





Сети для самых маленьких. Часть четырнадцатая. Путь пакета
 313
313

 96361
96361
 6
6



A forwarding entity always forwards packets in per-flow order to
zero, one or more of the forwarding entity’s own transmit interfaces
and never forwards a packet to the packet’s own receive interface.
Brian Petersen. Hardware Designed Network
Одно из удивительнейших достижений современности — это то, как, сидя в Норильске, человек может чатиться со своим другом в Таиланде, параллельно покупать билет на вечерний самолёт к нему, расплачиваясь банковской картой, в то время, как где-то в Штатах на виртуалочке его бот совершает сделки на бирже со скоростью, с которой его сын переключает вкладки, когда отец входит в комнату.
А через 10 минут он закажет такси через приложение на телефоне, и ему не придётся даже брать с собой в дорогу наличку.
В аэропорту он купит кофе, расплатившись часами, сделает видеозвонок дочери в Берлин, а потом запустит кинцо онлайн, чтобы скоротать час до посадки.
За это время тысячи MPLS-меток будут навешаны и сняты, миллионы обращений к различным таблицам произойдут, базовые станции сотовых сетей передадут гигабайты данных, миллиарды пакетов больших и малых в виде электронов и фотонов со скоростью света понесутся в ЦОДы по всему миру.
Это ли не электрическая магия?
В своём вояже к QoS, теме обещанной многократно, мы сделаем ещё один съезд. На этот раз обратимся к жизни пакета в оборудовании связи.
Вскроем этот синий ящик и распотрошим его.

Кликабельно и увеличабельно.
Сегодня:
-
Коротко о судьбе и пути пакета
-
Плоскости (они же плейны): Forwarding/Data, Control, Management
-
Кто как и зачем обрабатывает трафик
-
Типы чипов: от CPU до ASIC’ов
-
Аппаратная архитектура сетевого устройства
-
Путешествие длиною в жизнь
Забегая вперёд, немного поговорим о плоскостях и введём некоторые определения.
Итак, есть две плоскости весьма чёткое деление архитектуры сетевого устройства на две части: Control и Data Plane. Это элегантное решение, которое годы назад позволило абстрагировать путь трафика от физической топологии, зародив пакетную коммутацию, и которое является фундаментом всей индустрии сегодня.
Data Plane — это пересылка трафика со входных интерфейсов в выходные — чуть ближе к точке назначения. Data Plane руководствуется таблицами маршрутизации/коммутации/меток (далее будем называть их таблицами пересылок). Здесь мет места задержкам — всё происходит быстро.
Control Plane — это уровень протоколов, контролирующих состояние сети и заполняющих таблицы пересылок (BGP, OSPF, LDP, STP, BFD итд.). Тут можно помедленнее — главное — построить правильные таблицы.
Для чего такое разделение оказалось нужным, читайте в соответствующей главе.
Поскольку все предыдущие 14 частей СДСМ были так или иначе про плоскость управления, в этот раз мы будем говорить о плоскости пересылки.
И в первую очередь введём понятие транзитных и локальных пакетов.
Транзитные — это пакеты, обрабатывающиеся исключительно на Data Plane и не требующие передачи на плоскость управления.
Они пролетают через узел быстро и прозрачно.
Преимущественно это пользовательские (клиентские) данные, адрес источника и назначения которых за пределами данного устройства (и, скорее всего, сети провайдера вообще).
Среди транзитного трафика могут быть и протокольные — внутренние для сети провайдера, но не предназначенные данному узлу.
Например, BGP или Targeted LDP.
Локальные делятся на три разных вида:
- Предназначенные приложению на данном устройстве. То есть либо адрес назначения принадлежит ему (настроен на нём). Либо адрес назначения броадкастовый (ARP) или мультикастовый (OSPF Hello), который устройство должно прослушивать.
Здесь важно понимать, что речь об адресе самого внутреннего заголовка пересылки: например, для BGP или OSPF — это IP, для ISIS или STP — MAC. При этом пакет, DIP которого внешний, а DMAC — локальный, остаётся транзитным, поскольку пакет нужно доставить на выходной интерфейс вовне, а не на Control Plane.
- Сгенерированные данным устройством. То есть созданные на ЦПУ, на Control Plane, и отправленные на Data Plane.
- Транзитные пакеты, требующие обработки на плоскости управления. Примерами могут служить пакеты, у которых истёк TTL — нужно генерировать ICMP TTL Expired in Transit. Или пакеты с установленными IP Option: Router Alert или Record Route.
Мы в этой статье поговорим обо всех. Но преимущественно речь будет о транзитных — ведь именно на них провайдер зарабатывает деньги.
1. Коротко о судьбе и пути пакета
Под пакетом будем понимать PDU любого уровня — IP-пакеты, фреймы, сегменты итд. Для нас важно, что это сформированный пакет информации.
Всю статью мы будем рассматривать некий модульный узел, который пересылает пакеты. Для того, чтобы не запутать читателя, определим, что это маршрутизатор.
Все рассуждения данной статьи, с поправками на заголовки, протоколы и конкретные действия с пакетом, применимы к любым сетевым устройствам, будь то маршрутизатор, файрвол или коммутатор — их задача: передать пакет следующему узлу ближе к назначению.
Дабы избежать кривотолков и неуместной критики: автор отдаёт себе отчёт в том, что реальная ситуация зависит от конкретного устройства. Однако задача статьи — дать общее понимание принципов работы сетевого оборудования.
Следующую схему мы выберем в качестве отправной точки.

Независимо от того, что за устройство, как реализована обработка трафика, пакету нужно пройти такой путь.
- Путь делится на две части: входной и выходной тракты.
- На входе происходит сначала декапсуляция — отделение заголовка от полезной нагрузки и прочие присущие протоколу вещи (например, вычисление контрольной суммы)
- Далее стадия входной обработки (Ingress Processing) — сам пакет без заголовка (нагрузка) томится в буфере, а заголовок анализируется. Здесь могут к пакетам применяться политики, происходить поиск точки назначения и выходного интерфейса, создаваться копии итд.
- Когда анализ закончен, заголовок превращается в метаданные (временный заголовок), склеивается с пакетом и они передаются на входную очередь. Она позволяет не слать на выходной тракт больше, чем тот может обработать.
- Далее пакет может ждать (или запрашивать) явное разрешение на перемещение в выходную очередь, а может просто туда передаваться, а там, поди, разберутся.
- Выходных трактов может быть несколько, поэтому пакет далее попадает на фабрику коммутации, цель которой, доставить его на правильный.
- На выходном тракте также есть очередь — выходная. В ней пакеты ожидают выходной обработки (Egress Processing): политики, QoS, репликация, шейпинг. Здесь же формируются будущие заголовки пакета. Также выходная очередь может быть полезной для того, чтобы на интерфейсы не передавать больше, чем они могут пропустить.
- И завершающая стадия — инкапсуляция пакета в приготовленные заголовки и передача его дальше.
Эта упрощённая схема более или менее универсальна.
Немного усложним её, рассмотрев стек протоколов.
Например, IP-маршрутизатор должен сначала из электрического импульса восстановить поток битов, далее распознать, какой тип канального протокола используется, определить границы кадра, снять заголовок Ethernet, узнать что под ним (пусть IP), передать IP-пакет на дальнейшую обработку.
Тогда схема примет такой вид:

- Сначала отработал модуль физического уровня.
- С помощью АЦП восстановил поток битов — в некоторым смысле декапсуляция физического уровня.
- Работая на определённом типе порта (Ethernet), он понимает, что выходным интерфейсом будет модуль Ethernet.
- Далее происходит декапсуляция и Входная Обработка на Ethernet-модуле:
- Определение границ кадра, преамбулы, IFG, FCS
- Подсчёт контрольной суммы
- Снятие заголовков, разбор на поля
- Применение политик
- Определение адреса назначения — он локальный — и тогда выходной интерфейс — к модулю IP.
- Входная обработка IP:
- Снятие заголовков, разбор на поля
- Применение политик
- Анализ адреса назначения
- Поиск выходного интерфейса в Таблице Пересылки
- Формирование временных внутренних заголовков
- Склейка временных заголовков с данными и отправка пакета на выходной тракт.
- Обработка во входной очереди.
- Пересылка через фабрику коммутации.
- Обработка в выходной очереди.
- На выходном тракте модуль IP совершает Выходную Обработку:
- Применение политик, шейпинг
- Формирование конечного заголовка на основе метаданных (временного заголовка) и передача его модулю Ethernet.
- Далее Выходная Обработка на модуле Ethernet
- Поиск в ARP-таблице MAC-адреса следующего узла
- Формирование заголовка Ethernet
- Подсчёт контрольной суммы
- Применение политик
- Спуск на физический модуль.
- А модуль физического уровня в свою очередь разбивает поток битов на электрические импульсы и передаёт в кабель.
*Порядок выполнения операция приблизительный и может зависеть от реализации.
Все перечисленные выше шаги декомпозируются на сотни более мелких, каждый из которых должен быть реализован в железе или в ПО.
Вот и вопрос — в железе или ПО. Он преследует мир IP-сетей с момента их основания и, как это водится, развитие происходит циклически.
Есть вещи тривиальные, для которых элементная база существует… ммм… с 60-х. Например, АЦП, аппаратные очереди или CPU.
А есть те, которые стали прорывом относительно недавно.
Часть функций всегда была и будет аппаратной, часть — всегда будет программной, а часть — мечется, как та обезьяна.
В этой статье мы будем преимущественно говорить об аппаратных устройствах, лишь делая по ходу ремарки по поводу виртуальных.
2. Уровни и плоскости

Мы столько раз прежде использовали эти понятия, что пора им уже дать определения.
В работе оборудования можно выделить три уровня/плоскости:

Forwarding/Data Plane
Плоскость пересылки.
Главная задача сети — доставить трафик от одного приложения другому. И сделать это максимально быстро, как в плане пропускной способности, так и задержек.
Соответственно главная задача узла — максимально быстро передать вошедший пакет на правильный выходной интерфейс, успев поменять ему заголовки и применив политики.
Поэтому существуют заранее заполненные таблицы передачи пакетов — таблицы коммутации, таблицы маршрутизации, таблицы меток, таблицы соседств итд.
Реализованы они могут быть на специальных чипах CAM, TCAM, работающих на скорости линии (интерфейса). А могут быть и программными.
Примеры:
- Принять Ethernet-кадр, посчитать контрольную сумму, проверить есть ли SMAC в таблице MAC-адресов. Найти DMAC в таблице MAC-адресов, определить интерфейс, передать кадр.
- Принять MPLS-пакет, определить входной интерфейс и входную метку. Выполнить поиск в таблице меток, определить выходной интерфейс и выходную метку. Свопнуть. Передать.
- Пришёл поток пакетов. Выходным интерфейсом оказался LAG. Решение, в какие из интерфейсов их отправить, тоже принимается на Forwarding Plane.

Control Plane
Плоскость управления.
Всему голова. Она заранее заполняет таблицы, по которым затем будет передаваться трафик.
Здесь работают протоколы со сложными алгоритмами, которые дорого или невозможно выполнить аппаратно.
Например, алгоритм Дейкстры реализовать на чипе можно, но сложно. Так же сложно сделать выбор лучшего маршрута BGP или определение FEC и рассылку меток. Кроме того, для всего этого пришлось бы делать отдельный чип или часть чипа, которая практически не может быть переиспользована.
В такой ситуации лучше пожертвовать сабсекундной сходимостью в пользу удобства и цены.
Поэтому ПО запускается на CPU общего назначения.
Получается медленно, но гибко — вся логика программируема. И на самом деле скорость на Control Plane не важна. Однажды вычисленный маршрут инсталлируется в FIB, а дальше всё на скорости линии.
Вопрос скорости Control Plane возникает при обрывах, флуктуациях на сети, но он сравнительно успешно решается механизмами TE HSB, TE FRR, IP FRR, VPN FRR, когда запасные пути готовятся заранее на том же Control Plane.
Примеры:
- Запустили сеть с IGP. Нужно сформировать Hello, согласовать параметры сессий, обменяться базами данных, просчитать кратчайшие маршруты, инсталлировать их в Таблицу Маршрутизации, поддерживать контакт через периодические Keepalive.
- Пришёл BGP Update. Control Plane добавляет новые маршруты в таблицу BGP, выбирает лучший, инсталлирует его в Таблицу Маршрутизации, при необходимости пересылает Update дальше.
- Администратор включил LDP. Для каждого префикса создаётся FEC, назначается метка, помещается в таблицу меток, анонсы уходят всем LDP-соседям.
- Собрали два коммутатора в стек. Выбрать главный, проиндексировать интерфейсы, актуализировать таблицы пересылок — задача Control Plane.
Работа и реализация Control Plane универсальна: ЦПУ + оперативная память: работает одинаково хоть на стоечных маршрутизаторах, хоть на виртуальных сетевых устройствах.
Эта система — не мысленный эксперимент, не различные функции одной программы, это действительно физически разделённые тракты, которые взаимодействуют друг с другом.
Началось всё с разнесения плоскостей на разные платы. Далее появились стекируемые устройства, где одно выполняло интеллектуальные операции, а другое было лишь интерфейсным придатком.
Вчерашний день — это системы вроде Cisco Nexus 5000 Switch + Nexus 2000 Fabric Extender, где 2000 выступает в роли выносной интерфейсной платы для 5000.
Где-то в параллельной Вселенной тихо живёт SDN разлива 1.0 — с Openflow-like механизмами, где Control Plane вынесли на внешние контроллеры, а таблицы пересылок заливаются в совершенно глупые коммутаторы.
Наша реальность и ближайшее будущее — это наложенные сети (Overlay), настраиваемые SDN-контроллерами, где сервисы абстрагированы от физической топологии на более высоком уровне иерархии.
И несмотря на то, что с каждой статьёй мы всё глубже погружаемся в детали, мы учимся мыслить свободно и глобально.
Разделение на Control и Forwarding Plane позволило отвязать передачу данных от работы протоколов и построения сети, а это повлекло значительное повышение масштабируемости и отказоустойчивости.
Так один модуль плоскости управления может поддерживать несколько интерфейсных модулей.
В случае сбоя на плоскости управления механизмы GR, NSR, GRES и ISSU помогают плоскости пересылки продолжать работать будто ничего и не было.
Management Plane
Плоскость или демон наблюдения. Не всегда его выделяют в самостоятельную плоскость, относя его задачи к Control Plane, а иногда, выделяя, называют Monitoring.
Этот модуль отвечает за конфигурацию и жизнедеятельность узла. Он следит за такими параметрами, как:
- Температура
- Утилизация ресурсов
- Электропитание
- Скорость вращения вентиляторов
- Работоспособность плат и модулей.
Примеры:
- Упал интерфейс — генерируется авария, лог и трап на систему мониторинга
- Поднялась температура чипа — увеличивает скорость вращения вентиляторов
- Обнаружил, что одна плата перестала отвечать на периодические запросы — выполняет рестарт плат — вдруг поднимется.
- Оператор подключился по SSH для снятия диагнонстической информации — CLI также обеспечивается Control Plane’ом.
- Приехала конфигурация по Netconf — Management Plane проверяет и применяет её. При необходимости инструктирует Control Plane о произошедших изменениях и необходимых действиях.
Итак: Forwarding Plane — передача трафика на основе таблиц пересылок — собственно то, из чего оператор извлекает прибыль.
Control Plane — служебный уровень, необходимый для формирования условий для работы Forwarding Plane.
Management Plane — модуль, следящий за общим состоянием устройства.
Вместе они составляют самодостаточный узел в сети пакетной коммутации.
Разделение на Control и Forwarding/Data Plane — не абстрактное — их функции действительно выполняют разные чипы на плате.
Так Control Plane обычно реализован на связке CPU+RAM+карта памяти, а Forwarding Plane на ASIC, FPGA, CAM, TCAM.
Но в мире виртуализации сетевых функций всё смешалось — эту ремарку я буду делать до конца статьи.
3. История способов обработки трафика
Сейчас с Forwarding Plane всё отлично: 10 Гб/с, 100 Гб/с — не составляют труда — плати и пользуйся. Любые политики без влияния на производительность. Но так было не всегда.
В чём сложности?
В первую очередь это вопрос организации вышеописанных трактов: что делать с электрическим импульсом из одного кабеля и как его передать в другой — правильный.
Для этого на сетевых устройствах есть букет разнообразных чипов.

Это пример интерфейсной платы Cisco
Так, например, микросхемы (ASIC, FPGA) выполняют простые операции, вроде АЦП/ЦАП, подсчёта контрольных сум, буферизации пакетов.
Ещё нужен модуль, который умеет парсить, анализировать и формировать заголовки пакетов.
И модуль, который будет определять, куда, в какой интерфейс, пакет надо передать. Делать это нужно для каждого божьего пакета.
Кто-то должен также следить и за тем, можно ли этот пакет пропускать вообще. То есть проверить его на предмет подпадания под ACL, контролировать скорость потока и отбросить, если она превышена.
Сюда же можно вписать и более комплексные функции трансляции адресов, файрвола, балансировки итд.
Исторически все сложные действия выполнялись на CPU. Поиск подходящего маршрута в таблице маршрутизации был реализован как программный код, проверка на удовлетворение политикам — тоже. Процессор с этим справлялся, но только он с этим и справлялся.
Чем это грозит понятно: производительность будет падать тем сильнее, чем больше трафика устройство должно перемалывать и чем больше функций мы будем вешать на него. Поэтому одна за другой большинство функций были делегированы на отдельные чипы.
И из обычного x86-сервера маршрутизаторы превратились в специализированные сетевые коробки, набитые непонятными деталями и интерфейсами. А Ethernet-хабы переродились в интеллектуальные коммутаторы.
Функции по парсингу заголовков и их анализу, а также поиску выходного интерфейса взяли на себя ASIC, FPGA, Network Processor.
Обработка в очередях, обеспечение QoS, управление перегрузками — тоже специализированные ASIC.
Такие вещи, как стейтфул файрвол, остались на ЦПУ, потому что количество сессий несъедобное.
Другой вопрос: мы где-то должны хранить таблицы коммутации. В чём-то быстром.
Первое, что приходит в голову — это классическая оперативная память.
Проблема с ней в том, что обращение к ней идёт по адресу ячейки, а возвращает она уже её содержимое (или контент, не по-русски если).
Однако входящий пакет несёт в себе никак не адрес ячейки памяти, а только MAC, IP, MPLS.
Тогда бы нам пришлось иметь некий хэш алгоритм, который, задействуя CPU, высчитывал бы адрес ячейки и извлекал оттуда нужные данные.
Вот только пропускная способность порта в 10 Гб/с означает, что CPU должен передавать 1 бит каждые 10 нс. И у него есть порядка 80 мкс, чтобы передать пакет размером в один килобайт.
Впрочем, вычисление хэша — алгоритм очень простой, и любой мало-мальски уважающий себя ASIC с этим справится. Инженерам был адресован вопрос — а что дальше делать с хэшем?
Так появилась память CAM — Content Addressable Memory. Её адреса — это хэши значений. В своей ячейке CAM содержит или ответное значение (номер порта, например) или чаще адрес ячейки в обычной RAM.
То есть пришёл Ethernet-кадр, ASIC’и его разорвали на заголовки, вытащили DMAC — прогнали его через CAM и получили вожделенный исходящий интерфейс. Подробнее о CAM дальше.
Что с тобой не так, IP?!
Я не зря взял в пример Ethernet-кадр. С IP совсем другая история.
MAC-коммутация — это просто: ни тебе агрегации маршрутов, ни тебе Longest Prefix Match — только 48 уникальных бит.
А вот в IP это всё есть. У нас может быть несколько маршрутов в Таблице Маршрутизации с разными длинами масок и выбрать нужно наидлиннейшую. Это базовый принцип IP-маршрутизации, с которым не поспоришь и не обойдёшь. Кроме того есть сложные ACL с их Wildcard-масками.
Долгое время решения этой проблемы не существовало. На заре сетей с пакетной коммутацией IP-пакеты обрабатывались на CPU. И главная проблема этого — даже не коммутация на скорости линии (хотя и она тоже), а влияние дополнительных настроек на производительность. Вы и сейчас можете это увидеть на каком-нибудь домашнем микротике, если настроить на нём с десяток ACL — сразу заметите, как просядет пропускная способность. Интернет разрастался, политик становилось всё больше, а требования к пропускной способности подпрыгивали скачкообразно, и CPU становился камнем преткновения. Тем более учитывая, что поиск маршрута подчас приходилось делать не один раз, а рекурсивно погружаться всё глубже.
Так в лихие 90-е зародился MPLS. Какая блестящая идея — построить заранее путь на Control Plane. Адресацией в MPLS будет метка фиксированной длины, и соответственно нужна единственная запись в таблице меток, что с пакетом дальше делать. При этом мы не теряем гибкости IP, поскольку он лежит в основе, и можем использовать CAM. Плюс заголовок MPLS — короток (4 байта против 20 в IP) и предельно прост.
Однако по иронии судьбы в то же время инженеры совершили прорыв, разработав TCAM — Ternary CAM. И с тех пор ограничений уже почти не было (хотя не без оговорок).
Подробнее от TCAM дальше.
Что же до MPLS, который ввиду данного события должен был скоропостижно скончаться, едва родившись, то он прорубил себе дверь в другой дом. Но об этом мы уже наговорились.
О дивный новый мир
В последнее десятилетие вокруг SDN и NFV поднялся небезосновательный хайп. Развитие виртуализации и облачных сервисов, как её квинтэссенция, предъявляет к сети такие требования, которые не могут удовлетворить традиционные устройства и подходы.
- Нужна маршрутизация и коммутация в пределах одного сервера между различными виртуалками.
- Горизонтальная масштабируемость требует возможности запускать новые виртуалки в любой части сети, а соответственно и адаптировать её конфигурацию.
- Цепочка услуг (Service Chain), такая как Anti-DDoS, IDS/IPS, FW предполагает маршрутизацию, управляемую программно и автоматическую настройку сетевых узлов.
Поэтому большая часть сетевой инфраструктуры ЦОДов сейчас виртуализируется. А это предполагает переход от аппаратной архитектуры к гибридной. CAM, TCAM, NP, ASIC сейчас заменяются на связку DPDK с более умными сетевыми картами, которые тоже поддерживают виртуалиацию — SR-IOV — и забирают на свои чипы некоторую часть рутинной работы.
Кроме того, с развитием алгоритмических методов поиска, сегодня сокращается необходимость в CAM/TCAM на традиционных коммутаторах и маршрутизаторах.
Таким образом мы снова становимся свидетелями сдвига парадигмы в вопросе реализации Forwarding Plane.
Но мы пока остаёмся в сфере аппаратной пересылки и теперь давайте подробнее обо всех чипах.
4. Типов-чипов
Я не ставлю целью данной статьи описать все существующие чипы — только те, что используются в сетевом оборудовании.
CPU — Central Processing Unit
Самый медленный, но самый гибкий элемент устройства — центральный процессор.
Он занимается обработкой протокольных пакетов и сложного поведения.

Его прелесть в том, что он управляется запущенными приложениями и «многозадачен». Логику легко изменить, просто поправив программный код.
Такие вещи, как SPF, установка соседства по всем протоколам, генерация логов, аварий, подключение к пользовательским интерфейсам управления — все действия со сложной логикой — происходят на нём.
Собственно, поэтому, например, вы можете наблюдать, что при высокой загрузке CPU становится некомфортно работать в консоли. Хотя трафик при этом ходит уверенно.
CPU берёт на себя функции Control Plane.
На устройствах с программной пересылкой, участвует также и в Forwarding Plane.
CPU может быть один на весь узел, а может быть отдельно на каждой плате в шасси при распределённой архитектуре.
Результаты своей работы CPU записывает в оперативную память ↓.
RAM — Random Access Memory
Классическая оперативная память — куда без неё?

Мы ей адрес ячейки — она нам содержимое.
В ней хранятся, так называемые Soft Tables (программные таблицы) — таблицы маршрутизации, меток, MAC-адресов.
Когда вы выполняете команду «show ip route», запрос идёт именно в оперативку к Soft Tables.
CPU работает именно с оперативной памятью — когда он посчитал маршрут, или построил LSP — результат записывается в неё. А уже оттуда изменения синхронизируются в Hard Tables в CAM/TCAM↓.
Кроме того, периодически происходит синхронизация всего содержимого всех таблиц на случай, если вдруг по какой-то причине инкрементальные изменения не спустились корректно.
Soft Tables не может быть непосредственно использован для передачи данных, потому что слишком медленно — обращение к оперативке идёт через ЦПУ и требуется алгоритмический поиск, затратный по времени. С оговоркой на NFV.
Кроме того на чипах RAM (DRAM) реализованы очереди: входные, выходные, интерфейсные.
CAM — Content-Addressable Memory
Это особо-хитрый вид памяти.
Вы ей — значение, а она вам — адрес ячейки.
Content-Addressable означает, что адресация базируется на значениях (содержимом).

Значением, например, может быть, например DMAC. CAM прогоняет DMAC по всем своим записям и находит совпадение. В результате CAM выдаст адрес ячейки в классической RAM, где хранится номер выходного интерфейса. Дальше устройство обращается к этой ячейке и отправляет кадр, куда положено.
Для достижения максимальной скорости CAM и RAM располагаются очень близко друг к другу.
Не путать данную RAM с RAM, содержащей Soft Tables, описанной выше — это разные компоненты, расположенные в разных местах.

Прелесть CAM в том, что она возвращает результат за фиксированное время, не зависящее от количества и размера записей в таблице — О(1), выражаясь в терминах сложностей алгоритмов.
Достигается это за счёт того, что значение сравнивается одновременно со всеми записями. Одновременно! А не перебором.
На входе каждой ячейки хранения в CAM стоят сравнивающие элементы (мне очень нравится термин компараторы), которые могут выдавать 0 (разомкнуто) или 1 (замкнуто) в зависимости от того, что на них поступило и что записано. В сравнивающих элементах записаны как раз искомые значения.
Когда нужно найти запись в таблице, соответствующую определённому значению, это значение прогоняется одновременно через ВСЕ сравнивающие элементы. Буквально, электрический импульс, несущий значения, попадает на все элементы, благодаря тому, что они подключены параллельно. Каждый из них выполняет очень простое действие, выдавая для каждого бита 1, если биты совпали, и 0, если нет, то есть замыкая и размыкая контакт. Таким образом та ячейка, адресом которой является искомое значение, замыкает всю цепь, электрический сигнал проходит и запитывает её.
Вот архитектура такой памяти:

Вот пример работы
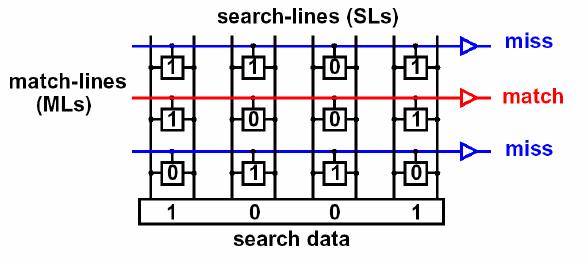
Картинка из прелюбопытнейшего документа.
А это схема реализации:
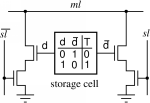
Это чем-то похоже на пару ключ-замок. Только ключ с правильной геометрией может поставить штифты замка в правильные положения и провернуть цилиндр.
Вот только у нас много копий одного ключа и много разных конфигураций замков. И мы вставляем их все одновременно и пытаемся провернуть, а нужное значение лежит за той дверью, замок которой ключ откроет.
Для гибкого использования CAM мы берём не непосредственно значения из полей заголовков, а вычисляем их хэш.
Хэш-функция используется для следующих целей:
- Длина результата значительно меньше, чем у входных значений. Так пространство MAC-адресов длиной 48 бит можно отобразить в 16-ибитовое значение, тем самым в 2^32 раза уменьшив длину значений, которые нужно сравнивать, и соответственно, размер CAM. Основная идея хэш-функции в том, что результат её выполнения для одинаковых входных данных всегда будет одинаков (например, как остаток от деления одного числа на другое — это пример элементарной хэш функции).
- Результат её выполнения на всём пространстве входных значений — это ± плоскость — все значения равновероятны. Это важно для снижения вероятности конфликта хэшей, когда два значения дают одинаковый результат. Конфликт хэшей, кстати, весьма любопытная проблема, которая описана в парадоксе дней рождения. Рекомендую почитать Hardware Defined Networking Брайна Петерсена, где помимо всего прочего он описывает механизмы избежания конфликта хэшей.
- Независимо от длины исходных аргументов, результат будет всегда одной длины. То есть на вход можно подать сложное сочетание аргументов, например, DMAC+EtherType, и для хранения не потребуется выделять более сложную структуру памяти.
Именно хэш закодирован в сравнивающие элементы. Именно хэш искомого значения будет сравниваться с ними.
По принципу CAM схож с хэш-таблицами в программировании, только реализованными на чипах.
В этот принцип отлично укладывается также MPLS-коммутация, почему MPLS и сватали в своё время на IP.
Например:
- Пришёл самый первый Ethernet-кадр на порт коммутатора.
- Коммутатор извлёк SMAC, вычислил его хэш.
- Данный хэш он записал в сравнивающие элементы CAM, номер интерфейса откуда пришёл кадр в RAM, а в саму ячейку CAM адрес ячейки в RAM.
- Выполнил рассылку изначального кадра во все порты.
- Повторил пп. 1-5 ….
- Заполнена вся таблица MAC-адресов.
- Приходит Ethernet-кадр. Коммутатор сначала проверяет, известен ли ему данный SMAC (сравнивает хэш адреса с записанными хэшами в CAM) и, если нет, сохраняет.
- Извлекает DMAC, считает его хэш.
- Данный хэш он прогоняет через все сравнивающие элементы CAM и находит единственное совпадение.
- Узнаёт номер порта, отправляет туда изначальный кадр.
Резюме:
- Ячейки CAM адресуются хэшами.
- Ячейки CAM содержат (обычно) адрес ячейки в обычной памяти (RAM), потому что хранить конечную информацию — дорого.
- Каждая ячейка CAM имеет на входе сравнивающий элемент, который сравнивает искомое значение с хэш-адресом. От этого размер и стоимость CAM значительно больше, чем RAM.
- Проверка совпадения происходит одновременно во всех записях, отчего CAM дюже греется, зато выдаёт результат за константное время.
- CAM+RAM хранят Hard Tables (аппаратные таблицы), к которым обращается чип коммутации.
TCAM — Ternary Content-Addressable Memory
Возвращаемся к вопросу, что не так с IP.
Если мы возьмём описанный выше CAM, то на любой DIP он очень редко сможет вернуть 1 во всех битах.
Дело в том, что DIP — это всегда один единственный адрес, а маршруты в таблице маршрутизации — это подсеть или даже агрегация более мелких маршрутов. Поэтому полного совпадения быть почти не может — кроме случая, когда есть маршрут /32.
Перед разработчиками чипов стояло два вопроса:
- Как это в принципе реализовать?
- Как из нескольких подходящих маршрутов выбрать лучший (с длиннейшей маской)?

Ответом стал TCAM, в котором «T» означает «троичный»». Помимо 0 и 1 вводится ещё одно значение Х — «не важно» (CAM иногда называют BCAM — Binary, поскольку там значения два — 0 и 1). Тогда результатом поиска нужной записи в таблице коммутации будет содержимое той ячейки, где самая длинная цепочка 1 и самая короткая «не важно».
Например, пакет адресован на DIP 10.10.10.10.
В Таблице Маршрутизации у нас следующие маршруты:
0.0.0.0/0
10.10.10.8/29
10.10.0.0/16
10.8.0.0/13
Другие.В сравнивающие элементы TCAM записываются биты маршрута, если в маске стоит 1, и «не важно», если 0.
При поиске нужной записи TCAM, как и CAM, прогоняет искомое значение одновременно по всем ячейкам. Результатом будет последовательность 0, 1 и «не важно».
Только те записи, которые вернули последовательность единиц, за которыми следуют «не важно» участвуют в следующем этапе селекции.
Далее из всех результатов выбирается тот, где самая длинная последовательность единиц — так реализуется правило Longest prefix match.
Очевидно, что мы-то своим зорким взглядом, сразу увидели, что это будет маршрут 10.10.10.8/29.

Решение на грани гениальности, за которое пришлось заплатить большую цену. Из-за очень высокой плотности транзисторов (у каждой ячейки их свой набор, а ячеек должны быть миллионы) они греются не меньше любого CPU — нужно решать вопрос отвода тепла.
Кроме того, их производство стоит очень дорого, и не будет лукавством сказать, что стоимость сетевого оборудования и раньше и сейчас определяется именно наличием и объёмом TCAM.
Внимательный читатель обратил внимание на вопрос хэш-функций — ведь она преобразует изначальный аргумент во что-то совершенно непохожее на исходник, как же мы будем сравнивать 0, 1 и длины? Ответ: хэш функция здесь не используется. Описанный выше алгоритм — это сильное упрощения реальной процедуры, за деталями этого любознательного читателя отправлю к той же книге Hardware Defined Networking.
Однако память — это память — всего лишь хранит. Сама она трафик не передаёт — кто-то с ней должен взаимодействовать.
Автору не удалось найти общепринятые термины для обозначения тех или иных компонентов, поэтому он взял на себя смелость пользоваться собственным терминологическим аппаратом. Однако он готов в любой момент прислушаться к рекомендациям и адаптировать статью к универсальным определениям.
Тот компонент, который занимается передачей пакетов, называется чипом коммутации — FE — Forwarding Engine. Именно он парсит заголовки, запрашивает информацию в TCAM и перенаправляет пакеты к выходному интерфейсу. Работа с пакетом декомпозируется на множество мелких шагов, каждый из которых должен выполняться на скорости линии, и совокупное время отработки тракта должно быть адекватным требованиям сети.
Реализован FE может быть на Сетевых Процессорах (NP), FPGA и элементарных ASIC или их последовательности.
Вот с элементарных ASIC и начнём.
ASIC — Application Specific Integrated Circuit
Как следует из названия, это микросхема, решающая узкий спектр специфических задач. Алгоритм работы зашит в неё и не может быть изменён в дальнейшем.

Соответственно, на ASIC ложатся рутинные операции, которые никогда не поменяются со временем.
ASIC занимается: АЦП, подсчёт контрольной суммы кадра, восстановление синхросигнала из Ethernet, сбор статистики принятых и отправленных пакетов. Например, мы наверняка знаем, где в кадре поле DMAC, его длину, как различить броадкастовые кадры, мультикастовые и юникастовые. Эти фундаментальные константы никогда не поменяются, поэтому функции, их использующие, могут быть алгоритмизированы аппаратно, а не программно.
Процесс разработки и отладки ASIC достаточно трудоёмок, поскольку в финальном чипе нет места ошибкам, зато когда он завершён, их можно отгружать камазами.
ASIC стоит дёшево, потому что производство простое, массовое, вероятность ошибки низкая, а рынок сбыта огромный.
Согласно документации Juniper, на части устройств их PFE (Packet Forwarding Engine) основан на последовательности ASIC’ов и не использует более сложных микросхем.
Хорошим примером использования ASIC’ов сегодня могут служить фермы по майнингу криптовалют. Эволюция привела этот процесс от CPU через кластеры GPU к ASIC’ам, специализированным исключительно на майнинге, что позволило, уменьшить размер, энергопотребление и тепловыделение, сделав процесс значительно дешевле и невероятно масштабируемым, напрочь сметя доморощенных крипто-бизнесменов с карты конкурентов.
Programmable ASIC
В последние годы наблюдается тенденция к реализации большинства функций на ASIC. Однако хочется оставить возможность программировать поведение. Поэтому появились так называемые Программируемые ASIC, которые обладают низкой стоимостью, высокой производительность и некоторой грибкостью.

FPGA — Field Programmable Gate Array
Не всё по силам ASIC’ам. Всё, что касается минимального интеллекта и возможности повлиять на поведение чипа — это к FPGA.

Это программируемая микросхема, в которую заливается прошивка, определяющая её роль в оборудовании.
Как и ASIC, FPGA изначально нацелен на решение какой-то задачи.
То есть FPGA для пакетной сети и для управления подачей топлива в инжектор двигателя — вещи разные и прошивкой одно в другое не превратишь.
Итак, имеем специализированный чип с возможностью управлять его поведением и модернизировать алгоритмы.
FPGA может использоваться для маршрутизации пакетов, перемаркировки, полисинга, зеркалирования.
Например, извне мы можем сообщить чипу, что нужно отлавливать все BGP и LDP пакеты, отправляемые на CPU, в .pcap файл.
Зачем здесь гибкость и возможность программирования? Примеров много:
- ситуация выше, где нужно заложить в него новое правило полисинга, зеркалирования, маркировки
- внедрения нового функционала
- активация лицензируемой опции
- модернизация существующих алгоритмов
- добавление нового правила для анализа полей заголовков, например, для обработки нового протокола.
Получается без разработки новых чипов, перепайки транзисторов, выбраковывания целых партий, просто новой прошивкой можно сделать всё вышеприведённое и больше.
Опять же, если обнаружена неисправность, то можно написать патч для ПО, который сможет её починить, и при этом обновить только конкретно данный чип, без влияния на всю остальную систему.
FPGA значительно дороже в разработке и производстве, главным образом из-за заранее заложенной гибкости.
Из-за гибкости возможностей FPGA иногда используются для обкатки какой-либо новой технологии, когда с помощью прошивки можно менять поведение компонента. И когда логика обкатана, можно запускать в производство ASIC, реализующий её.
NP — Network Processor
В оборудовании операторского класса, где требования как к пропускной способности, так и к протоколам, запущенным на устройстве, довольно высоки, часто используются специализированные чипы — сетевые процессоры — NP. В некотором смысле можно считать их мощными FPGA, направленными именно на обработку и передачу пакетов.

Крупные телеком-вендоры разрабатывают свои собственные процессоры (Cisco, Juniper, Huawei, Nokia), для производителей помельче существуют предложения от нескольких гигантов, вроде Marvell, Mellanox.
Вот например презентация нового NP-чипа Cisco 400Gb/s Full-duplex: тыц. А это описание работы чипсета Juniper Trio, который однако позиционируется, как NISP (Network Instruction Set Processor), а не NP: тыц.
Немного маркетинга и суперэффектное видео о Nokia FP4: тыц
Задачи и возможности примерно те же, что и у FPGA. Дьявол кроется в деталях, куда мы уже не полезем.
5. Аппаратная архитектура коммутирующего устройства
Обычно всё-таки даже на недорогих коммутаторах не практикуют реализацию всего и вся на одном чипе. Это скорее, каскад из разных их типов, каждый из которых решает какую-то часть общей задачи.
Дальше мы посмотрим на референсную модель, как это «может» работать.
Для этой модели возьмём модульное шасси, состоящее из интерфейсных и управляющих модулей и фабрики коммутации.

Работать оно будет со стандартной связкой IP, Ethernet.
Общая шина
Общая шина (она же Back Plane, она же Midplane) устройства, связывающая друг с другом все модули.
Обычно, это просто батарея медных контактов без каких-либо микросхем.




Управляющий модуль

На нём расположены CPU, оперативная память, постоянная память для хранения ПО, конфигурации и логов, интерфейсы для управления.
Он отвечает за Management Plane и за Control Plane.
С ним мы работаем, когда подключаемся к устройству по telnet/ssh.
Он загружает ПО в оперативную память и запускает все другие модули при подаче питания.
Он следит за Heart beat других модулей — специальными пакетами, получение которых говорит о том, что модуль жив и работоспособен.
Он же может перезагрузить модуль, если Heart beat не получил (как программно, так и выключить питание на плате).
Протокольные пакеты доставляются на CPU и тот, обрабатывав их, совершает какое-то действие, как то: записать обновления в таблицы коммутации, сформировать ответный пакет, запросить информацию о каком-либо компоненте итд.
Управляющий модуль занимается расчётом SPF, LSP, установлением соседств по разным протоколам. Он записывает таблицы коммутации в Soft Tables оперативной памяти.




Интерфейсный модуль или линейная карта
Это модуль, который несёт на себе физические интерфейсы и FE (чип коммутации) и выполняет функции Forwarding Plane.


Модуль состоит из многих компонентов, которые могут быть реализованы как в одном чипе (System-on-Chip), так и на множестве отдельных в зависимости от класса устройства и архитектуры.

PIC — Physical Interface Card
На PIC находятся интерфейсы и чип, который выполняет базовые операции с трафиком:
- Восстанавливает битовый поток из электрических импульсов
- Восстанавливает пакет из набора битов.
- Удаляет служебную информацию (как то: преамбула, IFG).
- Вычисляет контрольную сумму и
- а) если она бьётся со значением в пакете, пропускает его, удалив лишние заголовки, например FCS.
- б) если не бьётся — отбрасывает пакет и увеличивает счётчик отброшенных пакетов с ошибкой.
- Подсчитывает статистику:
- количество пакетов
- общий объём трафика
- пиковые значения
- утилизация порта
- количество Unicast/Broadcast/Multicast
- PIC также может восстановить сигнал SynchroEthernet, если необходимо.
В случае, если линейная плата модульная, то интерфейсная карта будет извлекаемой и заменяемой.

Обычно чипы PIC — это ASIC.
FE — Forwarding Engine
Как уже было описано выше, он реализует такие функции, как:
- Запросы к CAM/TCAM
- Трансформация Soft Table в Hard Table
- Принятие решения о передаче пакета (ACL, полисинг)
- Коммутация/Маршрутизация
- Маркировка приоритетов
- Зеркалирование
- Обнаружение протокольных пакетов
- Обработка сигналов/пакетов от CPU.
Далее ВНИМАНИЕ! Это один из наиболее важных моментов всей статьи!
Во-первых, FE делится на Ingress FE и Egress FE. Первый обрабатывает соответственно пакеты на входном тракте, второй — на выходном.
С одной стороны это разделение терминологическое — пакет пришёл на Ingress FE и далее должен быть отправлен на Egress FE, возможно, другой платы.
С другой, разделение — зачастую вполне физическое: внутри одного FE чипа живут эти две сущности: Ingress и Egress. Это и логично — ведь плата может быть как точкой входа, так и точкой выхода.
Во-вторых, именно входной FE определяет всю дальнейшую судьбу пакета в пределах узла:
- Вид будущих заголовков
- Приоритет внутри узла и при передаче вовне
- Выходной FE и интерфейс
- Какой именно из физических членов LAG или ECMP
* с небольшой оговоркой, что выходной тракт всё-таки может ещё произвести репликацию пакета или зарезать его из-за переполненного буфера.
В-третьих, FE должен идентифицировать протокольные пакеты в транзитном трафике и передавать их на CPU.
Соответственно и получать пакеты (или инструкции) от CPU — тоже его работа.
Рядом с FE находятся CAM, TCAM и RAM, куда FE обращается в поиске выходного интерфейса и проверки ACL.
Они хранят Hard Tables. Кроме того Ingress FE производит репликацию BUM трафика — он рассылает по одной копии пакета на каждый Egress FE. А Egress FE уже делает столько копий, во сколько интерфейсов нужно отправить
QoS или TM — Traffic Management
Иногда в самом FE, иногда как отдельный чип, дальше идёт чип QoS, совмещённый с очередью, вместе обычно носящие название Traffic Management.
Входная очередь (очередь на входном тракте) нужна для того, чтобы не переполнить выходную (очередь на выходном тракте).
Выходная очередь предназначена для избежания явления, известного, как Back Pressure — когда на чип FE пакеты поступают быстрее, чем он в состоянии обработать. Такая ситуация невозможна с Ingress FE, потому что к нему подключено такое количество интерфейсов, что трафик от них он в состоянии переварить, либо Ethernet через Flow Control возьмёт ситуацию под свой Control.
А вот на Egress FE трафик может сливаться со многих разных плат (читай Ingress FE) — и ему захлебнуться — это как два байта переслать.
Задача очереди не только сгладить всплески трафика, но и управляемо дропать пакеты, когда это становится неизбежным. А именно — выкидывать из очереди низкоприоритетные пакеты с бо́льшей вероятностью, чем высокоприоритетные. Причём отслеживать перегрузку желательно на уровне интерфейсов — ведь если через дестятигигабитный интерфейс нужно отправить 13 Гб/с трафика, то 3 из них однозначно будет отброшено, а четырёхсот-гигабитный FE при этом даже близок к перегрузке не будет.
Схема достаточно усложняется — две очереди, а значит, двойная буферизация, более того как-то надо по интерфейсам их подробить, встаёт ещё вопрос такой: а если один интерфейс перегружен, то вся входная очередь встанет? Эти сложности никак не разрешались ранее, однако сегодня они адресованы механизму VOQ — Virtual Output Queue. VOQ прекрасно описан вот в этой заметке.
В двух словах — это виртуализация всех очередей между различными FE. Имеется один физический чип памяти DRAM на входном тракте, который внутри разбит на виртуальные очереди. Количество входных очередей — по общему числу выходных. Выходная очередь больше не распологается реально на выходном модуле — она в том же самом DRAM — только виртуальная.
Таким образом (возьмём пример Juniper), если есть 72 выходных интерфейса по 8 очередей на каждом, итого получается 576 входных очередей на каждом интерфейсном модуле (читай TM). Если на устройстве 6 модулей, то оно должно поддерживать 3456 VOQ.
Это элегантно снимает вопрос двойной буферизации и проблем Head of Line Blocking, когда одна выходная очередь в момент перегрузки блокирует всю физическую входную — теперь с VOQ только ту виртуальную, которая с ней связана.


Кроме того пакет теперь отбрасывается при необходимости на входной очереди, и не нужно его отправлять на фабрику и забивать выходные очереди.
Что ещё важно знать про очереди, так это то, что даже те пакеты, которые предназначены на другой интерфейс этого же FE, должны пройти через входную и выходную очереди.
Это нужно для той же самой борьбы с Back Pressure. Только очереди могут защитить FE от перегрузок и отбрасывать лишний трафик согласно приоритетам, поэтому никакого прямого мостика для транзитного трафика между Ingress FE и Egress FE не предусмотрено.
На фабрику однако такой «локальный» трафик попадать не должен.
Но про QoS мы ещё поговорим в следующей части.
SerDes — Serializer, Deserializer
Ещё один чип на интерфейсной плате — SerDes. В случае, когда чипов коммутации несколько — между ними нужно организовать связность каждый-с-каждым. Для этого используются фабрики коммутации и, как оказалось, лучше всего она работает не с пакетами, а с ячейками одинаковой длины. Задача SerDes — распилить пакеты на ячейки перед отправкой на фабрику и собрать их потом обратно — Сериализовать и Десериализовать.
Распределённая плоскость упраления (Distributed Control Plane)
В случае распределённой архитектуры Control Plane на интерфейсной плате также могут располагаться ЦПУ и оперативная память. В этом случае большую часть работы на Control Plane может выполнять местный ЦПУ, разгружая тот, что расположен на управляющей плате.



Фабрика коммутации

Если мы возьмём Hi-End маршрутизатор операторского класса, то обычно в нём может насчитываться до двух десятков интерфейсных плат, в каждой из которых установлен как минимум один чип коммутации FE. Каждый чип коммутации смотрит частью своих ног в сторону интерфейсов, а частью в сторону задней шины. И ног там предостаточно, потому что медная среда имеет свой предел по пропускной способности — нам не хватит одного-двух выходов.

Как связать друг с другом два чипа коммутации? Ну просто же:

Как связать друг с другом три чипа? Ну, наверное, как-то так?

Как связать 8?

Уверены? Ничего не смущает?
Пропускная способность системы из 8 чипов остаётся той же, что и у пары — ведь каждый раз мы уменьшаем количество ног для связи.
Второй момент, как нам вообще создать полносвязную топологию, если чипов, допустим, 16, и каждый из них имеет по 32 контакта? 16*15/2 пучков кабелей по 32 жилы в каждом?
Эта проблема была адресована неблокирующимся сетям Клоза или сетям без переподписки.
У нас есть входные коммутационные элементы (Ingress FE), выходные (Egress FE) и транзитные. Задача транзитных — связать входные с выходными. Любой входной связан с любым выходным через транзитный.

Входные и выходные не связаны друг с другом напрямую, транзитные также не имеют связи.
Нужно больше входных и выходных коммутационных элементов — добавляем транзитных. Нужно ещё больше? Добавляем новый каскад транзитных:

Вот этим и напичканы платы коммутации в современных маршрутизаторах — очень тупые ASIC, которые только и умеют, что быстро перекладывать пакеты со входа на выход.
Плата коммутации подключается к задней шине и имеет связность со всеми другими платами.
Обычно они работают в режиме N+1 — то есть все разделяют нагрузку, но при выходе из строя одной платы, оставшиеся берут всё на себя.
Кстати, сами платы можно вполне назвать верхним каскадом иерархии фабрики Клоза.
Остался только вопрос по ячейкам. Ну и перекладывали бы эти ASICи пакеты сразу, зачем их ещё нарезать?
Здесь можно провести аналогию с ECMP. Если кто-то когда-либо настраивал попакетную балансировку между различными путями, то он, наверняка, помнит, сколько боли это доставляло. Неупорядоченная доставка пакетов, с которой с горем пополам справляется TCP, может основательно поломать IP-телефонию или видео, например.
Проблема в попакетной балансировке в том, что два пакета одного потока спокойно могут пойти разными путями. При этом один из них маленький и очень быстро долетит до получателя, а другой акселерат-переросток — застрянет в узком буфере. Вот они и разупорядочились.

То же происходит и на фабрике.
Неплохой метод борьбы с этим — попоточная балансировка — вычисляется хэш по кортежу значений (SMAC, DMAC, SIP, DIP, Protocol, SPort, DPort, MPLS-метка итд.) и все пакеты одного потока начинают передаваться одним путём.
Но это работает неидеально. Зачастую один очень жирный поток может нагрузить один линк в то время, как другие будут простаивать. И с этим можно смириться на сети оператора, но нельзя в пределах этого синего ящика.
Элегантное решение выглядит следующим образом:
Пакеты нарезаются на ячейки одинакового маленького размера.
Ячейки балансируются поячеечно. То есть одна ячейка сюда, другая — туда, третья — в следующий линк итд.
Каждая ячейка пронумерована, поэтому, когда она приходит на нужный FE — легко собирается обратно в целостный пакет.
Поскольку расстояние от входа до выхода примерно одинаковое, размеры ячеек одинаковые, время их доставки тоже примерно одинаковое.
Идея Чарльза Клоза, которая сначала была реализована на телефонных станциях, затем была заимствована в Ethernet-коммутаторы и далее маршрутизаторы, ныне нашла своё место в сетях ЦОДов, заменив собой классическую трёхуровневую модель.



6. Путешествие длиною в жизнь
Пакет существует ровно в пределах устройства. В кабеле — это электромагнитный импульс.
Он рождается на входном интерфейсе, где PIC его восстанавливает из потока битов, и умирает на выходном, разбиваясь обратно в них.
Поэтому нахождение пакета в пределах одного устройства мы можем рассматривать как целую жизнь.
Рассмотрим два случая — транзитные пакеты и протокольные пакеты.
Транзитные пакеты
Пусть мы имеем дело со стандартным Ethernet/IP-пакетом.
Узел — IP-маршрутизатор.
Пакет следует транзитом из L3-порта А в L3-порт Б.

- Оптический сигнал приходит в порт. Здесь он преобразуется в электрические импульсы.
- Импульсы попадают на PIC, где АЦП восстанавливает из них поток битов. Поток битов модуль Ethernet разбивает на отдельные Ethernet-кадры. В этом ему помогает преамбула, которая тут же за ненадобностью отбрасывается. По ходу дела Ethernet вычисляет контрольную сумму кадра. А потом сравнивает с хвостовым заголовком FCS. Если совпало, пакет без FCS передаётся дальше. Если нет — тут же отбрасывается, а счётчик ошибок на интерфейсе увеличивается на 1. Здесь же на PIC вычисляется статистика трафика: количество, объём, скорость с разбивкой на Unicast, Broadcast, Multicast.
- Далее этот Ethernet кадр ещё со всем заголовками отправляется на FE.
- FE извлекает DMAC из заголовка, обращается в CAM и ищет, есть ли там такая запись. Она находится и CAM сообщает адрес в RAM. Поскольку Ethernet терминируется на маршрутизаторе, данный DMAC — это MAC-адрес самого узла. Поэтому запись в RAM сообщает, что порт назначения — сам этот маршрутизатор и нужно передать Payload модулю IP (об этом говорит анализ поля EtherType в заголовке). Далее FE отделяет заголовок IP от нагрузки (Payload). Нагрузка будет томиться в буфере, а заголовок разорвут и растащут по полям для анализа. Какие же данные из заголовка понадобятся?
- Адрес назначения (IP в нашем случае, но может быть MAC, MPLS-метка итд.)
- Приоритет (DSCP, IEEE802.1p, EXP итд.)
- Значение TTL.
- Возможно понадобятся и другие поля, такие как адрес источника, информация о вложенных данных (протокол, порт, приложение).
- Далее, пока пакет греется во внутричиповом буфере, происходит обработка изученных данных.
- Уменьшение TTL на 1 и проверка, не равен ли он 0. Если равен — то запрос на CPU для генерации ICMP TTL Expired in Transit.
- Проверка по ACL — можно ли вообще передавать этот трафик.
- Приняните решение о назначении пакета на основе DIP. Ingress FE здесь обращается к TCAM с просьбой найти маршрут, соответствующий данному IP-адресу. Тот находит и передаёт адрес ячейки в RAM. FE от RAM получает Egress FE, выходной интерфейс и NextHop. В большинстве случаев Ingress FE выясняет на этом шаге MAC-адрес Next-Hop’а из таблицы соседей (Adjacenies Tables). Тут же FE узнаёт необходима ли репликация пакетов и в какие порты (BUM-трафик в случае, например сценариев L2VPN), считает хэш для определения в какой из интерфейсов LAG или ECMP послать этот пакет.
Если адрес назначения локальный то или парсится следующий заголовок (как это и было выше с Ethernet), или принимаются какие-то меры аппаратные (BFD, например) или пакет передаётся на CPU (BGP, OSFP итд.)
- Преобразование приоритета из заголовков пакета во внутреннюю CoS-метку, в соответствии с которой пакет будет обрабатываться в пределах данного узла. Может навешиваться приоритет обработки в очередях и приоритет отбрасывания пакета.
- Всё это станет метаданными и будет помещено во временный заголовок, сопровождающий пакет до Egress FE:
- Egress FE
- Выходной интерфейс
- Приоритет
- TTL
- Next Hop (MAC-адрес)
- Данный метазаголовок приклеивается обратно к пакету перед помещением его во входную очередь. К этому моменту уже создано нужное количество копий пакета и они направляются к нужным Egress FE.
- В зависимости от реализации далее входная очередь может запрашивать разрешение у выходной на передачу пакета, ожидать явное подтверждение или вовсе передавать безусловно.
- Непосредственно перед передачей на общую шину, пакет разрезается чипом SerDes на ячейки.
- Далее ячейки попадают на общую шину. Оттуда на плату коммутации, если она есть. Если чипов коммутации не много (2-4), то фабрики могут быть встроены в интерфейсные карты. Если больше, то это или отдельностоящиме платы или составная часть управляющих. Для нас всё это не принципиально — важно знать, что ячейки передаются через эти фабрики.
- С общей шины ячейки приходят на чип SerDes выходной платы, где благодаря их номерам они обратно собираются в пакет.
- Пакет помещается в выходную очередь. Выходная очередь служит защитой FE от чрезмерного потока трафика (Back Pressure). Очередь позволяет отбрасываться пакеты контролируемо и прогнозируемо. Как раз в ней будет иметь значение приоритет CoS, указанный в метазаголовке. Чем ниже приоритет, тем выше вероятность отбрасывания при перегрузках. Таким образом на чип коммутации никогда не придёт больше трафика, чем он способен обработать. Здесь уже вступают в дело механизмы QoS: обработка пакетов в очередях, предотвращение перегрузок, управление перегрузками, шейпинг. Возвращаясь к VOQ (Virtual Output Queue), можно заметить, что данная очередь часто совмещается с очередями на интерфейсы: чтобы в порт 10 Гб/с не пытаться просунуть 13. Однако интерфейсные очереди могут быть выполнены и на отдельных чипах ближе к интерфейсам или даже на PIC.
- После выходной очереди пакет с метазаголовком попадает на Egress FE.
- Здесь теперь разбирается метазаголовок и Egress FE готовит уже окончательный вид настоящих заголовков: Заполняет поля приоритета, записывает правильный TTL, передаёт пакет уровню Ethernet, где формируется полностью новый заголовок с SMAC данного устройства, а DMAC из временного заголовка (однако, если MAC не был разрезолвлен на Ingress FE, это происходит здесь). Здесь же может выполняться полисинг, настроенный на выходном интерфейсе (ограничение скорости, например).
- Далее пакет попадает на чип PIC, где вычисляется контрольная сумма, которая записывается в FCS, добавляются преамбула и IFG, и вычисляется статистика отправленных пакетов.
- Ну и потом, наконец, пакет отправляется в свой последний путь, реинкарнировав снова в импульс.
Egress FE нужен для того, чтобы доставить пакет до нужного чипа коммутации; выходной интерфейс — чтобы сообщить ему, куда пакет передать; приоритет — говорит, как с трафиком поступать в пределах устройства и, возможно, что записать в заголовок пакета (DSCP); TTL — тоже понадобится для того, чтобы потом его вписать в заголовок; а Next Hop MAC позволит затем определить, что писать в поле DMAC Ethernet-заголовка.

Локальные пакеты
Бо́льшая часть локальных пакетов обрабатываются на ЦПУ.
Напомню, что локальные — это те, которые были созданы на данном узле, которые предназначены именно ему (юникастовые), которые предназначены всем/многим (броадкастовые или мультикастовые) или которые намеренно требуют обработки на ЦПУ (TTL Expired, Router Alert).
Входящие
Вплоть до FE с ними происходит всё то же самое, что и с транзитными. Далее чип коммутации, обратившись в CAM, видит, что DMAC — это MAC-адрес локального устройства, заглядывает в EtherType. Если это какой-нибудь BPDU или ISIS PDU, то пакет сразу передаётся нужному протоколу.
Если IP — передаёт его модулю IP, который, заглядывая в TCAM, видит, что и DIP тоже локальный — значит нужно посмотреть в поле Protocol заголовка IPv4 (или Next Header IPv6).
Определяется протокол, принимается решение о том, какому модулю дальше передать пакет — BFD, OSPF, TCP, UDP итд. И так пакет разворачивается до конца, пока не будет найдено приложение назначения.
Когда Ingress FE с этим справился, содержимое пакета передаётся на CPU через специальный канал связи.
На этом шаге достаточно интеллектуальные устройства применяют политику по ограничению скорости протокольных пакетов, передаваемых на ЦПУ, чтобы одними только telnet’ами не заDoSить процессор.

Если данный пакет принёс информацию об изменении топологии (например, новый OSPF, LSA), Control Plane должен обновить Soft Tables (RAM), а затем изменения спускаются в Hard Tables (CAM/TCAM+RAM).
Если пакет требует ответа, то устройство должно его сформировать и отправить назад изначальному источнику (например, TCP Ack на пришедший BGP Update) или передать куда-то дальше (например, OSPF LSA или RSVP Resv).
Исходящие протокольные пакеты формируются на ЦПУ — он заполняет все поля всех заголовков на основе Soft Tables и далее, в зависимости от реализации, спускает его на Ingress или Egress FE.
Из-за того, что пакет сформирован на процессоре, зачастую он не попадает под интерфейсные политики. Архитектурно многие операции, выполняющиеся на FE, требуют того, чтобы FE производил Lookup и формировал заголовки.
Отсюда могут быть любопытные и неочевидные следствия, например, их не получится отловить ACL, вы можете не увидеть их в зазеркалированном трафике, они не будут учитываться при ограничении скорости. Но это
не точно,зависит от вендора и оборудования.Однако политики, работающие с очередями на CPU их, конечно, увидят.
Есть некоторые протоколы Control Plane, которые всё-таки обрабатываются в железе. Ярким примером может служить BFD. Его таймеры выкручиваются вплоть до 1 мс. CPU, как мы помним, штука гибкая, но неповоротливая, и пока BFD-пакет пройдёт по всему тракту и развернётся до заголовка BFD, пока до процессора дойдёт прерывание, пока тот на него переключится, прочитает пакет, сгенерирует новый, вышлет его, пройдут десятки и сотни миллисекунд — глядь, а BFD-то уже развалился.
Поэтому пакеты BFD в большинстве случаев разбираются на чипе, на нём же и готовится ответ. И только сама сессия устанавливается через CPU.
История выше отсылает нас к длинным пингам. Иногда инженер проверяет RTT своей сети путём пинга с одного маршрутизатора на другой. Видит вариацию в десятки и сотни мс и, начиная переживать, открывает запросы вендору. Пугаться тут нечего. Обычно ICMP обрабатывается на CPU. И именно занятостью процессора определяется время ответа. При этом корреляция с реальным RTT сети практически нулевая, потому что транзитный трафик на CPU не обрабатывается.
Некоторые современные сетевые устройства могут обрабатывать ICMP-запросы и формировать ICMP-ответы на чипе (NP, ASIC, FPGA), минуя долгий путь до CPU. И вот в этом случае циферки в ping будут адекватны реальности. Кроме того, есть технологии мониторинга качества сети (OAM), работающие аппаратно, например CFM.
Заключение
Как вы уже, вероятно, поняли из безумного количества if’ов выше, описать аппаратную коммутацию на вендоронезависимом универсальном языке невозможно. Хуже того, даже если брать одного вендора, разные его линейки оборудования и даже разные платы используют совершенно разную архитектуру.
Так, например, у Cisco есть платформы с программной маршрутизацией, а есть с аппаратной.
Или на Huawei интерфейсная очередь может быть реализована на чипе ТМ, а может на PIC.
Или там, где Cisco использует сетевые процессоры, Juniper обходится ASIC’ами.
Для коробочного устройства нужно убрать фабрики коммутации и поиск выходного чипа.
В маршрутизаторах сегмента SOHO, наверняка, будут отсутствовать CAM/TCAM.
Хореография вокруг очередей, которые могут быть сделаны тысячей различных способов, заслуживает отдельных 600 страниц в книге «Соседняя очередь движется быстрее. История потерянного RFC».
Что уж говорить о современном мире виртуализации, где свергают старых правителей и возводят на трон новых.
Почти в каждом параграфе опытный и въедливый читатель найдёт, что следует уточнить, где дать более развёрнутые объяснение. И будет прав… и не прав в то же время. У меня были долгие сомнения, ставить ли в заголовок «маленьких» или «матёрых». И я поставил «маленьких», потому что это только введение в безграничный мир аппаратной коммутации, которое не требует глубоких знаний протоколов или электротехники, а если я начну погружаться в тонкости реализаций различных вендоров, то рискую никогда уже не выбраться из стремительного водоворота деталей.
Я надеюсь, что данная статья послужит отправной точкой в вашем личном путешествии длиною в жизнь.
Благодарности
Александру Клипперу, Андрею Глазкову, Алексею Кротову и команде linkmeup за вычитку материала и комментарии.
Марату Бабаяну за предоставленные фото оборудования.
Артёму Чернобаю за иллюстрацию.
Моим двум работодателям, которые, проявив терпение или же в силу своего незнания, позволили закончить данную статью.
Оставайтесь на связи
Канал в телеграме: t.me/linkmeup_podcast
Канал на youtube: youtube.com/c/linkmeup-podcast
Подкаст доступен в iTunes, Google Подкастах, Яндекс Музыке, Castbox
Сообщество в вк: vk.com/linkmeup
Группа в фб: www.facebook.com/linkmeup.sdsm
Добавить RSS в подкаст-плеер.
Пообщаться в общем чате в тг: https://t.me/linkmeup_chatПоддержите проект:



 313
313
 96361
96361
 6
6
Ещё статьи


6 коментариев
Спасибо большое!
Марат, большое спасибо! Отличная статья!
Ждем qos)
То, что доктор прописал.
Спасибо Линкмиап, спасибо Марат.
Лютый вин!
Уважаю, братки:-)
Отлично, рад, что пригодилось.
Принято!