





АДСМ0. Планирование
 426
426

 53692
53692
 18
18



СДСМ закончился, а бесконтрольное желание писать — осталось.

Долгие годы наш брат страдал от выполнения рутинной работы, скрещивал пальцы перед коммитом и недосыпал из-за ночных ролбэков.
Но тёмным временам приходит конец.
Этой статьёй я начну серию о том, как мне видится автоматизация.
По ходу дела разберёмся с этапами автоматизации, хранением переменных, формализацией дизайна, с RestAPI, NETCONF, YANG, YDK и будем очень много программировать.
Мне означает, что а) это не объективная истина, б) не безоговорочно лучший подход в) мой взгляд даже в ходе движения от первой к последней статье может поменяться — честно говоря, от стадии черновика до публикации я переписывал всё полностью дважды.
Содержание
- Цели
- Средства
- Инвентарная система
- Система управления IP-пространством
- Система описания сетевых сервисов
- Механизм инициализации устройств
- Вендор-агностик конфигурационная модель
- Вендор-интерфейс специфичный драйвер
- Механизм доставки конфигурации на устройство
- CI/CD
- Механизм резервного копирования и поиска отклонений
- Система мониторинга
- Заключение
АДСМ я попробую вести в формате, немного отличном от СДСМ. По-прежнему будут появляться большие обстоятельные номерные статьи, а между ними я буду публиковать небольшие заметки из повседневного опыта. Постараюсь тут бороться с перфекционизмом и не вылизывать каждую из них.
Как это забавно, что во второй раз приходится проходить один и тот же путь.
Сначала пришлось писать самому статьи про сети из-за того, что их не было в рунете.
Теперь я не смог найти всесторонний документ, который систематизировал бы подходы к автоматизации и на простых практических примерах разбирал вышеперечисленные технологии.
Возможно, я ошибаюсь, поэтому, кидайте ссылки на годные ресурсы. Впрочем это не изменит моей решимости писать, потому что, основная цель — это всё-таки научиться чему-то самому, а облегчить жизнь ближнему — это приятный бонус, который ласкает ген распространения опыта.
Мы попробуем взять средних размеров дата-центр LAN DC и проработать всю схему автоматизации.
Делать некоторые вещи я буду практически впервые вместе с вами.
В описываемых тут идеях и инструментах я буду не оригинален. У Дмитрия Фиголя есть отличный канал со стримами на эту тему.
Статьи во многих аспектах будут с ними пересекаться.
В LAN DC 4 ДЦ, около 250 коммутаторов, полдюжины маршрутизаторов и пара файрволов.
Не фейсбук, но достаточно для того, чтобы глубоко задуматься об автоматизации.
Бытует, впрочем, мнение, что если у вас больше 1 устройства, уже нужна автоматизация.
На самом деле тяжело представить, что кто-то сейчас может жить без хотя бы пачки наколеночных скриптов.
Хотя я слышал, что есть такие конторы, где учёт IP-адресов ведётся в экселе, а каждое из тысяч сетевых устройств настраивается вручную и имеет свою неповторимую конфигурацию. Это, конечно, можно выдать за современное искусство, но чувства инженера точно будут оскорблены.
Цели
Сейчас мы поставим максимально абстрактные цели:
- Сеть — как единый организм
- Тестирование конфигурации
- Версионирование состояния сети
- Мониторинг и самовосстановление сервисов
Позже в этой статье разберём какие будем использовать средства, а в следующих и цели и средства в подробностях.
Сеть — как единый организм
Определяющая фраза цикла, хотя на первый взгляд она может показаться не такой уж значительной: мы будем настраивать сеть, а не отдельные устройства.
Все последние годы мы наблюдаем сдвиг акцентов к тому, чтобы обращаться с сетью, как с единой сущностью, отсюда и приходящие в нашу жизнь Software Defined Networking, Intent Driven Networks и Autonomous Networks.
Ведь что глобально нужно приложениям от сети: связности между точками А и Б (ну иногда +В-Я) и изоляции от других приложений и пользователей.  И таким образом, наша задача в этой серии — выстроить систему, поддерживающую актуальную конфигурацию всей сети, которая уже декомпозируется на актуальную конфигурацию на каждом устройстве в соответствии с его ролью и местоположением.
И таким образом, наша задача в этой серии — выстроить систему, поддерживающую актуальную конфигурацию всей сети, которая уже декомпозируется на актуальную конфигурацию на каждом устройстве в соответствии с его ролью и местоположением.
Система управления сетью подразумевает, что для внесения изменений мы обращаемся в неё, а она уже в свою очередь вычисляет нужное состояние для каждого устройства и настраивает его.
Таким образом мы минимизируем почти до нуля хождение в CLI руками — любые изменения в настройках устройств или дизайне сети должны быть формализованы и документированы — и только потом выкатываться на нужные элементы сети.
То есть, например, если мы решили, что с этого момента стоечные коммутаторы в Казани должны анонсировать две сети вместо одной, мы
- Сначала документируем изменения в системах
- Генерируем целевую конфигурацию всех устройств сети
- Запускаем программу обновления конфигурации сети, которая вычисляет, что нужно удалить на каждом узле, что добавить, и приводит узлы к нужному состоянию.
При этом руками мы вносим изменения только на первом шаге.
Тестирование конфигурации
Известно, что 80% проблем случаются во время изменения конфигурации — косвенное тому свидетельство — то, что в период новогодних каникул обычно всё спокойно.
Я лично был свидетелем десятков глобальных даунтаймов из-за ошибки человека: неправильная команда, не в той ветке конфигурации выполнили, забыли комьюнити, снесли MPLS глобально на маршрутизаторе, настроили пять железок, а на шестой ошибку не заметили, закоммитили старые изменения, сделанные другим человеком. Сценариев тьма тьмущая.
Автоматика нам позволит совершать меньше ошибок, но в большем масштабе. Так можно окирпичить не одно устройство, а всю сеть разом.
Испокон веков наши деды проверяли правильность вносимых изменений острым глазом, стальными яйцами и работоспособностью сети после их выкатки.
Те деды, чьи работы приводили к простою и катастрофическим убыткам, оставляли меньше потомства и должны со временем вымереть, но эволюция процесс медленный, и поэтому до сих пор не все предварительно проверяют изменения в лаборатории.
Однако на острие прогресса те, кто автоматизировал процесс тестирования конфигурации, и дальнейшего её применения на сеть. Иными словами — позаимствовал процедуру CI/CD (Continuous Integration, Continuous Deployment) у разработчиков.
В одной из частей мы рассмотрим как реализовать это с помощью системы контроля версий, вероятно, гитхаба.
Как только вы свыкнитесь с мыслью о сетевом CI/CD, в одночасье метод проверки конфигурации путём её применения на рабочую сеть покажется вам раннесредневековым невежеством. Примерно как стучать молотком по боеголовке.
Органическим продолжением идей о системе управления сетью и CI/CD становится полноценное версионирование конфигурации.
Версионирование
Мы будем считать, что при любых изменениях, даже самых незначительных, даже на одном незаметном устройстве, вся сеть переходит из одного состояния в другое.
И мы всегда не выполняем команду на устройстве, мы меняем состояние сети.
Вот давайте эти состояния и будем называть версиями?
Допустим, текущая версия — 1.0.0.
Поменялся IP-адрес Loopback-интерфейса на одном из ToR’ов? Это минорная версия — получит номер 1.0.1.
Пересмотрели политики импорта маршрутов в BGP — чуть посерьёзнее — уже 1.1.0
Решили избавиться от IGP и перейти только на BGP — это уже радикальное изменение дизайна — 2.0.0.
При этом разные ДЦ могут иметь разные версии — сеть развивается, ставится новое оборудование, где-то добавляются новые уровни спайнов, где-то — нет, итд.
Про семантическое версионирование мы поговорим в отдельной статье.
Повторюсь — любое изменение (кроме отладочных команд) — это обновление версии. О любых отклонениях от актуальной версии должны оповещаться администраторы.
То же самое касается отката изменений — это не отмена последних команд, это не rollback силами операционной системы устройства — это приведение всей сети к новой (старой) версии.
Мониторинг и самовосстановление сервисов
Это самоочевидная задача в современных сетях выходит на новый уровень.
Зачастую у больших сервис-провайдеров практикуется подход, что упавший сервис надо очень быстро добить и поднять новый, вместо того, чтобы разбираться, что произошло.
«Очень» означает, что со всех сторон нужно обильно обмазаться мониторингами, которые в течение секунд обнаружат малейшие отклонения от нормы.
И здесь уже не достаточно привычных метрик, вроде загрузки интерфейса или доступности узла. Недостаточно и ручного слежения дежурного за ними.
Для многих вещей вообще должен быть Self-Healing — мониторинги зажглись красным и пошли сами подорожник приложили, где болит.
И здесь мы тоже мониторим не только отдельные устройства, но и здоровье сети целиком, причём как вайтбокс, что сравнительно понятно, так и блэкбокс, что уже сложнее.
Что нам понадобится для реализации таких амбициозных планов?
- Иметь список всех устройств в сети, их расположение, роли, модели, версии ПО. kazan-leaf-1.lmu.net, Kazan, leaf, Juniper QFX 5120, R18.3.
- Иметь систему описания сетевых сервисов. IGP, BGP, L2/3VPN, Policy, ACL, NTP, SSH.
- Уметь инициализировать устройство. Hostname, Mgmt IP, Mgmt Route, Users, RSA-Keys, LLDP, NETCONF
- Настраивать устройство и приводить конфигурацию к нужной (в том числе старой) версии.
- Тестировать конфигурацию
- Периодически проверять состояние всех устройств на предмет отхождения от актуального и сообщать кому следует. ночью кто-то тихонько добавил правило в ACL
- Следить за работоспособностью.
Средства
Звучит достаточно сложно для того, чтобы начать декомпозировать проект на компоненты.
И будет их десять:
- Инвентарная система
- Система управления IP-пространством
- Система описания сетевых сервисов
- Механизм инициализации устройств
- Вендор-агностик конфигурационная модель
- Вендор-интерфейс специфичный драйвер
- Механизм доставки конфигурации на устройство
- CI/CD
- Механизм резервного копирования и поиска отклонений
- Система мониторинга
Это, кстати, пример того, как менялся взгляд на цели цикла — в черновике компонентов было 4.
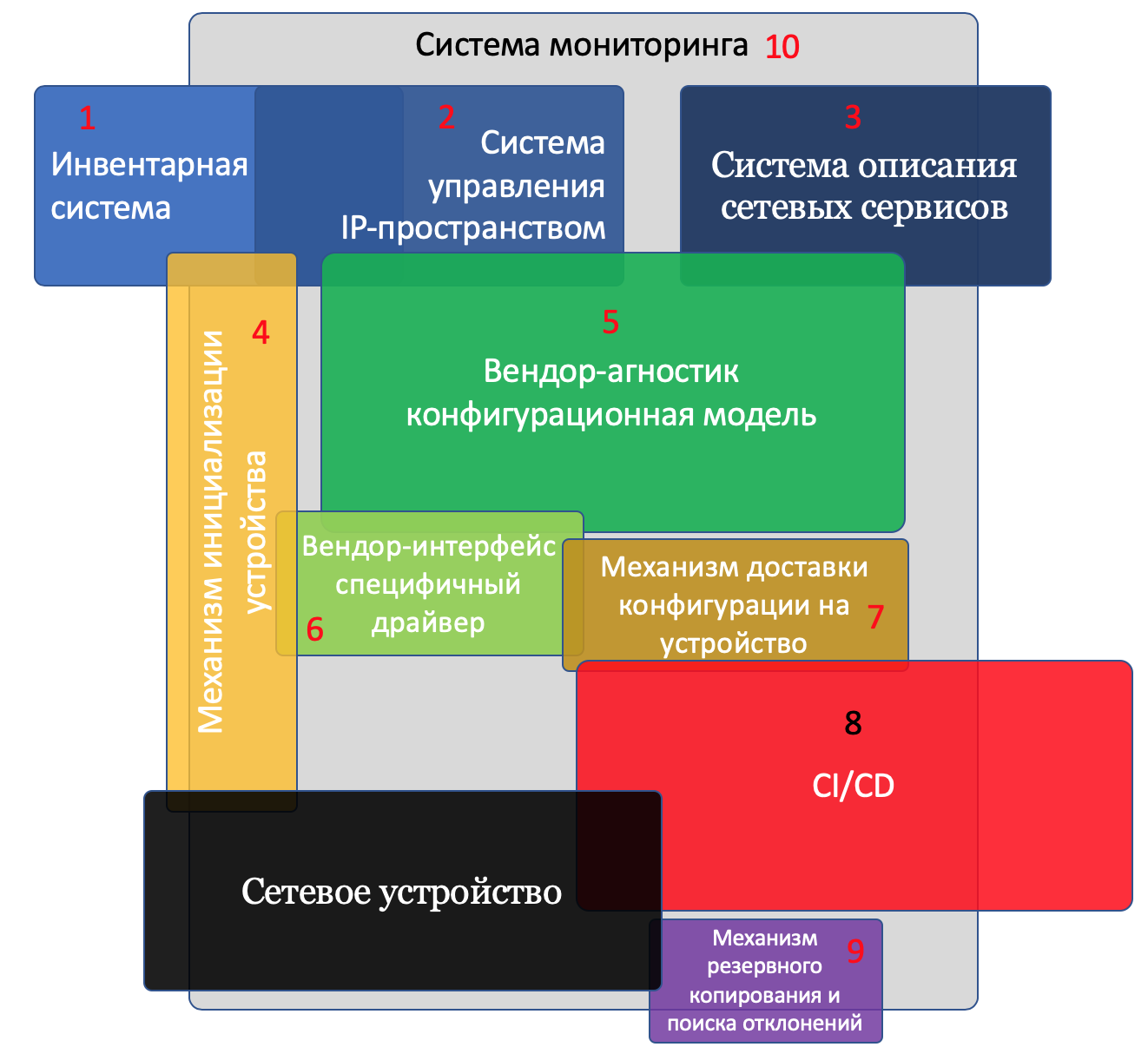 На иллюстрации я изобразил все компоненты и собственно устройство.
На иллюстрации я изобразил все компоненты и собственно устройство.
Пересекающиеся компоненты взаимодействуют другу с другом.
Чем больше блок, тем больше внимания нужно уделить этому компоненту.
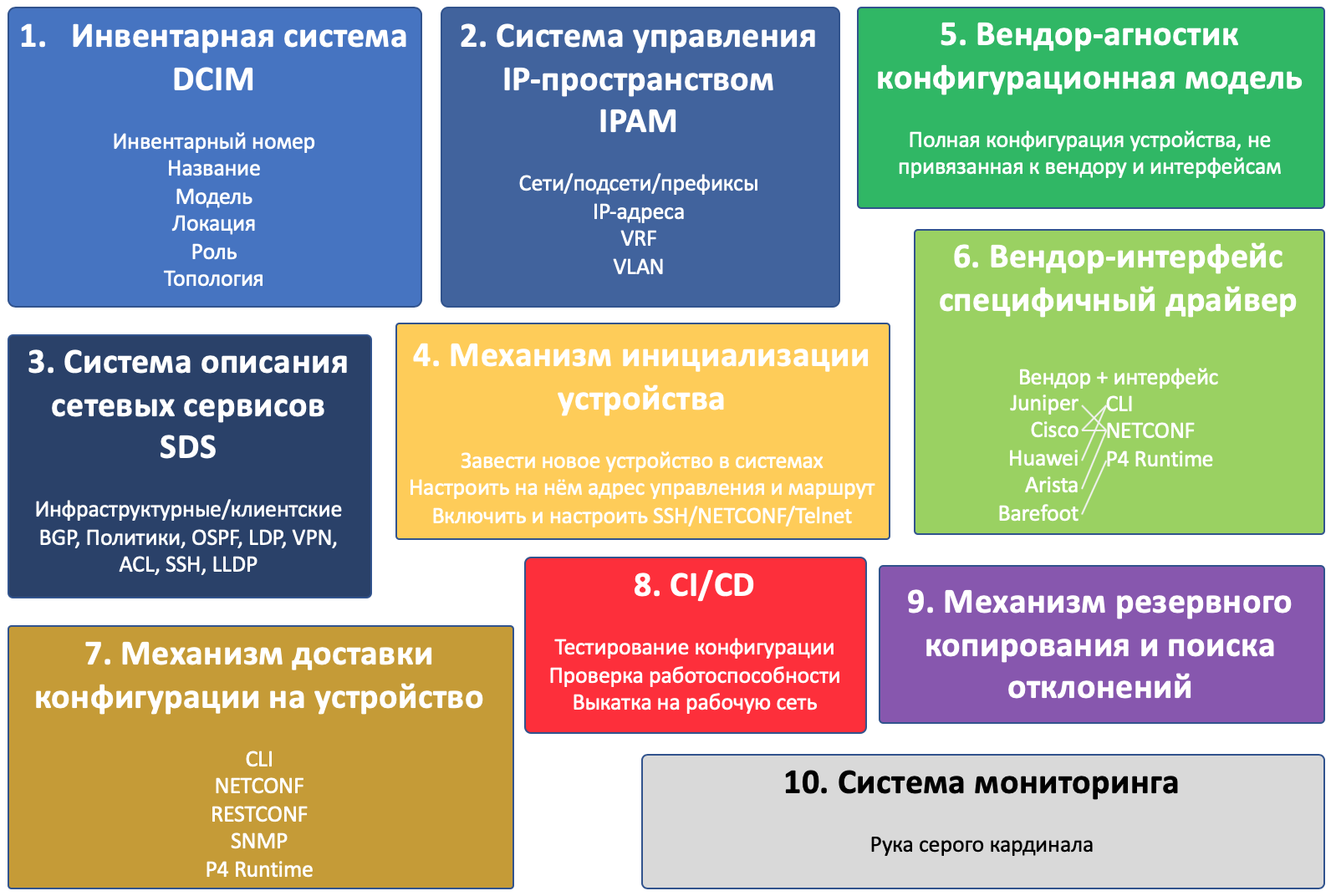
Компонент 1. Инвентарная система
Очевидно, мы хотим знать, какое оборудование, где стоит, к чему подключено.
Инвентарная система — неотъемлемая часть любого предприятия.
Чаще всего для сетевых устройств предприятие имеет отдельную инвентарную систему, которая решает более специфичные задачи.
В рамках цикла статей мы будем называть это DCIM — Data Center Infrastructure Management. Хотя сам термин DCIM, строго говоря, включает в себя гораздо больше.
Для наших задач в ней мы будем хранить следующую информацию про устройство:
- Инвентарный номер
- Название/описание
- Модель (Huawei CE12800, Juniper QFX5120 итд)
- Характерные параметры (платы, интерфейсы итд)
- Роль (Leaf, Spine, Border Router итд)
- Локацию (регион, город, дата-центр, стойка, юнит)
- Интерконнекты между устройствами
- Топологию сети
 Прекрасно понятно, что нам самим хочется знать всё это.
Прекрасно понятно, что нам самим хочется знать всё это.
Но поможет ли это в целях автоматизации?
Безусловно.
Например, мы знаем, что в данном дата-центре на Leaf-коммутаторах, если это Huawei, ACL для фильтрации определённого трафика должны применяться на VLAN, а если это Juniper — то на unit 0 физического интерфейса.
Или нужно раскатить новый Syslog-сервер на все бордеры региона.
В ней же мы будем хранить виртуальные сетевые устройства, например виртуальные маршрутизаторы или рут-рефлекторы. Можем добавить DNS-сервера, NTP, Syslog и вообще всё, что так или иначе относится к сети.
Компонент 2. Система управления IP-пространством
Да, и в наше время находятся коллективы людей, которые ведут учёт префиксов и IP-адресов в Excel-файле. Но современный подход — это всё-таки база данных, с фронтендом на nginx/apache, API и широкими функциями по учёту IP-адресов и сетей с разделением на VRF.
IPAM — IP Address Management.
Для наших задач в ней мы будем хранить следующую информацию:
- VLAN
- VRF
- Сети/Подсети
- IP-адреса
- Привязка адресов к устройствам, сетей к локациям и номерам VLAN
 Опять же понятно, что мы хотим быть уверены, что, выделяя новый IP-адрес для лупбэка ToR’а, мы не споткнёмся о то, что он уже был кому-то назначен. Или что один и тот же префикс мы использовали дважды в разных концах сети. Но как это поможет в автоматизации?
Опять же понятно, что мы хотим быть уверены, что, выделяя новый IP-адрес для лупбэка ToR’а, мы не споткнёмся о то, что он уже был кому-то назначен. Или что один и тот же префикс мы использовали дважды в разных концах сети. Но как это поможет в автоматизации?
Легко.
Запрашиваем в системе префикс с ролью Loopbacks, в котором есть доступные для выделения IP-адреса — если находится, выделяем адрес, если нет, запрашиваем создание нового префикса.
Или при создании конфигурации устройства мы из этой же системы можем узнать, в каком VRF должен находиться интерфейс.
А при запуске нового сервера скрипт сходит в систему, узнает в каком сервер свитче, в каком порту и какая подсеть назначена на интерфейс — из него и будет выделять адрес сервера.
Напрашивается желание DCIM и IPAM объединить в одну систему, чтобы не дублировать функции и не обслуживать две похожие сущности.
Так мы и сделаем.
Компонент 3. Система описания сетевых сервисов
Если первые две системы хранят переменные, которые ещё нужно как-то использовать, то третья описывает для каждой роли устройства, как оно должно быть настроено.
Стоит выделить два разных типа сетевых сервисов:
- Инфраструктурные
- Клиентские.
Первые призваны обеспечить базовую связность и управление устройством. Сюда можно отнести VTY, SNMP, NTP, Syslog, AAA, протоколы маршрутизации, CoPP итд.
Вторые организуют услугу для клиента: MPLS L2/L3VPN, GRE, VXLAN, VLAN, L2TP итд.
Разумеется, есть и пограничные случаи — куда отнести MPLS LDP, BGP? Да и протоколы маршрутизации могут использоваться для клиентов. Но это не принципиально.
Оба типа сервисов раскладываются на конфигурационные примитивы:
- физические и логические интерфейсы (тег/антег, mtu)
- IP-адреса и VRF (IP, IPv6, VRF)
- ACL и политики обработки трафика
- Протоколы (IGP, BGP, MPLS)
- Политики маршрутизации (префикс-листы, коммьюнити, ASN-фильтры).
- Служебные сервисы (SSH, NTP, LLDP, Syslog…)
- Итд.
Как именно мы это будем делать, я пока ума не приложу. Разберёмся в отдельной статье.  Если чуть ближе к жизни, то мы могли бы описать, что
Если чуть ближе к жизни, то мы могли бы описать, что
Leaf-коммутатор должен иметь BGP-сессии со всем подключенными Spine-коммутаторами, импортировать в процесс подключенные сети, принимать от Spine-коммутаторов только сети из определённого префикса. Ограничивать CoPP IPv6 ND до 10 pps итд.
В свою очередь спайны держат сессии со всеми подключенными лифами, выступая в качестве рут-рефлекторов, и принимают от них только маршруты определённой длины и с определённым коммунити.
Компонент 4. Механизм инициализации устройства
Под этим заголовком я объединяю множество действий, которые должны произойти, чтобы устройство появилось на радарах и на него можно было попасть удалённо.
- Завести устройство в инвентарной системе.
- Выделить IP-адрес управления.
- Настроить базовый доступ на него: Hostname, IP-адрес управления, маршрут в сеть управления, пользователи, SSH-ключи, протоколы — telnet/SSH/NETCONF
Тут существует три подхода:
- Полностью всё вручную. Устройство привозят на стенд, где обычный органический человек, заведёт его в системы, подключится консолью и настроит. Может сработать на небольших статических сетях.
- ZTP — Zero Touch Provisioning. Железо приехало, встало, по DHCP получило себе адрес, сходило на специальный сервер, самонастроилось.
- Инфраструктура консольных серверов, где первичная настройка происходит через консольный порт в автоматическом режиме.
Про все три поговорим в отдельной статье. 
Компонент 5. Вендор-агностик конфигурационная модель
До сих пор все системы были разрозненными лоскутами, дающими переменные и декларативное описание того, что мы хотели бы видеть на сети. Но рано или поздно, придётся иметь дело с конкретикой.
На этом этапе для каждого конкретного устройства примитивы, сервисы и переменные комбинируются в конфигурационную модель, фактически описывающую полную конфигурацию конкретного устройства, только в вендоронезависимой манере.
Что даёт этот шаг? Почему бы сразу не формировать конфигурацию устройства, которую можно просто залить?
На самом деле это позволяет решить три задачи:
- Не подстраиваться под конкретный интерфейс взаимодействия с устройством. Будь то CLI, NETCONF, RESTCONF, SNMP — модель будет одинаковой.
- Не держать количество шаблонов/скриптов по числу вендоров в сети, и в случае изменения дизайна, менять одно и то же в нескольких местах.
- Загружать конфигурацию с устройства (бэкапа), раскладывать её в точно такую же модель и непосредственно сравнивать между собой целевую конфигурацию и имеющуюся для вычисления дельты и подготовки конфигурационного патча, который изменит только те части, которые необходимо или для выявления отклонений.
 В результате этого этапа мы получаем вендоронезависимую конфигурацию.
В результате этого этапа мы получаем вендоронезависимую конфигурацию.
Компонент 6. Вендор-интерфейс специфичный драйвер
Не стоит тешить себя надеждами на то, что когда-то настраивать циску можно будет точно так же, как джунипер, просто отправив на них абсолютно одинаковые вызовы. Несмотря на набирающие популярность whitebox’ы и на появление поддержки NETCONF, RESTCONF, OpenConfig, конкретный контент, который этими протоколами доставляется, отличается от вендора к вендору, и это одно из их конкурентных отличий, которое они так просто не сдадут.
Это примерно точно так же, как OpenContrail и OpenStack, имеющие RestAPI в качестве своего NorthBound-интерфейса, ожидают совершенно разные вызовы.
Итак, на пятом шаге вендоронезависимая модель должна принять ту форму, в которой она поедет на железо.
И здесь все средства хороши (нет): CLI, NETCONF, RESTCONF, SNMP простихоспаде.
Поэтому нам понадобится драйвер, который результат предыдущего шага переложит в нужный формат конкретного вендора: набор CLI команд, структуру XML. 
Компонент 7. Механизм доставки конфигурации на устройство
Конфигурацию-то мы сгенерировали, но её ещё нужно доставить на устройства — и, очевидно, не руками.
Во-первых, перед нами тут встаёт вопрос, какой транспорт будем использовать? А выбор на сегодняшний день уже не маленький:
- CLI (telnet, ssh)
SNMP- NETCONF
- RESTCONF
- REST API
- OpenFlow (хотя он из списка и выбивается, поскольку это способ доставить FIB, а не настройки)
Давайте тут расставим точки над ё. CLI — это легаси. SNMP… кхе-кхе.
RESTCONF — ещё пока неведомая зверушка, REST API поддерживается почти никем. Поэтому мы в цикле сосредоточимся на NETCONF.
На самом деле, как уже понял читатель, с интерфейсом мы к этому моменту уже определились — результат предыдущего шага уже представлен в формате того интерфейса, который был выбран.
Во-вторых, а какими инструментами мы будем это делать?
Тут выбор тоже большой:
- Самописный скрипт или платформа. Вооружимся ncclient и asyncIO и сами всё сделаем. Что нам стоит, систему деплоймента с нуля построить?
- Ansible с его богатой библиотекой сетевых модулей.
- Salt с его скудной работой с сетью и связкой с Napalm.
- Собственно Napalm, который знает пару вендоров и всё, до свиданья.
- Nornir — ещё один зверёк, которого мы препарируем в будущем.
Здесь ещё фаворит не выбран — будем шупать.
Что здесь ещё важно? Последствия применения конфигурации.
Успешно или нет. Остался доступ на железку или нет.
Кажется, тут поможет commit с подтверждением и валидацией того, что в устройство сгрузили.
Это в совокупности с правильной реализацией NETCONF значительно сужает круг подходящих устройств — нормальные коммиты поддерживают не так много производителей. Но это просто одно из обязательных условий в RFP. В конце концов никто не переживает, что ни один российский вендор не пройдёт под условие 32*100GE интерфейса. Или переживает? 
Компонент 8. CI/CD
К этому моменту у нас уже готова конфигурация на все устройства сети.
Я пишу «на все», потому что мы говорим о версионировании состояния сети. И даже если нужно поменять настройки всего лишь одного свитча, просчитываются изменения для всей сети. Очевидно, они могут быть при этом нулевыми для большинства узлов.
Но, как уже было сказано, выше, мы же не варвары какие-то, чтобы катить всё сразу в прод.
Сгенерированная конфигурация должна сначала пройти через Pipeline CI/CD.
CI/CD означает Continuous Integration, Continuous Deployment. Это подход, при котором команда не раз в полгода выкладывает новый мажорный релиз, полностью заменяя старый, а регулярно инкрементально внедряет (Deployment) новую функциональность небольшими порциями, каждую из которых всесторонне тестирует на совместимость, безопасность и работоспособность (Integration).
Для этого у нас есть система контроля версий, следящая за изменениями конфигурации, лаборатория, на которой проверяется не ломается ли клиентский сервис, система мониторинга, проверяющая этот факт, и последний шаг — выкатка изменений в рабочую сеть.
За исключением отладочных команд, абсолютно все изменения на сети должны пройти через CI/CD Pipeline — это наш залог спокойной жизни и длинной счастливой карьеры. 
Компонент 9. Система резервного копирования и поиска отклонений
Ну про бэкапы лишний раз говорить не приходится. Будем просто их по крону или по факту изменения конфигурации в гит складывать.
А вот вторая часть поинтереснее — за этими бэкапами кто-то должен приглядывать. И в одних случаях этот кто-то должен пойти и вертать всё как было, а в других, мяукнуть кому-нибудь, о том, что непорядок. Например, если появился какой-то новый пользователь, который не прописан в переменных, нужно от хака подальше его удалить. А если новое файрвольное правило — лучше не трогать, возможно кто-то просто отладку включил, а может новый сервис, растяпа, не по регламенту прописал, а в него уже люди пошли.
От некой небольшой дельты в масштабах всей сети мы всё равно не уйдём, несмотря на любые системы автоматизации и стальную руку руководства. Для отладки проблем всё равно никто конфигурацию не будет вносить в системы. Тем более, что их может даже не предусматривать модель конфигурации.
Например, файрвольное правило для подсчёта числа пакетов на определённый IP, для локализации проблемы — вполне рядовая временная конфигурация.

Компонент 10. Система мониторинга
Сначала я не собирался освещать тему мониторинга — всё же объёмная, спорная и сложная тема. Но по ходу дела оказалось, что это неотъемлемая часть автоматизации. И обойти её стороной хотя бы даже без практики нельзя.
Развивая мысль — это органическая часть процесса CI/CD. После выкатки конфигурации на сеть, нам нужно уметь определить, а всё ли с ней теперь в порядке.
И речь не только и не столько о графиках использования интерфейсов или доступности узлов, сколько о более тонких вещах — наличии нужных маршрутов, атрибутов на них, количестве BGP-сессий, OSPF-соседей, End-to-End работоспособности вышележащих сервисов.
А не перестали ли складываться сислоги на внешний сервер, а не сломался ли SFlow-агент, а не начали ли расти дропы в очередях, а не нарушилась ли связность между какой-нибудь парой префиксов?
В отдельной статье мы поразмышляем и над этим. 
Заключение
В качестве основы я выбрал один из современных дизайнов датацентровой сети — L3 Clos Fabric с BGP в качестве протокола маршрутизации.
Строить сеть мы будем на этот раз на Juniper, потому что теперь интерфейс JunOs — это ванлав.
Усложним себе жизнь использованием только Open Source инструментов и мультивендорной сетью — поэтому кроме джунипер по ходу дела выберу ещё одного счастливчика.
План ближайших публикаций примерно такой:
Сначала я расскажу про виртуальные сети. В первую очередь, потому что мне хочется, а во вторую, потому что без этого дизайн инфраструктурной сети будет не очень понятен.
Потом собственно про дизайн сети: топологию, маршрутизацию, политики.
Соберём лабораторный стенд.
Поразмышляем и, может, попрактикуемся в инициализации устройства в сети.
А дальше про каждый компонент в интимных подробностях.
И да, я не обещаю изящно закончить этот цикл готовым решением. 🙂
Полезные ссылки
- Перед тем, как углубляться в серию, стоит почитать книгу Наташи Самойленко Python для сетевых инженеров.
- Полезным будет также почитать RFC про дизайн датацентровых фабрик от Фейсбука за авторством Петра Лапухова.
- О том, как работает Overlay’ный SDN вам даст представление документация по архитектуре Tungsten Fabric (ранее Open Contrail).
Спасибы
- Роман Горге. За комментарии и правки.
- Артём Чернобай. За КДПВ.
Оставайтесь на связи
Пишите нам: info@linkmeup.ru
Канал в телеграме: t.me/linkmeup_podcast
Канал на youtube: youtube.com/c/linkmeup-podcast
Подкаст доступен в iTunes, Google Подкастах, Яндекс Музыке, Castbox
Сообщество в вк: vk.com/linkmeup
Группа в фб: www.facebook.com/linkmeup.sdsm
Добавить RSS в подкаст-плеер.
Пообщаться в общем чате в тг: https://t.me/linkmeup_chat
Поддержите проект:



{kind=link}
 426
426
 53692
53692
 18
18
Ещё статьи


18 коментариев
> Тем более, что их может даже не предусматривать модель конфигурации.
IMHO мониторинг и управление фильтрацией как раз ДОЛЖНО быть изначально предусмотрено в системе управления — это ж ОС состояния сети! Да, получится сложнее, чем изначально сконфигурировать и так и оставить — но зато система среагирует САМА и СРАЗУ, по заранее предусмотренному сценанию.
> Тем более, что их может даже не предусматривать модель конфигурации.
Ссылки на книгу Наташи Самойленко Python для сетевых инженеров и курс не работают (Error 404). Просьба по возможности поправить.
Замечательная задумка и хорошая статья. Спасибо. Жду продолжения. Возможно в ткму будет книга «Автоматизация программируемых сетей» dmkpress.com/catalog/computer/os/978-5-97060-699-5/ (оригинальное издание — Network Programmability and Automation: Skills for the Next-Generation Network Engineer 1st Edition — http://www.amazon.com/Network-Programmability-Automation-Next-Generation-Engineer/dp/1491931256/ref=sr_1_1?ie=UTF8&qid=1543569121&sr=8-1&keywords=Network+Programmability+and+Automation)
Современно, модно, молодежно 🙂
p.s.
Кстати, разве она не должна быть в этой рубрике linkmeup.ru/adsm/?
— хорошо если так и там все «болимени» актуально.
Очень интересное начало, жду продолжение с нетерпением. Будем учиться!
Что такое вайтбокс и блекбокс?
Устройства у которых есть внутренний сервер для API управления и устройства, в которых его нету.
Что такое спайн?
Что такое ToR?
И правда. Спасибо) перенёс.
То-то и оно. Задача в том, чтобы иначе просто не могло быть.
В контексте тестирования whitebox — это когда вы знаете как работает объект и тестирование конкретные функции в нём.
Blackbox — вы не имеете представления что там внутри и тестируете только снаружи — а вот с этого боку молотком ударим — что будет?
Говорят, что это практически как комп без операционки. Какую хочешь, такую и ставь.
толком не понял про что там
http://www.sdxcentral.com/data-center/bare-metal/white-box/definitions/what-is-white-box-networking/
http://www.sdxcentral.com/data-center/definitions/what-are-spine-switches/
Top of Rack (https://www.google.com/search?q=top+of+rack).