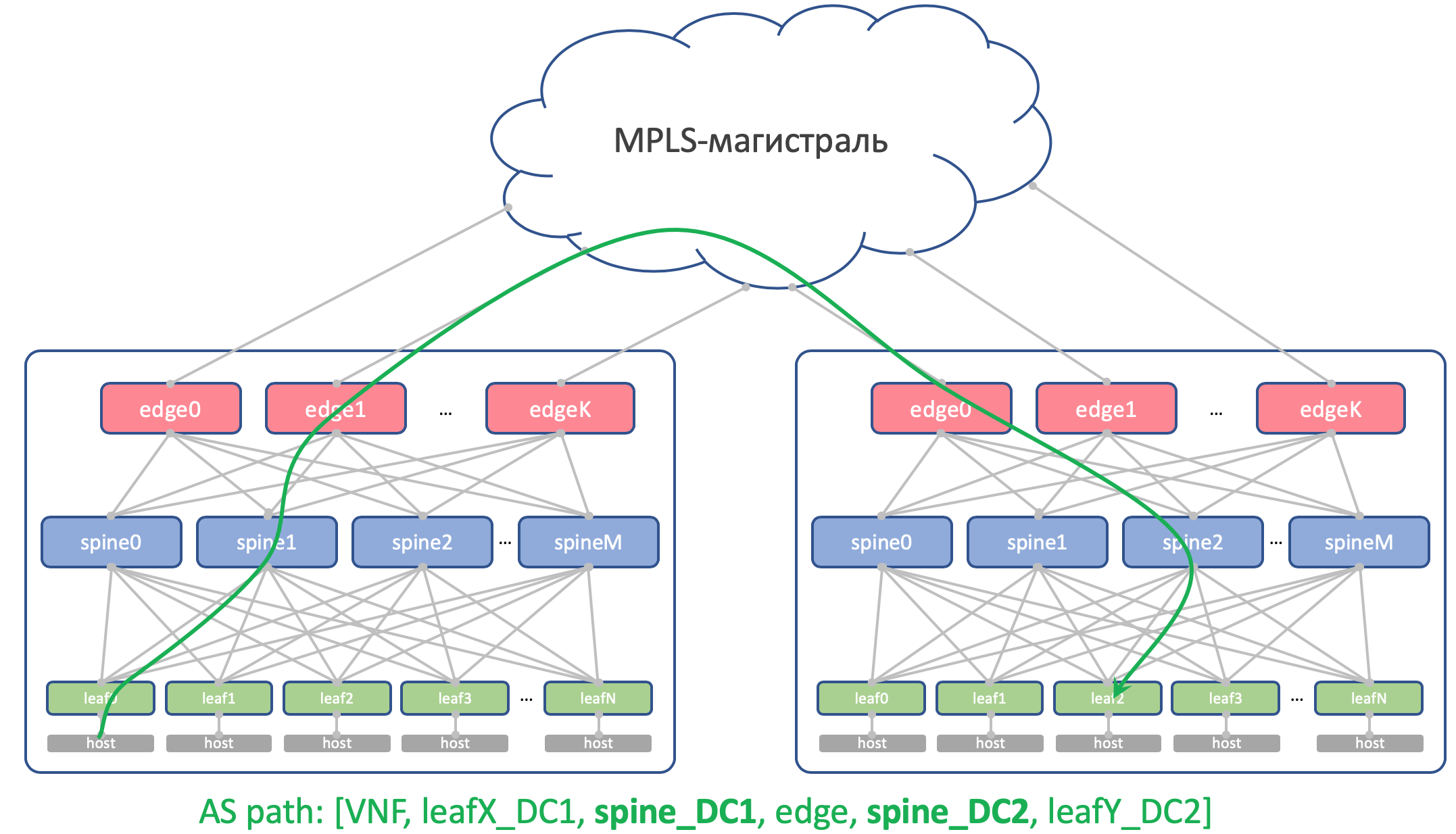 То есть Spine_DC1 и Spine_DC2 должны быть разными, ровно как и leafX_DC1 и leafY_DC2, к чему мы как раз и подходим.
То есть Spine_DC1 и Spine_DC2 должны быть разными, ровно как и leafX_DC1 и leafY_DC2, к чему мы как раз и подходим.
Как вы, наверно, знаете, существуют хаки, позволяющие принимать маршруты с повторяющимися ASN вопреки механизму предотвращения петель (allowas-in на Cisco). И у этого есть даже вполне законные применения. Но это потенциальная брешь в устойчивости сети. И я лично в неё пару раз проваливался.
И если у нас есть возможность не использовать опасные вещи, мы ей воспользуемся.
Leaf ASN
У нас будет индивидуальный ASN на каждом Leaf-коммутаторе в пределах всей сети.
Делаем мы так из соображений, приведённых выше: AS-Path без петель, конфигурация BGP без закладок.
Чтобы маршруты между Leaf’ами беспрепятственно проходили, AS-Path должен выглядеть так:
[leafX_ASN, spine_ASN, leafY_ASN]где leafX_ASN и leafY_ASN хорошо бы, чтобы отличались.
Требуется это и для ситуации с анонсом лупбэка VNF между ДЦ:
[VNF_ASN, leafX_DC1_ASN, spine_DC1_ASN, edge_ASN, spine_DC2_ASN, leafY_DC2_ASN]Будем использовать 4-байтовый ASN и генерировать его на основе ASN Spine’а и номера Leaf-коммутатора, а именно, вот так: Spine_ASN.0000X.
Вот такая картина с ASN.
IP-план
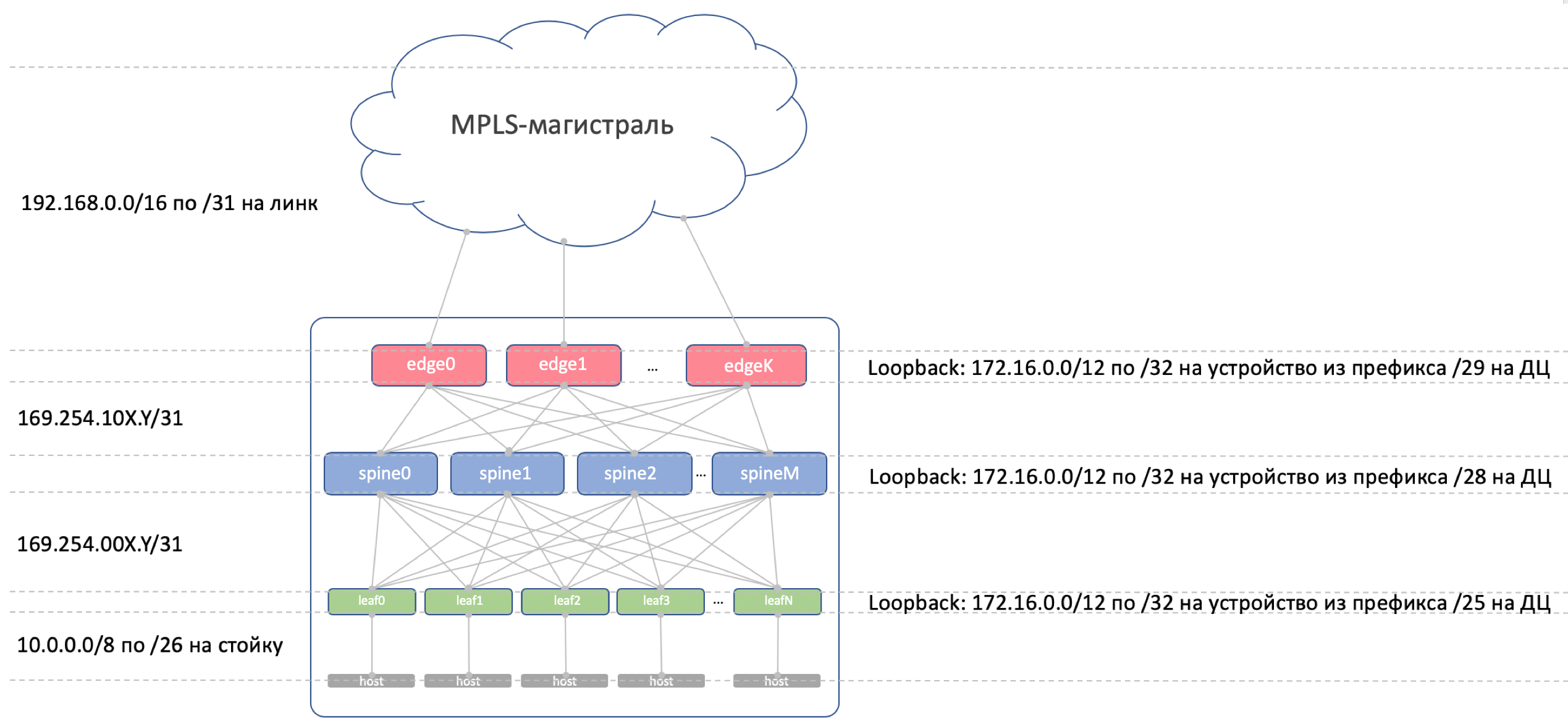
Принципиально, нам нужно выделить адреса для следующих подключений:
- Адреса сети Underlay между ToR и машиной. Они должны быть уникальны в пределах всей сети, чтобы любая машина могла связаться с любой другой. Отлично подходит 10/8. На каждую стойку по /26 с запасом. Будем выделять по /19 на ДЦ и /17 на регион.
- Линковые адреса между Leaf/Tor и Spine. Их хотелось бы назначать алгоритмически, то есть вычислять из имён устройств, которые нужно подключить. Пусть это будет… 169.254.0.0/16. А именно 169.254.00X.Y/31, где X — номер Spine, Y — P2P-сеть /31. Это позволит запускать до 128 стоек, и до 10 Spine в ДЦ. Линковые адреса могут (и будут) повторяться из ДЦ в ДЦ.
- Cтык Spine — Edge-Leaf организуем на подсетях 169.254.10X.Y/31, где точно так же X — номер Spine, Y — P2P-сеть /31.
- Линковые адреса из Edge-Leaf в MPLS-магистраль. Здесь ситуация несколько иная — место соединения всех кусков в один пирог, поэтому переиспользовать те же самые адреса не получится — нужно выбирать следующую свободную подсеть. Поэтому за основу возьмём 192.168.0.0/16 и будем из неё выгребать свободные.
- Адреса Loopback. Отдадим под них весь диапазон 172.16.0.0/12.
- Leaf — по /25 на ДЦ — те же 128 стоек. Выделим по /23 на регион.
- Spine — по /28 на ДЦ — до 16 Spine. Выделим по /26 на регион.
- Edge-Leaf — по /29 на ДЦ — до 8 коробок. Выделим по /27 на регион.
Если в ДЦ нам не будет хватать выделенных диапазонов (а их не будут — мы же претендуем на гиперскейлероство), просто выделяем следующий блок.
Вот такая картина с IP-адресацией.
 Loopback’и:
Loopback’и:
| Префикс | Роль устройства | Регион | ДЦ |
| 172.16.0.0/23 | edge | ||
| 172.16.0.0/27 | ru | ||
| 172.16.0.0/29 | msk | ||
| 172.16.0.8/29 | kzn | ||
| 172.16.0.32/27 | sp | ||
| 172.16.0.32/29 | bcn | ||
| 172.16.0.40/29 | mlg | ||
| 172.16.0.64/27 | cn | ||
| 172.16.0.64/29 | sha | ||
| 172.16.0.72/29 | sia | ||
| 172.16.2.0/23 | spine | ||
| 172.16.2.0/26 | ru | ||
| 172.16.2.0/28 | msk | ||
| 172.16.2.16/28 | kzn | ||
| 172.16.2.64/26 | sp | ||
| 172.16.2.64/28 | bcn | ||
| 172.16.2.80/28 | mlg | ||
| 172.16.2.128/26 | cn | ||
| 172.16.2.128/28 | sha | ||
| 172.16.2.144/28 | sia | ||
| 172.16.8.0/21 | leaf | ||
| 172.16.8.0/23 | ru | ||
| 172.16.8.0/25 | msk | ||
| 172.16.8.128/25 | kzn | ||
| 172.16.10.0/23 | sp | ||
| 172.16.10.0/25 | bcn | ||
| 172.16.10.128/25 | mlg | ||
| 172.16.12.0/23 | cn | ||
| 172.16.12.0/25 | sha | ||
| 172.16.12.128/25 | sia |
Underlay:
| Префикс | Регион | ДЦ |
| 10.0.0.0/17 | ru | |
| 10.0.0.0/19 | msk | |
| 10.0.32.0/19 | kzn | |
| 10.0.128.0/17 | sp | |
| 10.0.128.0/19 | bcn | |
| 10.0.160.0/19 | mlg | |
| 10.1.0.0/17 | cn | |
| 10.1.0.0/19 | sha | |
| 10.1.32.0/19 | sia |
Лаба
Два вендора. Одна сеть. АДСМ.
Juniper + Arista. Ubuntu. Старая добрая Ева.
Количество ресурсов на нашей виртуалочке в Миране всё же ограничено, поэтому для практики мы будем использовать вот такую упрощённую до предела сеть.
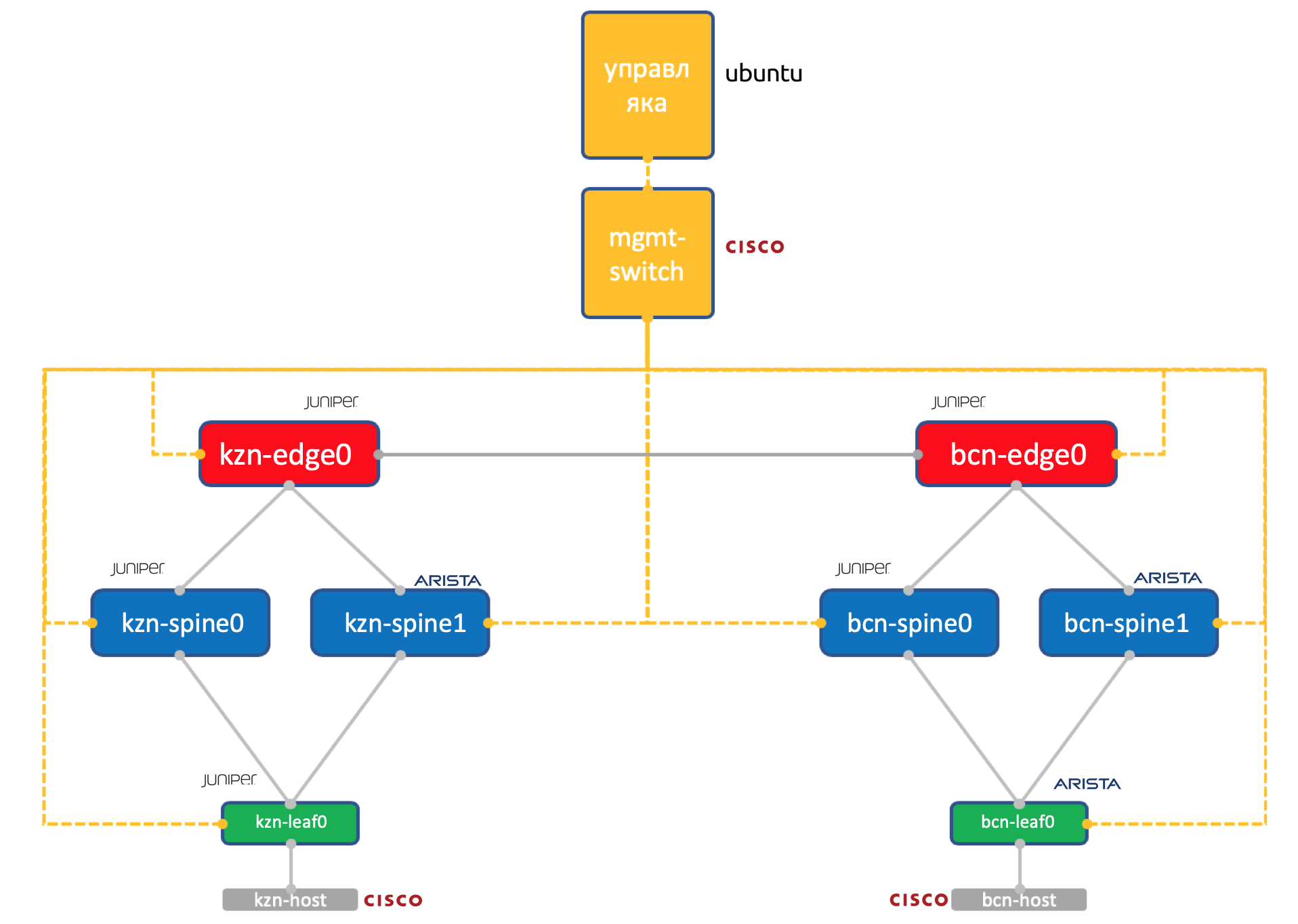 Два датацентра: Казань и Барселона.
Два датацентра: Казань и Барселона.
- По два спайна в каждом: Juniper и Arista.
- По одному тору (Leaf’у) в каждом — Juniper и Arista, с одним подключенным хостом (возьмём легковесный Cisco IOL для этого).
- По одной ноде Edge-Leaf (пока только Juniper).
- One Cisco switch to rule them all.
- Помимо сетевых коробок запущена виртуальная машина-управляка. Под управлением Ubuntu. Она имеет доступ ко всем устройствам, на ней будут крутиться IPAM/DCIM-системы, букет питоновских скриптов, анзибль и что угодно ещё, что нам может понадобиться.
Полная конфигурация всех сетевых устройств, которую мы будем пробовать воспроизвести с помощью автоматики.
Заключение
Так же принято? Под каждой статьёй делать короткий вывод?
Итак мы выбрали трёхуровневую сеть Клоза внутри ДЦ, поскольку ожидаем много East-West трафика и хотим ECMP.
Разделили сеть на физическую (андерлей) и виртуальную (оверлей). При этом оверлей начинается с хоста — тем самым упростили требования к андерлею.
Выбрали BGP в качестве протокола маршрутизации анедрелейных сетей за его масштабируемость и гибкость политик.
У нас будут отдельные узлы для организации DCI — Edge-leaf.
На магистрали будет OSPF+LDP.
DCI будет реализован на основе MPLS L3VPN.
Для P2P-линков IP-адреса мы будем вычислять алгоритмически на основе имён устройств.
Лупбэки будем назначать по роли устройств и их расположению последовательно.
Андерлейные префиксы — только на Leaf-коммутаторы последовательно на основе их расположения.
Предположим, что прямо сейчас у нас ещё не установлено оборудование.
Поэтому наши следующие шаги будут — завести их в системах (IPAM, инвентарная), организовать доступ, сгенерировать конфигурацию и задеплоить её.
В следующей статье разберёмся с Netbox — системой инвентаризации и управления IP-пространством в ДЦ.
Спасибы
- Андрею Глазкову aka @glazgoo за вычитку и правки
- Александру Клименко aka @v00lk за вычитку и правки
- Артёму Чернобаю за КДПВ
Оставайтесь на связи
Особо благодарных просим задержаться и пройти на Патреон.





 481
481
 27779
27779
 1
1
Ещё статьи


1 коментарий
Одна из лучших и подробнейших статей про IPAM в DC!