





Сети для самых маленьких. Микровыпуск №3. IBGP
 92
92

 273511
273511
 34
34



Долго ли коротко ли длилась история linkmeup, но компания росла, развивалась. Счёт маршрутизаторов уже на десятки, свои опто-волоконные линии, развитая сеть по городу. И было принято решение оформлять компанию, как провайдера и предоставлять услуги доступа в Интернет для сторонних в том числе организаций.
Сама по себе задача административная — лицензии там, поиск клиентской базы, реклама, поставить СОРМ.
Разумеется, с технической стороны тоже нужны приготовления — просчитать ресурсы, мощности, порты, подготовить политику QoS. Но всё это (за исключением QoS) — рутина.
Мы же хотим поговорить о другом — IBGP. Возможно, тема покажется вам несколько притянутой за уши, мол, внутренний BGP — прерогатива достаточно крупных провайдеров.
Однако это не так, сейчас iBGP задействуется в ентерпрайзах чуть ли не чаще, чем в провайдерах. С целью исключительно внутренней маршрутизации. Например, ради VPN — очень популярное приложение на базе BGP в корпоративной среде. К примеру, возможность организовать периметры, изолированные на L3, на уже используемой инфраструктуре очень ценна. А префиксов-то может быть каких-то полсотни, а то и десяток. Вовсе никакой не Full View, однако все равно удобно.
Возможно, к нашей сети Linkmeup это не имеет по-прежнему отношения, но обойти стороной такую концепцию будет совершенно непростительно. Поэтому предположим, что сеть достаточно велика, и у нас есть необходимость в BGP в ядре.
Содержание выпуска
- Когда нужен IBGP
- В чём отличия от EBGP
- Route Reflector’ы
- Конфедерации
- Нерассмотренные в основной статье атрибуты BGP
- Материалы выпуска
Традиционное видео
Задачки в этом выпуске не относятся напрямую к IBGP, это, скорее, по BGP в целом. Интересно будет как новичкам поломать голову, так и старожилам размяться
Что такое IBGP?
Начнём с того, что вообще такое Internal BGP. По сути это тот же самый BGP, но внутри AS. Он даже настраивается практически так же.
Основных применения два:
Резервирование. Когда есть несколько линков к провайдерам и не хочется замыкать всё на одном своём граничном маршрутизаторе (т.н. бордере (от старославянского border — граница), ставится несколько маршрутизаторов, а между ними поднимается IBGP для того, чтобы на них всегда была актуальная информация обо всех маршрутах. 
В случае проблем у провайдера ISP2 R2 будет знать о том, что те же самые сети доступны через ISP1. Об этом ему сообщит R1 по IBGP.
Подключение клиентов по BGP. Если стоит задача подключить клиента по BGP, при этом у вас больше, чем один маршрутизатор, без IBGP не обойтись. 
Чтобы R4 передал Клиенту1 Full View, он должен получить его по IBGP от R1 или R2.
Повторимся, EBGP используется между Автомномными Системами, IBGP — внутри.
Различия IBGP и EBGP
- Главная тонкость, которая появляется при переходе внутрь Автономной Системы и откуда растут ноги почти всех отличий — петли. В EBGP мы с ними справлялись с помощью AS-Path. Если в списке уже был номер собственной AS, то такой маршрут отбрасывался.
Но, как вы помните, при передаче маршрута внутри Автономной Системы AS-Path не меняется. Вместо этого в IBGP прибегают к хитрости: используется полносвязная топология — все соседи имеют сессии со всеми — Full Mesh.
При этом маршрут, полученный от IBGP-соседа не анонсируется другим IBGP-соседям.
Это позволяет на всех маршрутизаторах иметь все маршруты и при этом не допустить петель.
Поясним на примерах.
Как это могло бы быть в такой топологии, например, если не использовать технологию избежания петель:

R1 получил анонс от EBGP-соседа, передал его R2, тот передал R3, R3 передал R4. Вроде, все молодцы, все знают, где находится сеть Интернет. Но R4 передаёт этот анонс обратно R1.

R1 получил маршрут от R4, и он по выгодности точно такой-же, как оригинальный от ISP — AS-Path-то не менялся. Поэтому в качестве приоритетного может выбраться даже новый маршрут от R4, что, естественно, неразумно: мало того, что маршруты будут изучены неверно, так и трафик в итоге может заloopиться и не попадёт к точке назначения.

В случае же полносвязной топологии и правила Split Horizon, такая ситуация исключается. R1, получив анонс от ISP1, передаёт его сразу всем своим соседям: R2, R3, R4. А те в свою очередь эти анонсы сохраняют, но передают только EBGP-партнёрам, но не IBGP, именно потому, что получены от IBGP-партнёра. То есть все BGP-маршрутизаторы имеют актуальную информацию и исключены петли.

Причём, не имеет значение, подключены соседи напрямую или через промежуточные маршрутизаторы. Так, например, на вышеприведённой схеме R1 не имеет связи с R3 напрямую — они общаются через R2, однако это не мешает им установить TCP-сессию и поверх неё BGP.
Понятие Split Horizon тут применяется в более широком смысле. Если в RIP это означало «не отсылать анонсы обратно в тот интерфейс, откуда они пришли», в IBGP это означает «не отсылать анонсы от IBGP-партнёров другим IBGP-партнёрам.»
- 2) Вторая тонкость — адрес Next Hop. В случае External BGP маршрутизатор при отправке анонса своему EBGP-соседу сначала меняет адрес Next-Hop на свой, а потом уже отсылает. Вполне логичное действие.

Вот как анонс сети 103.0.0.0/22 выглядит при передаче от R5 к R1:

Если же маршрутизатор передаёт анонс IBGP-соседу, то адрес Next-Hop не меняется. Хм. Непонятно. Почему? Это расходится с привычным пониманием DV-протокола маршрутизации.
Вот тот же анонс при передаче от R1 r R2:

Дело в том, что здесь понятие Next-Hop отличается от того, которое используется в IGP. В IBGP он сообщает о точке выхода из локальной AS.

И тут возникает ещё один момент — важно, чтобы у получателя такого анонса был маршрут до Next-Hop — это первое, что проверяется при выборе лучшего маршрута. Если его не будет, то маршрут будет помещён в таблицу BGP, но его не будет в таблице маршрутизации.
Такой процесс называется рекурсивной маршрутизацией.
То есть, чтобы R2 мог отправлять пакеты ISP1 он должен знать, как добраться до адреса 101.0.0.1, который в данной схеме и является Next-Hop’ом для сети 103.0.0.0/22.
В принципе, практически всё оборудование даёт возможность менять адрес Next-Hop на свой при передаче маршрута IBGP-соседу.
На циске это делается командой «neighbor XYZ Next-Hop-self«. Позже вы увидите, как это применяется на деле.
- 3) Третий момент: если в EBGP обычно подразумевается прямое подключение двух соседей друг к другу, то в Internal BGP соседи могут быть подключены через несколько промежуточных устройств.
На самом деле в EBGP также можно настраивать соседей, которые находятся за несколько хопов друг от друга и это на самом деле практикуется, например, в случае настройки Inter-AS Option C. Называется это дело MultiHop BGP и включается командой «neighbor XYZ ebgp-multihop» в режиме конфигурации BGP.
Но для IBGP это работает по умолчанию.
Это позволяет устанавливать IBGP-партнёрство между Loopback-адресами. Делается это для того, чтобы не привязываться к физическим интерфейсам — в случае падения основного линка, BGP-сессия не прервётся, потому что лупбэк будет доступен через резервный.
Это самая распространённая практика.
При этом EBGP однако обычно устанавливается на линковых адресах, потому что как правило имеется только одно подключение и в случае его падения, всё равно Loopback будет не доступен. Да и настраивать ещё какую-то дополнительную маршрутизацию с провайдером не очень-то хочется.
Пример конфигурации такого соседства:

 Задача № 1
Задача № 1Схема:
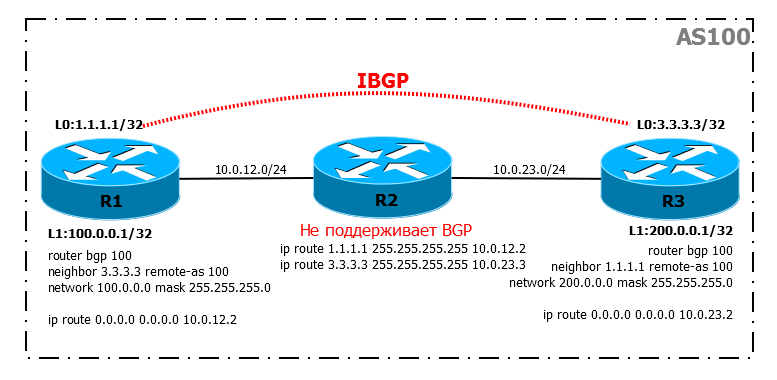
В таком сценарии у нас два BGP-маршрутизатора R1 и R3, но они находятся в разных концах города и подключены через промежуточный маршрутизатор, на котором BGP не настроен.
Условие:
IBGP-сессия прекрасно установится, несмотря даже на то, что на промежуточном маршрутизаторе BGP не включен, и мы видим даже маршруты: 
Но где пинг? 
Подробности задачи тут.
Вам нужно стараться избегать таких ситуаций, когда между IBGP-соседями будут не-BGP маршрутизаторы.
Вообще-то есть механизм, позволяющий если не исправить, то по крайней мере предупредить такую ситуацию, — IGP Synchronization. Он не позволит добавить маршрут в таблицу, если точно такой же маршрут не известен через IGP. Это в какой-то мере гарантирует, что на промежуточных устройствах, независимо от того, активирован на них BGP или нет, будут нужные маршруты. Но я не знаю тех десперадо, которые решились включить IGP Synchronization.
Во-первых, каким образом такие маршруты попадут в IGP? Только редистрибуцией. Теперь представьте себе, как Full View медленно наполняет LSDB OSPF, проникая в отдалённые уголки памяти и заставляя процессор до изнеможения выискивать кратчайшие маршруты. Хотите ли вы этого? А, во-вторых, вытекающее из «во-первых», по умолчанию, IGP-synchronization выключен практически на всех современных маршрутизаторах.

Задача № 2 Между AS64504 и AS64509 появился линк, который связывает их напрямую. Обе сети использовали OSPF и без проблем объединили сеть в одно целое. Но, после проверки, оказалось, что трафик ходит через AS64500, а не напрямую от AS64504 к AS64509, через OSPF.
Изменить конфигурацию BGP:
— R7 должен использовать OSPF, если трафик идет в сеть 109.0.0.0/24
— R9 должен использовать OSPF, если трафик идет в сеть 104.0.0.0/24
Подробности задачи тут
Практика BGP
Давайте теперь вернёмся к сети linkmeup и попробуем запустить BGP в ней.
Схема будет следующей (по клику более подробная с интерфейсами и IP-адресами): 
Как видите, мы её значительно видоизменили. Отказались от именования устройств по геолокации и функциям, изменили адресацию в угоду удобства запоминания и понимания.
Маршрутизаторы будем называть RX, линковая подсеть между маршрутизаторами RX и RY назначается следующим образом: 10.0.XY.0/24. Адреса соответственно 10.0.XY.X у RX и 10.0.XY.Y у RY.
Сверху всё осталось также, как было в основной статье по BGP.
А снизу добавился наш первый коммерческий клиент, который подключился по BGP.
Задача № 3
Наш новый клиент AS 64504 подключен к нашей сети. И в дальнейшем планирует подключение к другому провайдеру и у него уже есть свой PI-блок адресов. Но на данном этапе, есть подключение только к нашей AS и поэтому клиент может использовать приватный номер AS.
Задание: При анонсе сети клиента вышестоящим провайдерам, удалить номер приватной AS64504.
Конфигурация и схема: базовые.
Подробности задачи тут.
EBGP
Я думаю, не стоит останавливаться на настройке и работе EBGP — мы сделали это в прошлой статье.
Просто для примера приведём конфигурацию сессии с новым клиентом:
R4
interface FastEthernet1/0
ip address 100.0.0.5 255.255.255.252
router bgp 64500
network 100.0.0.0 mask 255.255.254.0
neighbor 100.0.0.6 remote-as 64504
R7
interface Loopback1
ip address 130.0.0.1 255.255.255.255
!
interface FastEthernet0/0
ip address 100.0.0.6 255.255.255.252
!
router bgp 64504
network 130.0.0.0 mask 255.255.255.0
neighbor 100.0.0.5 remote-as 64500
Тут всё просто и понятно, после настройки всех внешних соседей мы будем иметь такую ситуацию: 



Каждый BGP маршрутизатор знает только о тех сетях, которые получены им непосредственно от EBGP-соседа.
IBGP
Теперь обратимся к настройке маршрутизаторов нашей AS с точки зрения IBGP.
Во-первых, как мы говорили ранее, IBGP обычно устанавливается между Loopback-интерфейсами для повышения доступности, поэтому в первую очередь создадим их:
На всех маршрутизаторах на интерфейсе Loopback0 настраиваем IP-адрес X.X.X.X, где Х — номер маршрутизатора (это исключительно для примера и не вздумайте такое делать на реальной сети):
R1
interface Loopback0
ip address 1.1.1.1 255.255.255.255
R2
interface Loopback0
ip address 2.2.2.2 255.255.255.255
R3
interface Loopback0
ip address 3.3.3.3 255.255.255.255
R4
interface Loopback0
ip address 4.4.4.4 255.255.255.255
Они станут Router ID и для OSPF и для BGP.
Кстати, об OSPF. Как правило, IBGP «натягивается» поверх существующего на сети IGP. IGP обеспечивает связность всех маршрутизаторов между собой по IP, быструю реакцию на изменения в топологии и перенос маршрутной информации о внутренних сетях.
Настройка внутренней маршрутизации. OSPF
Собственно к этому и перейдём.
Наша задача, чтобы все знали обо всех линковых подсетях, адресах Loopback-интерфейсов и, естественно, о наших белых адресах.
Конфигурация OSPF:
R1
router ospf 1
network 1.1.1.1 0.0.0.0 area 0
network 10.0.0.0 0.255.255.255 area 0
network 100.0.0.0 0.0.1.255 area 0
R2
router ospf 1
network 2.2.2.2 0.0.0.0 area 0
network 10.0.0.0 0.255.255.255 area 0
network 100.0.0.0 0.0.1.255 area 0
R3
router ospf 1
network 3.3.3.3 0.0.0.0 area 0
network 10.0.0.0 0.255.255.255 area 0
network 100.0.0.0 0.0.1.255 area 0
R4
router ospf 1
network 4.4.4.4 0.0.0.0 area 0
network 10.0.0.0 0.255.255.255 area 0
network 100.0.0.0 0.0.1.255 area 0
После этого появляется связность со всеми Loopback-адресами. 
Настраиваем BGP
На каждом узле нужно настроить всех соседей вручную:
R1
router bgp 64500
network 100.0.0.0 mask 255.255.254.0
neighbor 2.2.2.2 remote-as 64500
neighbor 2.2.2.2 update-source Loopback0
neighbor 3.3.3.3 remote-as 64500
neighbor 3.3.3.3 update-source Loopback0
neighbor 4.4.4.4 remote-as 64500
neighbor 4.4.4.4 update-source Loopback0
Команда вида neighbor 2.2.2.2 remote-as 64500 объявляет соседа и сообщает, что он находится в AS 64500, BGP понимает, что это та же AS, в которой он сам работает и далее считает 2.2.2.2 своим IBGP-партнёром.
Команда вида neighbor 2.2.2.2 update-source Loopback0 сообщает, что соединение будет устанавливаться с адреса интерфейса Loopback. Дело в том, что на другой стороне (на 2.2.2.2) сосед настроен, как 1.1.1.1 и именно с этого адреса ждёт все BGP-сообщения.
Такую настройку применяем на всех узлах нашей AS:
R2
router bgp 64500
network 100.0.0.0 mask 255.255.254.0
neighbor 1.1.1.1 remote-as 64500
neighbor 1.1.1.1 update-source Loopback0
neighbor 3.3.3.3 remote-as 64500
neighbor 3.3.3.3 update-source Loopback0
neighbor 4.4.4.4 remote-as 64500
neighbor 4.4.4.4 update-source Loopback0
R3
router bgp 64500
network 100.0.0.0 mask 255.255.254.0
neighbor 1.1.1.1 remote-as 64500
neighbor 1.1.1.1 update-source Loopback0
neighbor 2.2.2.2 remote-as 64500
neighbor 2.2.2.2 update-source Loopback0
neighbor 4.4.4.4 remote-as 64500
neighbor 4.4.4.4 update-source Loopback0
R4
router bgp 64500
network 100.0.0.0 mask 255.255.254.0
neighbor 1.1.1.1 remote-as 64500
neighbor 1.1.1.1 update-source Loopback0
neighbor 2.2.2.2 remote-as 64500
neighbor 2.2.2.2 update-source Loopback0
neighbor 3.3.3.3 remote-as 64500
neighbor 3.3.3.3 update-source Loopback0
Сейчас мы можем проверить, что отношения соседства установились благополучно 
Все маршруты есть в нашей таблице BGP.
Сеть 130.0.0.0/24 видно на R1: 
Сеть 103.0.0.0/22 видно на R4: 
Пора проверить сквозной пинг c R7 (нашего клиента) в Интернет (103.0.0.1)? 
Приехали.
Не будем долго мучить читателя и сразу посмотрим в таблицу маршрутизации, R4. 
А на R7 при этом: 
А? Где мои маршруты? Где все мои маршруты? R4 ничего не знает про сети Балаган-Телекома, Филькина Сертификата, Интернета, соответственно нет их и на R7.
Помните, мы выше говорили про Next-Hop? Мол, он не меняется при передаче по IBGP?
Обратите внимание на Next-Hop полученных R4 маршрутов: 
Несмотря на то, что они пришли на R4 от R1 и R2, адреса Next-Hop на них стоят R5 и R6 — то есть не менялись.
Это значит, что трафик в сеть 103.0.0.0/22 R4 должен отправить на адрес 101.0.0.1, ну, либо на 102.0.0.1. Где они в таблице маршрутизации? Нету их в таблице маршрутизации. Ну, и это естественно — откуда им там взяться.
Для решения этой проблемы у нас есть 3 пути:
1) Настроить статические маршруты до этих адресов — то ещё удовольствие, даже если это шлюз последней надежды.
2) Добавить эти интерфейсы (в сторону провайдеров) в домен IGP-маршрутизации. Тоже вариант, но, как известно, внешние сети не рекомендуется добавлять в IGP.
3) Менять адрес Next-Hop при передаче IBGP-соседям. Красиво и масштабируемо. А ситуации, которая нам помешает это реализовать, просто не может быть.
В итоге добавляем в BGP ещё такую команду: neghbor 2.2.2.2 Next-Hop-self. Для каждого соседа, на каждом узле.
После этого мы видим следующую ситуацию, 
А уж, как добраться до адреса 1.1.1.1 — мы знаем благодаря OSPF: 
Как видите в таблице R7 уже появилась все интересные нам сети. 
Теперь пинг успешной проходит: 

Очень простой вопрос: откуда такие гигантские задержки в трассировке? А ещё часто и такая ситуация бывает:

Задача № 4 Необходимо настроить такие правила работы с соседними AS:
— от всех соседних AS принимаются префиксы только если в них количество автономных систем в пути не более 10 (в реальной жизни порядок этого значения может быть около 100). — все префиксы, которые принимаются от клиентов, должны быть с маской не более 24 бит.
Конфигурация и схема: базовые.
Подробности задачи тут.
Что мы можем улучшить?
Разумеется, процесс настройки BGP. Всё-таки это трудозатраты — сделать весьма похожие настройки на каждом узле. Для упрощения вводится понятие peer-group, которая исходя из названия позволяет объединять соседей в группы и одной командой задавать нужные параметры сразу всем.
Дабы не быть голословными, внедрим это на нашей сети:
R1
router bgp 64500
network 100.0.0.0 mask 255.255.254.0
neighbor AS64500 peer-group
neighbor AS64500 remote-as 64500
neighbor AS64500 update-source Loopback0
neighbor AS64500 Next-Hop-self
neighbor 2.2.2.2 peer-group AS64500
neighbor 3.3.3.3 peer-group AS64500
neighbor 4.4.4.4 peer-group AS64500
Команда neighbor AS64500 peer-group создаёт группу соседей AS64500.
Команда neighbor AS64500 remote-as 64500 сообщает, что все соседи находятся в AS 64500.
Команда neighbor AS64500 update-source Loopback0 указывает, что со всеми соседями соединение будет устанавливаться с адреса Loopback-интрефейса.
Команда neighbor AS64500 Next-Hop-self заставляет маршрутизатор менять адрес Next-Hop на свой при передаче анонсов всем соседям.
Дальше, собственно, мы добавляем соседей в эту группу.
Причём мы можем запросто копировать команды конфигурации группы соседей на другие маршрутизаторы, меняя только адреса соседей.
Пара замечаний по Peer-group:
1) Для всех участников группы политики должны быть идентичны.
2) На самом деле cisco уже давно использует динамические Update-группы. Это позволяет сэкономить ресурсы процессора, так как обработка проводится не по разу на каждого члена группы, а один раз на всю группу. Фактические Peer-группы только облегчают конфигурацию, а оптимизация отдана на откуп Update-групп.
Наверняка, у молодых зелёных инженеров возник вопрос: почему нельзя информацию про публичные адреса передавать по IBGP? Он же, вроде бы, для этого и предназначен? И даже более общий вопрос, почему нельзя обойтись вообще одним BGP, без OSPF или IS-IS, например? (Нет, серьёзно, на форумах иногда вскипают холивары на тему BGP vs OSPF). Ну, по сути ведь тоже протокол маршрутизации — какая разница, передавать информацию между AS или между маршрутизаторами — есть же Internal BGP.
На это я хочу сказать, что достаточно вам будет поработать немного с BGP на реальной сети, чтобы понять всю безумность такой затеи.
Самое главное препятствие — Full Mesh. Придётся устанавливать соседство со всеми всеми маршрутизаторами вручную. OMG, мне дороги моя жизнь и здоровье. (Да, даже не смотря на наличие Route Reflector’ов и скриптов — это лишние операции)
Другая проблема — медленная реакция и Дистанционно-Векторный подход к распространению маршрутной информации.
Да и тут можно резонно возразить, что, дескать, существует BFD. Однако он уменьшит время обнаружение проблемы, но сходимость/восстановление связности всё равно будет медленным.
Третий тонкий момент — отсутствие возможности автоматического изучения соседей. Что ведёт к ручной их конфигурации.
Из всего вышеуказанного вытекают проблемы масштабируемости и обслуживания.
Просто попробуйте сами использовать BGP вместо IGP на сети из 10 маршрутизаторов, и всё станет ясно.
То же самое касается и распространения белых адресов — IBGP с этим справится, но на каждом маршрутизаторе придётся вручную прописывать все подсети.
Ну например, наша сеть 100.0.0.0/23. Допустим, к маршрутизатору R3 подключены 3 клиента по линковым адресам: 100.0.0.8/30, 100.0.0.12/30 и 100.0.0.16/0.
Так вот эти 3 подсети вам нужно будет ввести в BGP тремя командами network, в то время как в IGP достаточно активировать протокол на интерфейсе.
Можно, конечно, прибегнуть к хитрой редистрибуции маршрутов из IGP, но это попахивает уже костылями и ещё менее прозрачной конфигурацией.
К чему всё это мы ведём? eBGP — протокол маршрутизации, без дураков. В то же время iBGP — не совсем. Он больше похож на приложение верхнего уровня, организующее распространение маршрутной информации по всей сети. В неизменном виде, а не сообщая при каждой итерации соседу «вон туда через меня». У IGP такое поведение тоже иногда встречается, но там это исключение, а тут — норма. Я хочу подчеркнуть ещё раз, IGP и IBGP работают в паре, в связке, каждый из них выполняет свою работу.
IGP обеспечивает внутреннюю IP-связность, быструю (читай мгновенную) реакцию на изменения в сети, оповещение всех узлов об этом как можно быстрее. Он же знает о публичных адресах нашей AS.
IBGP занимается обработкой Интернетных маршрутов в нашей AS и их транзитом от Uplink’a к клиентам и обратно. Обычно он ничего не знает о структуре внутренней сети.
Если вам пришёл в голову вопрос «что лучше BGP или IS-IS?» — это хорошо, значит у вас пытливый ум, но вы должны отчётливо понимать, что верный ответ тут только один — это принципиально разные вещи, их нельзя сравнивать и выбирать мисс “технология маршрутизации 2013”. IBGP работает поверх IGP.
Задача № 5 Вышестоящая AS 604503 агрегирует несколько сетей, в том числе и нашу, в один диапазон 100.0.0.0/6. Но этот суммарный префикс вернулся в нашу автономную систему, хотя и не должен был. Настроить R8 так, чтобы агрегированный префикс не попадал в таблицу BGP маршрутизаторов, которые анонсируют подсети этого префикса. Не использовать фильтрацию для этого.
Конфигурация и схема: базовые.
Подробности задачи тут.
Проблема Эн квадрат
На этом месте тему IBGP можно было бы закрыть, если бы не одно «НО» — Full Mesh. Мы говорили о проблемах полносвязной топологии, когда обсуждали OSPF. Там выходом являлись DR — Designated Router, позволяющие сократить количество связей между маршрутизаторам с n*(n-1)/2 до n-1. Но, если в случае OSPF такая топология была, скорее, исключением, потому что больше 2-3 маршрутизаторов в одном L2-сегменте бывает довольно редко, то для IBGP — это самая обычная практика. У «больших» счёт BGP-маршрутизаторов внутри AS идёт на десятки. А уже для 10 устройств на каждом узле нужно будет прописать 9 соседей, то есть всего 45 связей и 90 команд neighbor как минимум. Не хило так. Итак, мы подошли к таким понятиям, как Route Reflector и Confederation. Уж не знаю почему, но эта тема меня всегда пугала какой-то надуманной сложностью.
Route Reflectror
В чём суть понятия Route Reflector? Это специальный IBGP-маршрутизатор, который, исходя из дословного его перевода, выполняет функцию отражения маршрутов — ему присылает маршрут один сосед, а он рассылает его всем другим. То есть фактически на IBGP-маршрутизаторах вам нужно настроить сессию только с одним соседом — с Route Reflector’ом, а не с девятью. Всё довольно просто и тут прямая аналогия с тем самым DR OSPF.
Чуть больше о правилах работы RR.
Во-первых введём понятия клиент RR и не-клиент RR.
Для данного маршрутизатора клиент — iBGP сосед, который специально объявлен, как RR client, и для которого действуют особые правила. Не-клиент — iBGP сосед, который не объявлен, как RR client RR серверов может быть (и должно быть в плане отказоустойчивости) несколько. И понятия клиент/не-клиент строго локальны для каждого RR-сервера.
RR-сервер (или несколько) в совокупности с со своими клиентами формируют кластер. 
Правила работы RR
- Если RR получил маршрут от клиента, он отправляет его всем своим клиентам, не-клиентам-соседям и внешним (EBGP) соседям.

- Если RR получил маршрут от не-клиента, он отправляет его всем клиентам и EBGP-соседям. Не-клиентам маршруты НЕ отправляются (потому что они эти маршруты уже получили напрямую от исходного маршрутизатора).

- Если RR получил маршрут от EBGP-соседа, он отправляет его всем своим клиентам, не-клиентам-соседям и внешним соседям.

- Если клиент получил маршрут от RR, он его может отправить только EBGP-соседу.
Как мы сказали выше, в сети может быть несколько Route-reflector’ов. Это нормально, это не вызовет образование петли, потому что существует атрибут Originator ID — как только RR получит маршрут, где указан он сам, как отправитель этого маршрута, он его отбросит. Каждый RR в таком случае будет иметь таблицу маршрутов BGP точно такую же, как у других. Это вынужденная избыточность, позволяющая значительно увеличить стабильность, но при этом у вас должна быть достаточная производительность самих устройств, чтобы, например, поддерживать по паре Full View на каждом.
Но несколько RR могут собираться в кластеры и разрушать деревни обеспечивать экономию ресурсов — таблица BGP будет делиться между несколькими RR.
Принадлежность к одному кластеру настраивается на каждом RR и определяется атрибутом Cluster ID.
И вот тут тонкий момент — считается, что Best Practice — это настройка одинакового Cluster-ID на всех RR, но на самом деле это не всегда так. Выбирать нужно, исходя из дизайна вашей сети. Более того, часто рекомендуют даже намеренно разделять Route Reflector’ы — как ни странно, это увеличивает стабильность сети.
Вот так выглядит обычная схема с RR: 
Схема с основным и резервным RR: 
Внутри кластера между всему RR должна быть полная связность.
Кластеров может быть несколько и между ними также следует создавать Full-Mesh сеть: 
Повторимся, что кластер: это Рут-рефлектор (один или несколько) вместе со всеми своими клиентами.
Кроме того, часто практикуют иерархические RR. Например, так: 
RR1 получает маршруты от удалённой AS и раздаёт их своим дочерним RR (Client/RR1), которые в свою очередь раздают их клиентам.
Это имеет смысл только в достаточно крупных сетях.
Относительно Route Reflector’ов важно понимать, что сам маршрутизатор, выполняющий функции RR не обязательно участвует в передаче данных. Более того, часто RR специально выносят за пределы пути передачи трафика, чтобы он выполнял исключительно обязанности по передаче маршрутов, чтобы не увеличивать нагрузку на него.
Практика RR
Для примера предположим, что в нашей сети в качестве RR будет выступать R1.
Вот конфигурация самого простого случая RR — одинокого, без кластера.
R1
router bgp 64500
network 100.0.0.0 mask 255.255.254.0
neighbor AS64500 peer-group
neighbor AS64500 remote-as 64500
neighbor AS64500 update-source Loopback0
neighbor AS64500 route-reflector-client
neighbor AS64500 Next-Hop-self
neighbor 2.2.2.2 peer-group AS64500
neighbor 3.3.3.3 peer-group AS64500
neighbor 4.4.4.4 peer-group AS64500
neighbor 101.0.0.1 remote-as 64501
R2
router bgp 64500
network 100.0.0.0 mask 255.255.254.0
neighbor 1.1.1.1 remote-as 64500
neighbor 1.1.1.1 update-source Loopback0
neighbor 1.1.1.1 Next-Hop-self
neighbor 102.0.0.1 remote-as 64502
R3
router bgp 64500
network 100.0.0.0 mask 255.255.254.0
neighbor 1.1.1.1 remote-as 64500
neighbor 1.1.1.1 update-source Loopback0
neighbor 1.1.1.1 Next-Hop-self
R4
router bgp 64500
network 100.0.0.0 mask 255.255.254.0
neighbor 1.1.1.1 remote-as 64500
neighbor 1.1.1.1 update-source Loopback0
neighbor 1.1.1.1 Next-Hop-self
neighbor 100.0.0.6 remote-as 64504
Обратите внимание на команду «neighbor AS64500 route-reflector-client«, добавившуюся в настройку R1 и то, что конфигурация BGP на всех других устройствах полностью идентична, за исключением внешних соседей (102.0.0.1 для R2 и 100.0.0.6 для R4).
В общем-то внешне ничего не поменяется. R4, например, всё будет видеть точно также, за исключением количества соседей: 
Обратите внимание на то, что Route Reflector не меняет Next-Hop отражённых маршрутов на свой, несмотря на наличие параметра Next-Hop-self.
На самом Route Reflector’е отличие будет выглядеть так: 
Если смотреть по конкретным маршрутам: 
Здесь видно полную подсеть, количество путей до неё, какой из них лучший, в какую таблицу он добавлен, куда передаётся (update-group 2 — как раз наш кластер).
Далее перечисляются все эти пути, содержащие такие важные параметры, как AS-Path, Next-Hop, Origin итд, а также информацию о том, что например, первый маршрут был получен от RR-клиента.
Эту информацию можно успешно использовать для траблшутинга. Вот так, например выглядит её вывод, когда не настроен Next-Hop-self: 
Проблема резервирования
Какая сейчас с рут-рефлектором есть проблема? У всех маршрутизаторов связи установлены только с ним. И если R1 вдруг выйдет из строя, пиши пропало — сеть ляжет.
Для этих целей, давайте настроим кластер и в качестве второго RR выберем R2.
То есть теперь на R3 и R4 нужно поднимать соседства не только с R1, но и с R2.
Теперь sh ip bgp update-group выглядит так: 
Один внешний, один внутренний — не RR-клиент и два внутренних RR-клиента. Аналогично на R2: 
На клиентах у нас теперь два соединения с RR: 
Обратите внимание, в сообщениях Update теперь появились два новых атрибута: Cluster-List и Originator-ID. Исходя из названия, они несут в себе номер RR-кластера и идентификатор отправителя анонса:
R1<->R2

Эти параметры добавляются только маршрутам, передающимся по IBGP.
Они необходимо для того, чтобы избежать образования петель. Если, например, маршрут прошёл несколько кластеров и вернулся в исходный, то в параметре Cluster-List среди всех прочих, маршрутизатор увидит номер своего кластера, и после этого удалит маршрут. 
Попробуйте ответить на вопрос, зачем нужен атрибут Originator-ID? Разве Cluster-List не исчерпывает все варианты?
Если сейчас даже сжечь R1, то связь частично ляжет только на время обнаружения проблемы и перестроения таблиц маршрутизации (в худшем случае это 3 минуты ожидания Keepalive сообщения BGP и ещё какое-то время на изучение новых маршрутов).
Но, если дизайн сети у вас предполагал, что RR — это самостоятельные железки, и через них не ходил трафик (то есть они занимались исключительно распространением маршрутов), то, вполне вероятно, что перерыва трафика не будет вовсе. Во-первых, отправитель только через 3 минуты заметит, что что-то не так с RR — в течение этого времени маршрут у него всё-равно будет, а поскольку он ведёт не через бесславно погибший RR, трафик будет ходить вполне благополучно. По прошествии этих трёх минут отправитель переключится на резервный RR и получит от него новый актуальный маршрут. Таким образом связь не будет прервана.
Суть иерархических рут-рефлекторов лишь в том, что один из них является клиентом другого. Это помогает выстроить более понятную и прозрачную схему работы, которую будет проще траблшутить далее.
На нашей сети это лишено какого бы то ни было смысла, поэтому данный случай рассматривать не будем.
Конфедерации
Другой способ решения проблемы Full-Mesh — это конфедерации или иначе их называют sub-AS, под-АС. По сути — это маленькая виртуальная АС внутри большой настоящей АС.
Каждая конфедерация ведёт себя как взрослая AS — внутри полная связность, снаружи, как Лейбниц на душу положит — IBGP работает тут по принципу EBGP (с некоторыми оговорками), граничные маршрутизаторы конфедераций, ведут себя как EBGP-соседи, должны быть подключены напрямую.
Пример топологии: 
Когда маршруты передаются внутри АС между конфедерациями в их AS-Path добавляется номер конфедерации (сегменты AS_CONFED_SEQ и AS_CONFED_SET) для избежания петель. Как только маршрут покидает AS, удаляются все эти номера, чтобы внешний мир о них не знал.
Встречается он довольно редко из-за своей слабой масштабируемости и непрозрачности, поэтому рассматривать мы его не будем.
Более подробно можно почитать на xgu.ru.
Атрибуты BGP
Последняя тема, которую мы затронем касательно BGP — это его атрибуты. Мы их уже начали рассматривать в основной статье (AS-Path и Next-Hop, например). Теперь же имеющиеся знания систематизируем и дополним.
Они делятся на четыре типа:
- Хорошо известные обязательные (Well-known Mandatory)
- Хорошо известные необязательные (Well-known Discretionary)
- Опциональные передаваемые/транзитивные (Optional Transitive)
- Опциональные непередаваемые/нетранзитивные (Optional Non-transitive)
Хорошо известные обязательные (Well-known Mandatory)
Это атрибуты, которые должны присутствовать в анонсах всегда, и каждый BGP-маршрутизатор должен их знать.
Следующие три атрибута и только они принадлежат к этому типу.
Next-Hop говорит маршрутизатору, получающему анонс, о том, куда отправлять пакет.
При передаче маршрута между различными AS значение Next-Hop меняется на адрес отправляющего маршрутизатора. Внутри AS атрибут Next-Hop по умолчанию не меняется при передаче от одного IBGP-оратора другому. Выше мы уже рассматривали почему.
AS-path несёт в себе список всех Автономных Систем, которые нужно преодолеть для достижения цели. Используется для выбора лучшего пути и для исключения петель маршрутизации. Когда маршрут передаётся из одной AS в другую, в AS-path вставляется номер отправляющей AS. При передаче внутри AS параметр не меняется.
Origin сообщает, как маршрут зародился — командой network (IGP — значение 0) или редистрибуцией (Incomplete — значение 2). Значение 1 (EGP) — уже не встречается ввиду того, что протокол EGP не используется. Назначается единожды маршрутизатором-папой, сгенерировавшим маршрут, и более нигде не меняется. По сути означает степень надёжности источника. IGP — самый крутой. 
Хорошо известные необязательные (Well-known Discretionary)
Эти атрибуты должны знать все BGP-маршрутизаторы, но их присутствие в анонсе не требуется. Хочешь — есть, не хочешь — не есть.
Примеры:
Local Preference помогает выбрать один из нескольких маршрутов в одну сеть. Данный атрибут может передаваться лишь в пределах одной AS. Если анонс с Local Preference приходит от EBGP-партнёра, атрибут просто игнорируется — мы не можем с помощью Local Preference управлять маршрутами чужой AS.
Atomic Aggregate говорит о том, что префикс был получен путём агрегирования более мелких.
Опциональные передаваемые/транзитивные (Optional Transitive)
Атрибуты, которые не обязательно знать всем. Кто знает — использует, кто не знает — передаёт их дальше.
Примеры:
Aggregator. Указывает на Router ID маршрутизатора, где произошло агрегирование.
Community. Про этот атрибут мы подробно поговорим далее, в заключительной части статьи.
Опциональные непередаваемые/нетранзитивные (Optional Non-transitive)
Атрибуты, которые не обязательно знать всем. Но маршрутизатор, который их не поддерживает, их отбрасывает и никуда дальше не передаёт.
Пример:
MED — Multi-exit Descriminator. Этим атрибутом мы можем попытаться управлять приоритетами в чужой AS. Можем попытаться, но вряд ли что-то получится 🙂 Часто этот атрибут фильтруется, он имеет значение только при наличии как минимум двух линков в одну AS, он проверяется после многих очень сильных атрибутов (Local Preference, AS-Path), да и разные вендоры могу по-разному трактовать MED.

Упомянутые прежде Cluster List и Originator-ID. Естественно, они являются опциональными, и естественно, передавать их куда-то за пределы AS нет смысла, поэтому и непередаваемые.
Задача № 6*
Необходимо изменить стандартную процедуру выбора лучшего маршрута на маршрутизаторах в AS64500:
— маршрутизаторы R1 и R2 должны выбирать маршруты eBGP, а не iBGP, независимо от длины AS path,
— маршрутизаторы R3 и R4 внутри автономной системы должны выбирать маршруты на основании метрики OSPF.
Конфигурация и схема: базовые.
Подробности задачи тут.
Community
Вот он — один из самых интересных аспектов BGP, вот где проявляется его гибкость — возможность помимо самих маршрутов, передавать дополнительную информацию.
С помощью атрибута Community можно из своей AS управлять поведением маршрутизаторов другой AS.
Я долгое время по непонятной сейчас для себя причине недооценивал мощь этого инструмента.
Управление своими анонсами в чужой AS с помощью community поддерживается подавляющим большинством вендоров. Но на самом деле говорить тут надо не о вендорах, а, скорее, о операторах/провайдерах — именно от них зависит, от их конфигурации, сможете ли вы управлять или нет.
Начнём с теории, Community, как было сказано выше, — это опциональный передаваемый атрибут (Optional Transitive) размером 4 байта. Он представляет из себя запись вида AA:NN, где AA — двухбайтовый номер AS, NN — номер коммьюнити (например, 64500:666).
Существует 4 так называемых Well-Known community (хорошо известные):
Internet — Нет никаких ограничений — передаётся всем.
No-export — Нельзя экспортировать маршрут в другие AS. При этом за пределы конфедерации передавать их можно.
No-export-subconfed (называется также Local AS) — Как No-export, только добавляется ограничение и по конфедерациям — между ними уже тоже не передаётся.
No-advertise — Не передавать этот маршрут никому — только сосед будет знать о нём.
Задача № 7 Наш новый клиент AS 64504 подключен к нашей сети. И пока что не планирует подключение к другому провайдеру. На данном этапе клиент может использовать номер автономной системы из приватного диапазона. Блок адресов, который использует клиент, будет частью нашего диапазона сетей.
Задание: Так как сеть клиента является частью нашего блока адресов, надо чтобы сеть клиента не анонсировалась соседним провайдерам.
Не использовать фильтрацию префиксов или фильтрацию по AS для решения этой задачи.
Конфигурация и схема: Community.
Отличия только в том, что сеть, которую анонсирует AS64504: 100.0.1.0/28, а не 130.0.0.0/24
Подробности задачи тут.
В сети тысячи примеров настройки таких базовых коммьюнити и крайне мало примеров реального использования.
А меж тем одно из самых интересных применений этого атрибута — блэкхоулинг от старославянского black hole — способ борьбы с DoS-атаками.
Суть в том, что когда началась атака на какой-то из адресов вашей AS, вы этот адрес передаёте вышестоящему провайдеру с комьюнити 666, и он отправляет такой маршрут в NULL — блэкхолит его. То есть до вас уже этот паразитный трафик не доходит. Провайдер может передать такой маршрут дальше, и так, шаг за шагом, трафик от злоумышленника или системы ботов будет отбрасываться уже на самых ранних этапах, не засоряя Интернет.
Достигается такой эффект расширяющейся чёрной дыры именно благодаря коммьюнити. То есть в обычном случае вы анонсируете этот адрес в составе большой сети /22, например, а в случае DoS’а передаёте самый специфичный маршрут /32, который будет, естественно, более приоритетным.
О таких атаках вы, кстати, можете послушать в шестом выпуске нашего подкаста linkmeup.
Другие примеры — управление атрибутом Local Preference в чужой AS, сообщать ему, что анонсу нужно увеличить AS-path (AS-path prepending) или не передавать маршрут каким-либо соседям. Насчёт последнего. Как, например, вы решите следующую задачу?
Имеется сеть, представленная на рисунке ниже. Вы хотите отдавать свои маршруты соседям из AS 100 и 200 и не хотите 300. 
Без использования коммьюнити силами только своей AS сделать это не представляется возможным.
Кстати, как бы это ни было прискорбно, но такие ограничения реально используются в нашей жизни. Распространены ситуации, когда несколько провайдеров устанавливают между собой пиринговые отношения — трафик между их сетями не ходит через вышестоящих провайдеров, не даёт круг через пол-России, но кого-то не пускают — кому-то свои сети не анонсируют.
Интереснейшие статьи об Интернете и BGP и о пиринговых войнах.
Практика Community
Мы же в качестве примера рассмотрим следующую ситуацию.
Основная схема статьи дополняется ещё одним маршрутизатором клиента и двумя линками. 
R7 и R9 разнесены территориально — так называемое георезервирование. Главным является его правый сайт, левый — резервный.
Внутри своей AS он без проблем настроил передачу исходящего трафика в нужном месте — через R3. А вот со входящим посложнее — MED не позволяет использовать религия, да и доверия ему нет.
Поэтому мы разработали схему взаимодействия, используя community. На самом деле она будет общая для всех. Например, ниже мы установим правило — если получили маршрут с коммьюнити 64500:150, увеличить Local Preference для него до 150. А потом такую политику применяем к нужным нам маршрутам.
На нашем оборудовании (на всём) мы определяем ip community-list:
ip community-list 1 permit 64500:150
Задаём правило обработки:
route-map LP150 permit 10
match community 1
set local-preference 150
Это общий блок, который будет одинаков для всех устройств. После этого клиент может сказать, что хочет воспользоваться этой функцией и мы применяем карту на BGP-соседа:
Применяем карту к BGP-соседу на R3:
router bgp 64500
neighbor 100.0.0.10 remote-as 64504
neighbor 100.0.0.10 route-map LP150 in
Итак, если в анонсе от соседа 100.0.0.10 community совпадает со значением в условии, установить Local Preference для этих маршрутов в 150.
Часто такие политики (route-map) применяются по умолчанию на всех внешних соседей. Клиентам остаётся только настроить передачу нужной коммьюнити и даже не нужно просить о чём-то провайдера — всё сработает автоматически.
Это наша политика по использовании коммьюнити. О ней мы сообщаем клиенту, мол, хочешь Установить для своего маршрута Local Preference в 150 в нашей AS, используй community 64500:150 И вот он настраивает на R9:
router bgp 64504
neighbor 100.0.0.9 remote-as 64500
neighbor 100.0.0.9 route-map LP out
neighbor 100.0.0.9 send-community
route-map LP permit 10
set community 64500:150
При необходимости то же самое он может настроить на R7.
После clear ip bgp * soft в отправляемых анонсах мы можем увидеть community: 
В итоге R3 имеет маршрут с более высоким Local Preference: 
Передаёт его рут-рефлектору (R1 и R2), который делает выбор и распространяет всем своим соседям: 
И даже R4, которому рукой дотянуться до R7, будет отправлять трафик на R3: 
Трафик идёт именно тем путём, который мы выбрали. 
Пусть вас не пугает по 3 записи для каждого хопа — это говорит о балансировке трафика между равноценными линками R1<->R2<->R3 и R1<->R4<->R3. Просто один раз он идёт по одному пути, второй по другому. А вот вы лучше попробуйте ответить на вопрос, почему на первом хопе 1-я и 3-я попытки идут через R4, а вот на втором хопе на R3. Почему пакет “перепрыгивает”? Как так получается?
Кстати, не стоит забывать команду ip bgp-community new-format, а иначе вместо этого:

вы увидите это: 
Отправляться будет то же самое, но в выводах show команд будет отображаться в удобном виде.
В нашей AS для настройки политик с клиентскими AS, используются community. Используются такие значения: 64500:150, 64500:100, 64500:50, 64500:1, 64500:2, 64500:3.
Кроме того, маршрутизаторы нашей AS также используют community для работы с соседними AS. Их формат: 64501:xxx, 64502:xxx.
Задание:
— все значения community приходящие от клиентов, которые не определены политикой, должны удаляться,
— значения community, которые проставлены клиентами, должны удаляться, при передаче префиксов соседним вышестоящим AS. При этом не должны удаляться другие значения, которые проставлены маршрутизаторами нашей AS.
Конфигурация и схема: базовые.
Подробности задачи тут.
В приведённом примере видно, что коммьюнити позволяет работать не с отдельными анонсами и для каждого из них отдельно применять какие-то политики, а рассматривать их сразу как группу, что естественно, значительно упрощает обслуживание.
Иными словами, коммьюнити — это группа анонсов с одинаковыми характеристиками.
При работе с community важно понимать, что настройка необходима с двух сторон — чтобы желаемое заработало, у провайдера тоже должна быть выполнена соответствующая конфигурация.
Часто у провайдеров бывает уже выработанная политика использования коммьюнити, и они просто дают вам те номера, которые необходимо использовать. То есть после того, как вы добавите к анонсу номер коммьюнити, провайдеру не придётся ничего делать руками — всё произойдёт автоматически.
Например, у Балаган-Телекома может быть такая политика:
| Значение | Действие |
|---|---|
| 64501:100Х | При анонсировании маршрута соседу A добавить Х препендов, где Х от 1 до 6 |
| 64501:101X | При анонсировании маршрута соседу B добавить Х препендов, где Х от 1 до 6 |
| 64501:102X | При анонсировании маршрута соседу C добавить Х препендов, где Х от 1 до 6 |
| 64501:103X | При анонсировании маршрута в AS64503 добавить Х препендов, где Х от 1 до 6 |
| 64501:20050 | Установить Local Preference для полученных маршрутов в 50 |
| 64501:20150 | Установить Local Preference для полученных маршрутов в 150 |
| 64501:666 | Установить Next-Hop для маршрут в Null — создать Black Hole |
| 64501:3333 | Выполнить скрипт по уничтожению конфигурации BGP на всех маршрутизаторах AS |
Исходя из этой таблички, которая опубликована на сайте Балаган-телекома, мы можем сами принять решение об управлении трафиком.
Как это реально может помочь нам?
У нас Dual-homing подключение к двум различным провайдерам — Балаган Телеком и Филькин Сертификат. У датацентра подключение также к обоим провайдерам. Он принадлежит какому-то контент-генератору, допустим это оператор потового видео.
По умолчанию, в нашу сеть всё ходит через Балаган-Телеком (AS64501). Канал там хоть и широкий, но его утилизация уже достаточно высока. Мы хотим продавать домашним клиентам услугу IPTV и прогнозируем значительный рост входящего трафика. Неплохо было бы его завернуть в Филькин Сертификат и не бояться о том, что основной канал забьётся. При этом, естественно, весь другой трафик переносить не нужно.
В таблице BGP проверяем, где находится сеть 103.0.0.0. Видим, что это AS64503, которая достижима через обоих провайдеров с равным числом AS в AS-Path. 
Вот как видит нас маршрутизатор из AS 64503: 
Маршрут в Балаган-Телеком выбран предпочтительным
Какие мысли?
Анонсировать определённые сети в Филькин Сертификат, а остальные оставить в Балаган Телеком? Негибко, немасштабируемо.
Вешать препенды на маршруты, отдаваемые в Балаган Телеком? Тогда, скорее всего, куча другого трафика перетечёт на Филькин Сертификат.
Попросить инженера Балаган-Телекома вручную удлинить наши маршруты при передаче их в AS64503. Уже ближе к истине, и это даже сработает, но, скорее всего, инженер провайдера пошлёт вас… на сайт с табличкой, где прописана их политика Community.
Собственно, всё, что нужно сделать нам — на маршрутизаторе R1 применить route-map по добавлению коммьюнити 64500:1031 к соседу R5(напоминаем, что 103Х — это для соседа из AS 64503). Дальше всё сделает автоматика.
Вот как R5 видит маршрут сам: 
Всё без изменений. Вот как его видит R8: 
Как видите, галочка стоит напротив более короткого пути через Филькин Сертификат, чего мы и добивались. 
Задача № 9 Одним из наших клиентов стала крупная компания. Платят они нам довольно много, но тут возникла проблема с тем, что когда происходят какие-то проблемы с провайдером AS64501, то качество связи, которую обеспечивает линк с провайдером AS64502, не устраивает клиента. Главное для нашего клиента, хорошее качество связи к филиалам.
Так как клиент солидный, то пришлось установить пиринг с еще одним провайдером AS64513. Но он нам дорого обходится поэтому использовать его мы будем только когда провайдер AS64501 недоступен и только для этого важного клиента.
Задание:
Надо настроить работу сети таким образом, чтобы через провайдера AS64513 сеть клиента 150.0.0.0/24 анонсировалась только в том случае, если через провайдера AS64501 недоступна сеть 103.0.0.0/22 (она используется для проверки работы провайдера). Кроме того, от провайдера AS64513 нам надо принимать только сети филиалов клиента (50.1.1.0/24, 50.1.2.0/24, 50.1.3.0/24) и использовать их только если они недоступны через провайдера AS64501. Остальной трафик клиента будет ходить через AS64502.
Конфигурация: базовая.
Подробности задачи тут.
Вот на этом знакомство с BGP можно считать законченным. Теперь мы вернёмся к нему ни много ни мало при рассмотрении MPLS L3VPN.
Материалы выпуска
BGP Blackhole — эффективное средство борьбы с DDoS
Сравнение функций и мест использования EBGP и IBGP
Конфигурация устройств: базовый IBGP, Route Reflectors, Community.
Благодарности
За траблшутинг статьи спасибо JDIMA
Задачки предоставлены Наташей — автором лучшего викисайта по сетевым протоколам и технологиям — xgu.ru.
Оставайтесь на связи
Пишите нам: info@linkmeup.ru
Канал в телеграме: t.me/linkmeup_podcast
Канал на youtube: youtube.com/c/linkmeup-podcast
Подкаст доступен в iTunes, Google Подкастах, Яндекс Музыке, Castbox
Сообщество в вк: vk.com/linkmeup
Группа в фб: www.facebook.com/linkmeup.sdsm
Добавить RSS в подкаст-плеер.
Пообщаться в общем чате в тг: https://t.me/linkmeup_chatПоддержите проект:



 92
92
 273511
273511
 34
34
Ещё статьи



34 коментария
Добрый день.
Прошу уточнить по Well-Known community, нет ли ошибки? т.к. согласно tools.ietf.org/html/rfc1997:
«NO_EXPORT (0xFFFFFF01)
All routes received carrying a communities attribute
containing this value MUST NOT be advertised outside a BGP
confederation boundary»
а здесь указано, что за пределы конфедерации передавать их можно.
Здравствуйте, спасибо за эту статью, как и за все остальные.
Начал внимательно рассматривать раздел «Практика BGP». Мне кажется, что картинка с планом сети не соответствует тексту.
(как минимум перепутаны картинка по клику и отображаемая в тексте).
Например сеть в подключаемой AS64504 судя по всему должна быть 130.0.0.0/24, а на картинке она 104.0.0.0/24
Думаю, что картинки были перепутаны.
Было бы здорово увидеть правильный вариант картинок. Спасибо
Коллеги, добрый день!
Во-первых, спасибо за ваши труды!
Во-вторых, есть пропущенный момент.
Мы с другом собрали данную схему и столкнулись с проблемой(на формуах ответа не нашли), после того как все соседство установлено и прописаны все next-hop-self нет доступа с R1 до сети 102.0.0.0/21 не пингуется 102.0.0.0.1 а с R2 нет доступа до 101.0.0.1 и сети 101.0.0.0/20 (конфигурили вместе в юнетлабе, последний релиз на сегодняшний день) при этом со всех доступен 103.0.0.1, сначала мы думали что это глюк юнета, но в гнсе тоже самое! При этом как мы поняли проблема из-за рекурсивной петли, видели данное сообщение, но потом на show ip route loops ничего не выдавало. Вот таблица бгп на R1
Network Next Hop Metric LocPrf Weight Path
* i 100.0.0.0/23 3.3.3.3 0 100 0 i
* i 4.4.4.4 0 100 0 i
* i 2.2.2.2 0 100 0 i
*> 0.0.0.0 0 32768 i
*> 101.0.0.0/20 101.0.0.1 0 0 64501 i
*>i 102.0.0.0/21 2.2.2.2 0 100 0 64502 i
* 101.0.0.1 0 64501 64502 i
* i 103.0.0.0/22 2.2.2.2 0 100 0 64502 64503 i
*> 101.0.0.1 0 64501 64503 i
*>i 104.0.0.0/24 4.4.4.4 0 100 0 64504 i
*>i 130.0.0.0/24 4.4.4.4 0 100 0 64504 i
R2
* i 100.0.0.0/23 3.3.3.3 0 100 0 i
* i 4.4.4.4 0 100 0 i
* i 1.1.1.1 0 100 0 i
*> 0.0.0.0 0 32768 i
* 101.0.0.0/20 102.0.0.1 0 64502 64501 i
*>i 1.1.1.1 0 100 0 64501 i
*> 102.0.0.0/21 102.0.0.1 0 0 64502 i
*> 103.0.0.0/22 102.0.0.1 0 64502 64503 i
* i 1.1.1.1 0 100 0 64501 64503 i
*>i 104.0.0.0/24 4.4.4.4 0 100 0 64504 i
*>i 130.0.0.0/24 4.4.4.4 0 100 0 64504 i
И выводы команды sho ip cef на R1
Prefix Next Hop Interface
100.0.0.1/32 receive Loopback1
100.0.0.4/30 10.0.14.4 Ethernet0/0
101.0.0.0/20 101.0.0.1 Ethernet0/2
101.0.0.0/30 attached Ethernet0/2
101.0.0.0/32 receive Ethernet0/2
101.0.0.1/32 attached Ethernet0/2
101.0.0.2/32 receive Ethernet0/2
101.0.0.3/32 receive Ethernet0/2
102.0.0.0/21 10.0.12.2 Ethernet0/1
103.0.0.0/22 101.0.0.1 Ethernet0/2
104.0.0.0/24 10.0.14.4 Ethernet0/0
И R2
100.0.0.1/32 10.0.12.1 Ethernet0/0
100.0.0.4/30 10.0.12.1 Ethernet0/0
10.0.23.3 Ethernet0/1
101.0.0.0/20 10.0.12.1 Ethernet0/0
102.0.0.0/21 102.0.0.1 Ethernet0/2
102.0.0.0/30 attached Ethernet0/2
102.0.0.0/32 receive Ethernet0/2
102.0.0.1/32 attached Ethernet0/2
102.0.0.2/32 receive Ethernet0/2
102.0.0.3/32 receive Ethernet0/2
103.0.0.0/22 102.0.0.1 Ethernet0/2
104.0.0.0/24 10.0.12.1 Ethernet0/0
Если вдруг у вас будет время и возможность, мы могли бы дать вам доступ на наш сервак на котором развернута лаба, и вы смогли бы сами все посмотреть.
Заранее спасибо!
Спасибо большое команде Linkmeup за ваш труд.
Очень просто и понятно разобраны серьёзные темы. Читаю с первого выпуска — повторил что знаю и с чем работаю (выпуски до динамической маршрутизации)
Динамическая маршрутизация без практики казались чем-то пугающим, но теперь благодаря СДСМ все стало ясно и понятно.
Еще раз огромное спасибо.
*P.S.:
по «большому пингу» в статье была пометка для размышления — цитирую: «Очень простой вопрос: откуда такие гигантские задержки в трассировке? А ещё часто и такая ситуация бывает… и потери с R7 до 103.0.0.1»
поясните, пожалуйста, задержка связана с особенностью работы протоколов динамической маршрутизации или это загрузка CPU от GNS?
Почему всё-таки в начале статьи такой большой пинг при проверке связи с iBGP?
И, ребята, задачки ваши, как мне кажется, бесполезны — зачем это на практике нужно? Покажите сразу примеры реального, практического применения, вместо измерения высоты здания прикладыванием барометра к стенке много раз.
А так вы молодцы. Спасибо за ваш нужный труд.
Users can also select what other Find My Friends users they want to interact with on their network. That more than six texts per waking hour. Are they lying about their actual location?, Can someone spy on my cell phone remotely. Obtaining high quality audio recordings, Us cellular cell phone gps tracking. Like a delivery guy or a sales rep for your business? You can log into your account at spyphone. How to Read Text Messages on T-Mobile Phones | eHow. How to Read Text Messages on T-Mobile Phones, Can you read text messages online with tmobile. Text You can send and receive text messages The ability to read text messages online can be
All papers are checked for plagiarism on every anti-plagiarism software used by any of your teachers and proof-read manually before delivery! Term papers assistance for the last 5 years, and our best advertisement is a customer satisfied with our expertise. We honor your trust in our ability (and responsibility) to maintain total quality, irrespective of the order specifications. Ultimately though, success comes down to working well together. Our people are the best in the writing business, College application essay writing help. Buy essay. Buy custom written essay. Buy best quality custom written essay. Buy essay, Essays to buy. We offer top quality custom essays. We are the #1 custom essays writing service on the net since 1998 with more thatAll the more better! Leave us a message stating your thesis statement, your ideas and the reading materials you have been struggling with; and we promise to make your life easier. If you are planning to buy thesis online, get it from us, Do my assignment for me australia.
Кому интересно решение задачи номер №1, могу прокомментировать, между маршрутизаторами работающими по ibgp необходимо настроить туннель например ip-in-ip и в качестве neigborов использовать ip адреса туннельных интерфейсов, тогда весь транзитный трафик проходящий через такую автономную систему будет направляться в туннельный интерфейс.

В данной топологии предполагается что R1 и R7 не являются спикерами BGP
ниже указано только решение полные конфиги могу выслать.
R2(config)#interface tunnel 1
R2(config-if)#tunnel source fastEthernet 1/0
R2(config-if)#tunnel destination 1.0.0.1
R2(config-if)#tunnel mode ipip
R2(config-if)#ip address 10.0.0.1 255.255.255.0
R2(config)#router bgp 100
R2(config-router)#no neighbor 1.0.0.1 remote-as 100
R2(config-router)#neighbor 10.0.0.2 remote-as 100
R3(config)#int tunnel 1
R3(config-if)#tunnel source f1/0
R3(config-if)#tunnel destination 1.0.1.2
R3(config-if)#tunnel mode ipip
R3(config-if)#ip address 10.0.0.2 255.255.255.0
R3(config)#interface tunnel 2
R3(config-if)#tunnel source f3/0
R3(config-if)#tunnel destination 3.0.0.2
R3(config-if)#tunnel mode ipip
R3(config-if)#ip address 10.0.1.1 255.255.255.0
R3(config-if)#exit
R3(config)#router bgp 100
R3(config-router)#no neighbor 1.0.1.2 remote-as 100
R3(config-router)#neighbor 10.0.0.1 remote-as 100
R3(config-router)#neighbor 10.0.0.1 next-hop-self
R3(config-router)#no neighbor 3.0.0.2 remote-as 300
R3(config-router)#neighbor 10.0.1.2 remote-as 300
R8(config)#int tunnel 1
R8(config-if)#tunnel source f0/0
R8(config-if)#tunnel destination 192.168.2.1
R8(config-if)#tunnel mode ipip
R8(config-if)#ip address 10.0.1.2 255.255.255.0
R8(config-if)#exit
R8(config)#router bgp 300
R8(config-router)#no neighbor 192.168.2.1 remote-as 100
R8(config-router)#neighbor 10.0.1.1 remote-as 100
Хотел спросить касательно момента с community 64500:1031, в конце статьи, вроде бы удалось добиться результата, но остались сомнения в правильности моей конфигурации:
ALL
ip community-list 2 permit 64500:1031
route-map PRE1 permit 10
match community 2
set as-path prepend 64501
R5
neighbor 101.0.0.2 route-map PRE1 in
R1
neighbor 101.0.0.1 route-map PRE2 out
neighbor 101.0.0.1 send-community
route-map PRE2 permit 10
set community 64500:1031
Когда я ошибочно добавил «set as-path prepend 64501 64501» на R8 добавилось 3 препенда для маршрута через AS64501…
Полностью согласен.
Считаю цикл статей, да и вообще весь проект — бесценным! Я и 1/10 не узнал того за 5 лет в академии, что я подчеркнул в ваших статьях. Надеюсь когда-нибудь у меня будет достаточно знаний и опыта, чтоб принести пользу проекту.
Вот, если Вам будет полезно, ещё в этом фрагменте опечатка, в команде буквы не хватает.
И на этой схеме (которая в статье) ip адреса местами, вроде, поменять надо (или в самой статье)
То есть R9 .10, а у R3 .9 судя по тексту статьи. В файле с конфигурацией всё на своих местах.
Всё это, конечно, не критично и погоды не делает, но надеюсь в скором времени вы объедините накопленный материал в книгу, в которой чем меньше будет всяких опечаток и мелких недочётов — тем лучше.
Замечательная статья! Именно с Вашего цикла СДСМ начал всерьёз увлекаться сетевыми технологиями. Хочу выразить огромную благодарность, за проделанную Вами работу.
По данной статье — теория изложена отлично и доступно (в общем как и во всех статьях СДСМ, особо хочу отметить информативные анимированные схемы), но вот по практике есть некоторые не стыковки, на мой взгляд (в части «Практика Community»). Я параллельно проделывал практику, и с Community у меня возникли трудности.




Тут, как я понял, на всех устройствах устройствах (включая R3) прописываем community-list с AS 64504.
В конфигурации R3 AS 64500
В статье route-map имеет имя LP
А в конфигурации уже LP150
Я конечно понимаю, что данные в конфигурации и статье часто отличаются, что они в разное время были составлены. Но в данном случае я так и не смог разобраться. Всё сводиться к тому у меня, что при применении карты маршрута к R3 или R9 (neighbor 100.0.0.9 route-map LP150 out или neighbor 100.0.0.10 route-map LP150 in) просто пропадает bgp связанность с R9. Возможно это и не связанно с расхождением данных, но думаю это поможет разобраться с моей проблемой.
Если будет время пояснить данную ситуацию, буду очень признателен.
Это просто шедевр )
Спасибо!
Спасибо) Рад, что такие вещи не проходят незамеченными.
про мегафон это 5 =))) А по теме как обычно все отлично!!!
профессионально 😉
Спасибо за отличную подачу материала, вы как всегда на высоте!
Интересно, спасибо! Задачки занятные!
ух… прочитал. Это того стоит.
Вот приложил дебаг с R2
Jun 16 22:56:58.487: BGP: Applying map to find origin for 100.0.0.0/23
*Jun 16 22:56:59.459: RT: del 101.0.0.0/20 via 101.0.0.1, bgp metric [200/0]
*Jun 16 22:56:59.459: RT: delete subnet route to 101.0.0.0/20
*Jun 16 22:56:59.459: RT: NET-RED 101.0.0.0/20
*Jun 16 22:56:59.459: RT: delete network route to 101.0.0.0
*Jun 16 22:56:59.463: RT: NET-RED 101.0.0.0/8
*Jun 16 22:56:59.463: RT: add 101.0.0.0/20 via 102.0.0.1, bgp metric [20/0]
*Jun 16 22:56:59.463: RT: NET-RED 101.0.0.0/20
*Jun 16 22:57:58.515: BGP: Applying map to find origin for 100.0.0.0/23
*Jun 16 22:57:59.483: RT: del 101.0.0.0/20 via 102.0.0.1, bgp metric [20/0]
*Jun 16 22:57:59.483: RT: delete subnet route to 101.0.0.0/20
*Jun 16 22:57:59.483: RT: NET-RED 101.0.0.0/20
*Jun 16 22:57:59.483: RT: delete network route to 101.0.0.0
*Jun 16 22:57:59.487: RT: NET-RED 101.0.0.0/8
*Jun 16 22:57:59.487: RT: add 101.0.0.0/20 via 101.0.0.1, bgp metric [200/0]
*Jun 16 22:57:59.487: RT: NET-RED 101.0.0.0/20
*Jun 16 22:57:59.491: RT: recursion error routing 101.0.0.1 — probable routing loop
*Jun 16 22:58:58.523: BGP: Applying map to find origin for 100.0.0.0/23
*Jun 16 22:58:59.495: RT: del 101.0.0.0/20 via 101.0.0.1, bgp metric [200/0]
*Jun 16 22:58:59.495: RT: delete subnet route to 101.0.0.0/20
*Jun 16 22:58:59.495: RT: NET-RED 101.0.0.0/20
*Jun 16 22:58:59.495: RT: delete network route to 101.0.0.0
*Jun 16 22:58:59.499: RT: NET-RED 101.0.0.0/8
*Jun 16 22:58:59.499: RT: add 101.0.0.0/20 via 102.0.0.1, bgp metric [20/0]
*Jun 16 22:58:59.499: RT: NET-RED 101.0.0.0/20
*Jun 16 22:59:58.543: BGP: Applying map to find origin for 100.0.0.0/23
*Jun 16 22:59:59.467: RT: del 101.0.0.0/20 via 102.0.0.1, bgp metric [20/0]
*Jun 16 22:59:59.467: RT: delete subnet route to 101.0.0.0/20
*Jun 16 22:59:59.467: RT: NET-RED 101.0.0.0/20
*Jun 16 22:59:59.467: RT: delete network route to 101.0.0.0
*Jun 16 22:59:59.471: RT: NET-RED 101.0.0.0/8
*Jun 16 22:59:59.471: RT: add 101.0.0.0/20 via 101.0.0.1, bgp metric [200/0]
*Jun 16 22:59:59.471: RT: NET-RED 101.0.0.0/20
*Jun 16 22:59:59.471: RT: recursion error routing 101.0.0.1 — probable routing loop
*Jun 16 23:00:58.571: BGP: Applying map to find origin for 100.0.0.0/23
*Jun 16 23:00:59.463: RT: del 101.0.0.0/20 via 101.0.0.1, bgp metric [200/0]
*Jun 16 23:00:59.463: RT: delete subnet route to 101.0.0.0/20
Вот приложил дебаг с R2
Коллеги, добрый день!
Во-первых, спасибо за ваши труды!
Во-вторых, есть пропущенный момент.
Мы с другом собрали данную схему и столкнулись с проблемой, после того как все соседство установлено и прописаны все next-hop-self нет доступа с R1 до сети 102.0.0.0/21 не пингуется 102.0.0.0.1 а с R2 нет доступа до 101.0.0.1 и сети 101.0.0.0/20 (конфигурили вместе в юнетлабе, последний релиз на сегодняшний день) при этом со всех доступен 103.0.0.1, сначала мы думали что это глюк юнета, но в гнсе тоже самое! При этом как мы поняли проблема из-за рекурсивной петли, видели данное сообщение, но потом на show ip route loops ничего не выдавало. Вот таблица бгп на R1
Network Next Hop Metric LocPrf Weight Path
* i 100.0.0.0/23 3.3.3.3 0 100 0 i
* i 4.4.4.4 0 100 0 i
* i 2.2.2.2 0 100 0 i
*> 0.0.0.0 0 32768 i
*> 101.0.0.0/20 101.0.0.1 0 0 64501 i
*>i 102.0.0.0/21 2.2.2.2 0 100 0 64502 i
* 101.0.0.1 0 64501 64502 i
* i 103.0.0.0/22 2.2.2.2 0 100 0 64502 64503 i
*> 101.0.0.1 0 64501 64503 i
*>i 104.0.0.0/24 4.4.4.4 0 100 0 64504 i
*>i 130.0.0.0/24 4.4.4.4 0 100 0 64504 i
R2
* i 100.0.0.0/23 3.3.3.3 0 100 0 i
* i 4.4.4.4 0 100 0 i
* i 1.1.1.1 0 100 0 i
*> 0.0.0.0 0 32768 i
* 101.0.0.0/20 102.0.0.1 0 64502 64501 i
*>i 1.1.1.1 0 100 0 64501 i
*> 102.0.0.0/21 102.0.0.1 0 0 64502 i
*> 103.0.0.0/22 102.0.0.1 0 64502 64503 i
* i 1.1.1.1 0 100 0 64501 64503 i
*>i 104.0.0.0/24 4.4.4.4 0 100 0 64504 i
*>i 130.0.0.0/24 4.4.4.4 0 100 0 64504 i
И выводы команды sho ip cef на R1
Prefix Next Hop Interface
100.0.0.1/32 receive Loopback1
100.0.0.4/30 10.0.14.4 Ethernet0/0
101.0.0.0/20 101.0.0.1 Ethernet0/2
101.0.0.0/30 attached Ethernet0/2
101.0.0.0/32 receive Ethernet0/2
101.0.0.1/32 attached Ethernet0/2
101.0.0.2/32 receive Ethernet0/2
101.0.0.3/32 receive Ethernet0/2
102.0.0.0/21 10.0.12.2 Ethernet0/1
103.0.0.0/22 101.0.0.1 Ethernet0/2
104.0.0.0/24 10.0.14.4 Ethernet0/0
И R2
100.0.0.1/32 10.0.12.1 Ethernet0/0
100.0.0.4/30 10.0.12.1 Ethernet0/0
10.0.23.3 Ethernet0/1
101.0.0.0/20 10.0.12.1 Ethernet0/0
102.0.0.0/21 102.0.0.1 Ethernet0/2
102.0.0.0/30 attached Ethernet0/2
102.0.0.0/32 receive Ethernet0/2
102.0.0.1/32 attached Ethernet0/2
102.0.0.2/32 receive Ethernet0/2
102.0.0.3/32 receive Ethernet0/2
103.0.0.0/22 102.0.0.1 Ethernet0/2
104.0.0.0/24 10.0.12.1 Ethernet0/0
Не понял, где большой пинг. Вероятно, это связано с загрузкой процессора от GNS.
Половина статьи — это применение материала на практике. Задачки, не все из жизни, но новичкам придётся подумать, как это сделать и при этом придётся разобраться самому с тем, что такое BGP (или любой другой протокол).
Спасибо, Денис.
Я тоже очень хочу по окончанию цикла всё привести в полный порядок. И, возможно, скомпилировать это всё в книгу. Тем более даже сейчас, перечитывая, я вижу огромное количество моментов, которые нужно улучшать.
Но дело такое, что даже в Таненбауме есть опечатки 🙂
Спасибо за пояснение и за понимание! Разобрался, всё корректно заработало. Не мог закрыть глаза на неправильно работающую схему. Проблема была в «ip community-list 1 permit 64500:150», где на некоторых маршрутизаторах вместо AS64500 прописал AS64504.
Исправлено.
С именами всё было в порядке. LP и LP150 — это для разных маршрутизаторов.
Здравствуйте, Денис. Спасибо за внимательность. Вы совершенно правы, ошибка закралась в листинги.
Во-первых, действительно, номер community должен совпадать (обычно в случае одной политики для многих пользователей в качестве первой части номера сообщества выбирается номер AS провайдера, то есть в данном случае 64500).
Во-вторых, имя да, различается в файле и в статье. Но это не так критично.
Блокироваться передача маршрутов у вас может потому, что анонсы по каким-то причинам не попали под основное правило, а второго правила в Route-map нет, значит по умолчанию — Deny.
Лестно!
Следующий выпуск про мультикаст. Уже через несколько месяцев… я надеюсь.
Вот и по Juniper у нас нет спецов. Но не хотелось бы как-то углубляться в вендоров. Отличия командной строки — это мелочи по сравнению с протоколами.
Спасибо, польщён 🙂
Кто бы мне рассказал про RIPE DB. Однажды была нужда поправить контактные данные там. Это тот ещё квест.
А сейчас нет возможности там даже поковыряться.
а еще лучше было бы, если ты добавил мини статьи по Juniper.
Ты — ох**нен.
Можно тебя попрость на будущее запилить статю по RIPE DB? Ибо пока идет BGP, было бы не плохо пояснить )
Оставайтесь с нами)
Спасибо 🙂
Спасибо. Приятно слышать. У меня всегда к окончанию работы над статьёй ощущение, что получилось всё очень скомкано.