





Сети для самых маленьких. Часть восьмая. BGP и IP SLA
 68
68

 464233
464233
 61
61



До сих пор мы варились в собственном соку – VLAN’ы, статические маршруты, OSPF. Плавно росли над собой из зелёных студентов в крепких инженеров.
Теперь отставим в сторону эти игрушки, пришло время BGP.
Содержание выпуска
- Автономные системы – AS
- PI и PA адреса
- Протокол BGP
- Установление BGP-сессии и процедура обмена маршрутами
- Настройка BGP и практика
- Full View и Default Route
- Looking Glass и другие инструменты
- Control Plane и Data Plane
- Выбор маршрута
- Управление маршрутами
- Балансировка и распределение нагрузки
- PBR
- IP SLA
- Материалы выпуска
- Полезные ссылки
Сначала освежим в памяти основы протоколов динамической маршрутизации.
Бывает два вида протоколов: IGP (внутренние по отношению к вашей автономной системе) и EGP (внешние).
И те и другие опираются на один из двух алгоритмов: DV (Distance Vector) и LS (Link State).
Внутренние мы уже рассматривали. К ним относятся ISIS/OSPF/RIP/EIGRP. Нужны они для того, чтобы обеспечить распространение маршрутной информации внутри вашей сети.
EGP представляет только один протокол – BGP – Border Gateway Protocol. Он призван обеспечивать передачу маршрутов между различными сетями (автономными системами).
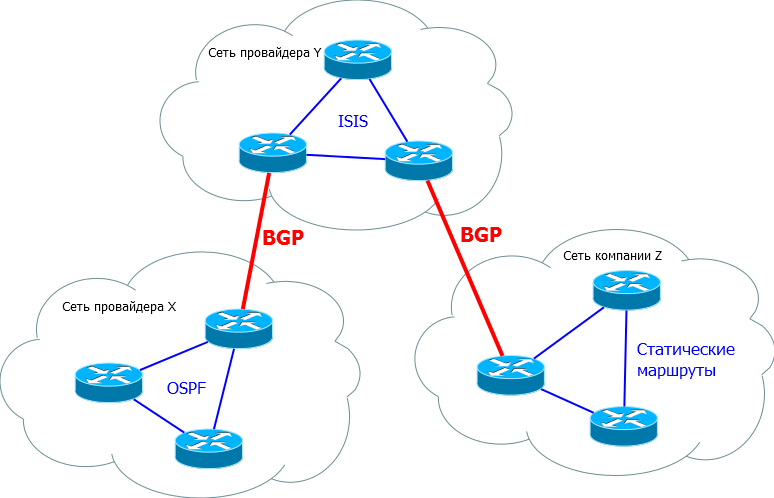
Грубо говоря, стык между Балаган-Телекомом и его аплинковым провайдером будет точно организован через BGP.
То есть схема применения примерно такая:
Автономные системы – AS
BGP неразрывно связан с понятием Автономной Системы (AS – Autonomous System), которое уже не раз встречалось в нашем цикле.
Согласно определению вики, АС — это система IP-сетей и маршрутизаторов, управляемых одним или несколькими операторами, имеющими единую политику маршрутизации с Интернетом.
Чтобы было немного понятнее, можно, например, представить, что город – это автономная система. И как два города связаны между собой магистралями, так и две АС связываются между собой BGP. При этом внутри каждого города есть своя дорожная система – IGP.
Вот как это выглядит с небольшого отдаления:

В BGP AS – это не просто какая-то абстрактная вещь для удобства. Эта штука весьма формализована, есть специальные окошки в собесе, где можно в будние дни с 9 до 6 получить номер автономной системы. Выдачей этих номеров занимаются RIR (Regional Internet Registry) или LIR (Local Internet Registry).
Вообще глобально этим занимается IANA. Но чтобы не разорваться, она делегирует свои задачи RIR – это региональные организации, каждая из которых отвечает за определённую часть планеты (Для Европы и России – это RIPE NCC)

LIR’ом может стать почти любая желающая организация при наличии необходимых документов. Они нужны для того, чтобы RIR’у не пришлось напрягаться с запросами от таких мелких контор, как ЛинкМиАп.
Ну вот, например, Балаган-Телеком мог бы быть LIR’ом. И у него мы и взяли ASN (номер АС) – 64500, например. А у самого у него AS 64501.
До 2007 года были возможны только 16-битные номера AS, то есть всего было доступно 65536, номеров. 0 и 65535 – зарезервированы.
Номера 64512 до 65534 предназначены для приватных AS, которые не маршрутизируются глобально – что-то вроде приватных IP-адресов.
Номера 64496-64511 – для использования в примерах и документации, чем мы и воспользуемся.
Сейчас возможно использование 32битных номеров AS. Этот переход значительно легче, чем IPv4->IPv6.
Опять же нельзя говорить об автономных системах без привязки к блокам IP-адресов. На практике с каждой AS должен быть связан какой-то блок адресов.
PI и PA адреса
В пору своей профессиональной юности, читая договор с нашим LIR я посмеивался над менеджерами, которые не могли правильно написать IP-адрес: то и дело в тексте встречалось слово “PI-адрес”.
Слава богу хватило тогда ума загуглить этот вопрос
На самом деле PI – это Provider Independent.
В обычной ситуации, когда вы подключаетесь к провайдеру, он выдаёт вам диапазон публичных адресов – так называемые PA-адреса (Provider Aggregatable).
Получить их – раз плюнуть, но если вы не являетесь LIR’ом, то при смене провайдера придётся возвращать и PA-адреса. Тем более фактически допускается подключение только к одному провайдеру. И если вы решите сменить провайдера, то старые адреса уйдут вместе с ним, а новый провайдер выдаст новые. Ну и где тут гибкость?
У LIR вы можете приобрести повайдеро-независимый блок адресов (PI) и обязательно ASN. В нашем случае пусть это будет блок 100.0.0.0/23, который мы будем анонсировать по BGP своим соседям. И эти адреса уже чисто наши и никакие провайдеры нам не страшны: не понравился один – ушли к другому с сохранением своих адресов.
Получить PI-адреса всегда было не очень просто. Вам нужно подготовить массу документов, обосновать необходимость такого блока итд.
Сейчас с исчерпанием IPv4 получить большие блоки становится всё сложнее. RIR их уже не выдаёт, а LIR раздают последнее.
Таким образом и номера AS и PI-адреса можно получить в одних их тех же конторах.
После получения всего этого хозяйства вам нужно будет ещё внести изменения в базу данных RIPE. Дело это хлопотное, непростое и разбираться придётся долго.
Вот краткая инструкция по объектам БД RIPE.
Предположим, что в нашем случае компания ЛинкМиАп получила блок адресов 100.0.0.0/23 и AS 64500. Возвращаясь к нашей аналогии, мы дали городу имя и снабдили его диапазоном индексов.
BGP
Так вот для того, чтобы нам из своей AS передать информацию об этих публичных адресах в другую AS (читай в Интернет) и используется BGP. И если вы думаете, что яндекс или майкрософт использует какие-то небесные технологии для подключения своих ЦОДов к Интернету, то вы ошибаетесь – всё тот же BGP.
Теперь главный вопрос, который интересует всегда новичков: а зачем BGP, почему не взять пресловутый OSPF или вообще статику?
Наверное, большие дяди могут очень подробно и обстоятельно объяснить это, мы же постараемся дать поверхностное понимание.
- Если говорить о OSPF/IS-IS, то это Link-State алгоритмы, которые подразумевают (внимание!), что каждый маршрутизатор знает топологию всей сети. Представляем себе миллионы маршрутизаторов в Интернете и отказываемся от идеи использовать Link State для этих целей вообще.
Вообще OSPF при маршрутизации между area’ми является фактически distance vector протоколом. Гипотетически, можно было бы заменить «AS» на «Area» в плане глобальной маршрутизации, но OSPF просто не предназначен для переваривания таких объемов маршрутной информации, да и нельзя выделить в интернете Area 0.
RIP, EIGRP… Кхе-кхе. Ну, тут всё понятно.
- IGP – это нечто интимное и каждому встречному ISP показывать его не стоит. Даже без AS ситуация, когда клиент поднимает IGP с провайдером, крайне редкая (за исключением L3VPN). Дело в том, что IGP не имеют достаточно гибкой системы управления маршрутами – для LS-протоколов это вообще знать всё или ничего (опять же можно фильтровать на границе зоны, но гибкости никакой). В итоге оказывается, что придётся открывать кому-то чужому потаённые части своей приватной сети или настраивать хитрые политики импорта между различными IGP-процессами.
В данный момент в интернете более 450 000 маршрутов. Если бы даже OSPF/ISIS могли хранить всю топологию Интернета, представьте сколько времени заняла бы работа алгоритма SPF. Вот наглядный пример, чем может быть опасно использование IGP там, где напрашивается нечто глобальное. Поэтому нужен свой специальный протокол для взаимодействия между AS.
И к такому протоколу есть ряд требований:
- Во-первых, он должен быть дистанционно-векторным – это однозначно. Маршрутизатор не должен делать расчёт маршрута до каждой сети в Интернете, он лишь должен выбрать один из нескольких предложенных.
- Во-вторых, он должен иметь очень гибкую систему фильтрации маршрутов. Мы должны легко определять, что светить соседям, а что не нужно выносить из избы.
- В-третьих, он должен быть легко масштабируемым, иметь защиту от образования петель и систему управления приоритетами маршрутов.
- В-четвёртых, он должен обладать высокой стабильностью. Поскольку данные о маршрутах будут передаваться через среду, которая не всегда может обладать гарантированным качеством (за стык отвечают по крайней мере две организации), необходимо исключить возможные потери маршрутной информации.
- Ну и логичное, в-пятых, он должен понимать, что такое AS, отличать свою AS от чужих.
Встречайте: BGP.
Вообще описание работы этого поистине грандиозного протокола мы разобьём на две части. И сегодня рассмотрим принципиальные моменты.
BGP делится на IBGP и EBGP.
IBGP необходим для передачи BGP-маршрутов внутри одной автономной системы. Да, BGP часто запускается и внутри AS, но об этом мы плотненько поговорим в другой раз.
EBGP – это обычный BGP между автономными системами. На нём и остановимся.

Установление BGP-сессии и процедура обмена маршрутами
Возьмём типичную ситуацию, когда у нас подключение к провайдерскому шлюзу организовано напрямую.

Устройства, между которыми устанавливается BGP-сессия называются BGP-пирами или BGP-соседями.
BGP не обнаруживает соседей автоматически – каждый сосед настраивается вручную.
Процесс установления отношений соседства происходит следующим образом:
- I) Изначальное состояние BGP-соседства – IDLE. Ничего не происходит.

BGP находится в соcтоянии IDLE, если нет маршрута к BGP-соседу.
- II) Для обеспечения надёжности BGP использует TCP.
Это означает, что теоретически BGP-пиры могут быть подключены не напрямую, а, например, так.
Но в случае подключения к провайдеру, как правило, берётся всё же прямое подключение, таким образом маршрут до соседа всегда есть, как подключенный непосредственно.
BGP-маршрутизатор (их также называют BGP-спикерами/speaker или BGP-ораторами) слушает и посылает пакеты на 179-й TCP порт.
Когда слушает – это состояние CONNECT. В таком состоянии BGP находится очень недолго.
Когда отправил и ожидает ответа от соседа – это состояние ACTIVE.
R1 отправляет TCP SYN на порт 179 соседа, инициируя TCP-сессию.

R2 возвращает TCP ACK, мол, всё получил, согласен и свой TCP SYN.

R1 тоже отчитывается, что получил SYN от R2.

После этого TCP-сессия установлена.
В состоянии ACTIVE BGP может подвиснуть, если
- Нет IP-связности с R2
- BGP не запущен на R2
- Порт 179 закрыт ACL
Вот пример неуспешного установления TCP-сессии. BGP будет в состоянии ACTIVE, иногда переключаясь на IDLE и снова обратно.
TCP SYN отправлен с R1 на R2.

На R2 не запущен BGP, и R2 возвращает ACK, что получен SYN от R1 и RST, означающий, что нужно сбросить подключение.

Периодически R1 будет пытаться снова установить TCP-сессию.
В свою бытность зелёным юнцом, я, впервые настраивая BGP-пиринг с провайдером, потратил полдня на поиск проблемы. Я реально не знал, как настраивается BGP и искал ошибку в конфигурации, думал, что есть какие-то тонкости для моей ситуации, уже начал читать про community. Но наконец в голову пришла светлая мысль – проверить ACL на входе в сеть. Да, TCP-запросы провайдера попадали в deny и сессия не устанавливалась.
Будьте аккуратны. Рядовая практика для провайдера вешать на все свои внешние интерфейсы, торчащие в «мир» ACL.
- III) После того, как TCP-сессия установлена, BGP-ораторы начинают обмен сообщениями OPEN.
OPEN – первый тип сообщений BGP. Они отсылаются только в самом начале BGP-сессии для согласования параметров.

В нём передаются версия протокола, номер AS, Hold Timer и Router ID. Чтобы BGP-сессия поднялась, должны соблюдаться следующие условия:
- Версии протокола должна быть одинаковой. Маловероятно, что это будет иначе
- Номера AS в сообщении OPEN должны совпадать с настройками на удалённой стороне
- Router ID должны различаться
Также внизу вы можете увидеть поддерживает ли маршрутизатор дополнительные возможности протокола.
Получив OPEN от R1, R2 отправляет свой OPEN, а также KEEPALIVE, говорящий о том, что OPEN от R1 получен – это сигнал для R1 переходить к следующему состоянию – Established.

Вот примеры неконсистентности параметров:
- а) некорректная AS (На R2 настроена AS 300, тогда, как на R1 считается, что данный сосед находится в AS 200):
R2 отправляет обычный OPEN
R1 замечает, что AS в сообщении не совпадает с настроенным, и сбрасывает сессию, отправляя сообщение NOTIFICATION. Они отправляются в случае каких-либо проблем, чтобы разорвать сессию.

При этом в консоли R1 появляются следующие сообщения:


- б) одинаковый Router ID
R2 отправляет в OPEN Router ID, который совпадает с ID R1:
R1 возвращает NOTIFICATION, мол, опух?!

При этом в консоли будут следующего плана сообщения:


После таких ошибок BGP переходит сначала в IDLE, а потом в ACTIVE, пытаясь заново установить TCP-сессию и затем снова обменяться сообщениями OPEN, вдруг, что-то изменилось?
Когда сообщение Open отправлено – это состояние OPEN SENT.
Когда оно получено – это состояние OPEN CONFIRM.
Если Hold Timer различается, то выбран будет наименьший. Поскольку Keepalive Timer не передаётся в сообщении OPEN, он будет рассчитан автоматически (Hold Timer/3). То есть Keepalive может различаться на соседях
Вот пример: на R2 настроены таймеры так: Keepalive 30, Hold 170.

R2 отправляет эти параметры в сообщении OPEN. R1 получает его и сравнивает: полученное значение – 170, своё 180. Выбираем меньшее – 170 и вычисляем Keepalive таймер:

Это означает, что R2 свои Keepalive’ы будет рассылать каждые 30 секунд, а R1 – 56. Но главное, что Hold Timer у них одинаковый, и никто из них раньше времени не разорвёт сессию.
Увидеть состояние OPENSENT или OPENCONFIRM сложно – BGP на них не задерживается.
- IV) После всех этих шагов они переходят в стабильное состояние ESTABLISHED.
Это означает, что запущена правильная версия BGP и все настройки консистентны.
Для каждого соседа можно посмотреть Uptime – как долго он находится в состоянии ESTABLISHED.

- V) В первые мгновения после установки BGP-сессии в таблице BGP только информация о локальных маршрутах.

Можно переходить к обмену маршрутной информацией.
Для это используются сообщения UPDATE
Каждое сообщение UPDATE может нести информацию об одном новом маршруте или о удалении группы старых. Причём одновременно.

Разберём их поподробнее.
R1 передаёт маршрутную информацию на R2.
Первый плюсик в сообщении UPDATE – это атрибуты пути. Мы их подробно рассмотрим позже, но вам уже должны быть поняты два из них. AS_PATH означает, что маршрут пришёл из AS с номером 100.
NEXT_HOP – что логично, информация для R2, что указывать в качестве шлюза для данного маршрута. Теоретически здесь может быть не обязательно адрес R1.
Атрибут ORIGIN сообщает о происхождении маршрута:
- IGP – задан вручную командой network или получен по BGP
- EGP – этот код вы никогда не встретите, означает, что маршрут получен из устаревшего протокола, который так и назывался – “EGP”, и был полностью повсеместно заменен BGP
- Incomplete – чаще всего означает, что маршрут получен через редистрибьюцию
Второй плюсик – это собственно информация о маршрутах – NLRI – Network Layer Reachability Information. Собственно, наша сеть 100.0.0.0/23 тут и указана.
Ну и UPDATE от R2 к R1.

Нижеидущие KEEPALIVIE – это своеобразные подтверждения, что информация получена.
Информация о сетях появилась теперь в таблице BGP:

И в таблице маршрутизации:

UPDATE передаются при каждом изменении в сети до тех пор пока длится BGP-сессия. Заметьте, никаких синхронизаций таблиц маршрутизации нет, в отличии от какого-нибудь OSPF. Это было бы технически глупо – полная таблица маршрутов BGP весит несколько десятков мегабайтов на каждом соседе.
- VI) Теперь, когда всё хорошо, каждый BGP-маршрутизатор регулярно будет рассылать сообщения KEEPALIVE. Как и в любом другом протоколе это означает: «Я всё ещё жив». Это происходит с истечением таймера Keepalive – по умолчанию 60 секунд.
Если BGP-сессия устанавливается нормально, но потом рвётся и это повторяется с некой периодичностью – верный знак, что не проходят keepalive. Скорее всего, период цикла – 3 минуты (таймер HOLD по умолчанию). Искать проблему надо на L2. Например, это может быть плохое качество связи, перегрузки на интерфейсе или ошибки CRC.
{kind=link}
Ещё один тип сообщений BGP – ROUTE REFRESH – позволяет запросить у своих соседей все маршруты заново без рестарта BGP процесса.
Подробнее обо всех типах сообщений BGP.
Полная конечный автомат) для BGP выглядит так:


Вопрос на засыпку: Предположим, что Uptime BGP-сессии 24 часа. Какие сообщения гарантировано не передавались между соседями последние 12 часов?
Теперь расширим наш кругозор до вот такой сети:
Картинки без подсетей

И посмотрим, что из себя представляет таблица маршрутов BGP на маршрутизаторе R1:

Как видите, маршрут представляет из себя вовсе не только NextHop или просто список устройств до нужной подсети. Это список AS. Иначе он называется AS-Path.
То есть, чтобы попасть в сеть 123.0.0.0/24 мы должны отправить пакет наружу, преодолеть AS 200 и AS 300.
AS-path формируется следующим образом:
- а) Пока маршрут гуляет внутри AS, список пустой. Все маршрутизаторы понимают, что полученный маршрут из этой же AS
- б) Как только маршрутизатор анонсирует маршрут своему внешнему соседу, он добавляет в список AS-path номер своей AS.

- в) Внутри соседской AS, список не меняется и содержит только номер изначальной AS
- г) Когда из соседской AS маршрут передаётся дальше в начало списка добавляется номер текущей AS.

И так далее. При передаче маршрута внешнему соседу номер AS всегда добавляется в начало списка AS-path. То есть фактически это стек.
AS-path нужен не просто для того, чтобы маршрутизатор R1 знал путь до конечной сети – ведь по сути Next Hop достаточно – каждый маршрутизатор решение по-прежнему принимает на основе таблицы маршрутизации. На самом деле тут преследуются две более важные цели:
- Предотвращение петель маршрутизации. В AS-Path не должно быть повторяющихся номеров
На самом деле ASN может повторяться в AS-Path в двух случаях
- а) Когда вы используете AS-Path Prepend, о котором ниже.
- б) Когда вы хотите соединить два куска одной AS, не имеющих прямой связи друг с другом.
- Выбор наилучшего маршрута. Чем короче AS-Path, тем предпочтительнее маршрут, но об этом позже.
Настройка BGP и практика
В этом выпуске мы смешаем теорию с практикой, потому что так будет проще всего понять. Собственно сейчас обратимся к нашей сети ЛинкМиАп.
Как обычно, отрезаем всё лишнее и добавляем необходимое:

Внизу наш главный маршрутизатор msk-arbat-gw1. Для упрощения настройки и понимания, мы отрешимся от всех старых настроек и освободим интерфейсы.
Выше два наших старых провайдера – Балаган Телеком и Филькин Сертификат.
Разумеется, у каждого провайдера здесь своя AS. Мы добавили ещё одну тупиковую AS – до неё и будем проверять, пусть, это например, ЦОД в Интернете.
Для простоты полагаем, что каждая AS представлена только одним маршрутизатором, никаких ACL, никаких промежуточных устройств.
Мы поднимаем BGP-сессию с обоими провайдерами.
Нам важна следующая информация:
- Номер нашей AS и блок IP-адресов. Их мы уже получили: AS64500 и блок: 100.0.0.0/23.
- Номер AS «Балаган Телеком» и линковая подсеть с ним. AS64501 и линковая сеть: 101.0.0.0/30.
- Номер AS «Филькин Сертификат» и линковая подсеть с ним. AS64502 и линковая сеть: 102.0.0.0/30.
При подключении по BGP в качестве линковых адресов используются обычно публичные с маской подсети /30 и выдаёт их нам вышестоящий провайдер.
Делается это по той простой причине, чтобы ваш трафик везде следовал по публичным адресам и в трассировке посередине не появлялись всякие 10.Х.Х.Х. Не то, чтобы это что-то запрещённое, но обычно-таки придерживаются этого правила.

Начнём с банального.
Настройка интерфейсов:
msk-arbat-gw1
R1(config)#int fa0/0
R1(config-if)#ip address 101.0.0.2 255.255.255.252
R1(config-if)#no shutdown
R1(config)#int fa0/1
R1(config-if)#ip address 102.0.0.2 255.255.255.252
R1(config-if)#no shutdown


Теперь назначим какой-нибудь адрес на интерфейс Loopback, чтобы потом проверить связность:
R1(config)#int loopback 0
R1(config-if)#ip address 100.0.0.1 255.255.255.255
Черёд BGP. Тут заострим внимание на каждой строчке.
R1(config)#router bgp 64500
Сначала мы запускаем BGP процесс и указываем номер AS. Именно тот номер, который выдал LIR. Это вам не OSPF – вольности недопустимы.
Теперь поднимаем пиринг.
R1(config-router)#neighbor 101.0.0.1 remote-as 64501
Командой neighbor мы указываем, с кем устанавливать сессию. Именно на адрес 101.0.0.1 маршрутизатор будет отсылать сначала TCP-SYN, а потом OPEN. Также мы обязаны указать номер удалённой Автономной Системы – 64501.
Конфигурация с обратной стороны симметрична:
R2(config)#router bgp 64501
R2(config-router)#neighbor 101.0.0.2 remote-as 64500
Уже по одному сообщению
*Mar 1 00:11:12.203: %BGP-5-ADJCHANGE: neighbor 101.0.0.2 Upможно судить, что BGP поднялся, но давайте проверим его состояние:

Вот они пробежали по всем состояниям и сейчас их статус Established.
Получал и отправлял наш маршрутизатор по одному OPEN и успел за это время отослать и принять уже 2 KEEPALIVE.
Командой sh ip bgp можно посмотреть какие сети известны BGP:

Пусто. Надо указать, что есть у нас вот эта сеточка 100.0.0.0/23 и передать её провайдерам?
Для этого существует три варианта:
- Определить сети командой network
- Импортировать из другого источника (direct, static, IGP)
- Создать агрегированный маршрут командой aggregate-address
Забегая вперёд, заметим, что network имеет больший приоритет, а с импортированием нужно быть аккуратнее, чтобы не хватануть лишку.
R1(config)#router bgp 64500
R1(config-router)#network 100.0.0.0 mask 255.255.254.0
Смотрим появилась ли наша сеть в таблице:
Странно, но нет, ничего не появилось. На R2 тоже.

А дело тут в том, что в ту сеть, которую вы прописали командой network должен быть точный маршрут, иначе она не будет добавлена в таблицу BGP – это обязательное условие. Конечно, такого маршрута нет. Откуда ему взяться:

Поскольку реально у нас некуда прописывать такой маршрут – кроме одного Loopback-интерфейса, нигде этой сети нет, мы можем поступить следующим образом
R1(config)#ip route 100.0.0.0 255.255.254.0 Null 0
Данный маршрут говорит о том, что все пакеты в эту подсеть будут отброшены. Но, не пугайтесь, нормальная работа не будет нарушена. Если у вас есть более точные маршруты (с маской больше /23, например, /24, /30, /32), то они будут предпочтительнее согласно правилу Longest Prefix Match.
И теперь в таблице BGP есть наш локальный маршрут:

Если настроить BGP и нужные маршруты на всех устройствах нашей схемы, то таблицы BGP и маршрутизации на нашем бордере (border – маршрутизатор на границе сети) будут выглядеть так:


Обратите внимание, что в таблице BGP по 2 маршрута к некоторым сетям, а в таблице маршрутизации только один. Маршрутизатор выбирает лучший из всех и только его переносит в таблицу маршрутизации. Об этом поговорим позже.
Это необходимый минимум, после которого уже будет маленькое счастье.
 Задача №1
Задача №1
Схема:
Условие:
Настройки маршрутизаторов несущественны. Никаких фильтров маршрутов не настроено. Почему на одном из соседей отсутствует альтернативный маршрут в сеть 195.12.0.0/16 через AS400?

Подробности задачи тут
Full View и Default Route
Говоря о BGP и подключении к провайдерам, нельзя не затронуть эту тему. Когда ЛинкМиАп, имея уже AS и PI-адреса, будет делать стык с Балаган-Телекомом, одним из первых вопросов от них будет: “Фул вью или Дефолт?”. Тут главное не растеряться и не сморозить чепуху.
То, что вы видели до сих пор – это так называемый Full View – маршрутизатор изучает абсолютно все маршруты Интернета, пусть даже в нашем случае это пять-шесть штук. В реальности их сейчас больше 400 000. Соответственно от одного провайдера вы получите 400k маршрутов, от второго столько же. Подчас бывает и третий резервный – плюс ещё 400k. Итого больше миллиона. Ну не покупать же теперь маленькому недоинтерпрайзу циску старших серий только для этого?

* вывод таблицы маршрутизации с одного из публичных серверов (дуступен по telnet route-server.ip.att.net)
На самом деле, далеко не каждому, кто имеет AS, нужен Full View. Обычно для таких компаний, как наша вполне достаточно Default Route, по названиям вполне понятно, чем они отличаются. В последнем случае от каждого провайдера приходит только один маршрут по умолчанию, вместо сотен тысяч специфических (хотя вообще-то может и вместе).
Позвольте привести небольшие аргументы в пользу того и другого.
- Full View. Вы обладаетe полным чистейшим знанием о структуре Интернета. До любого адреса в Интернете вы можете просмотреть путь от себя:

Вы знаете, какие к нему ведут AS. Через сайт RIPE можно посмотреть какие провайдеры обеспечивают транзит. Вы следите за всеми изменениями. Если вдруг у кого-то что-то упадёт через первый линк (даже не у вас или у провайдера, а где-то там, дальше), BGP это отследит и перестроит свою таблицу маршрутизации для передачи данных через второго провайдера.
При этом вы очень гибко можете управлять маршрутами, вмешиваясь в стандартную процедуру выбора наилучшего пути.
Например, весь трафик на яндекс вы будете пускать через Балаган Телеком, а на гугл через Филькин Сертификат. Это называется распределением нагрузки.
Достигается это путём настройки, например, приоритетов маршрутов для определённых префиксов.
Full View обязателен, если ваша АС транзитная, то есть вы собираетесь по BGP подключать к себе ещё клиентов.
Платить за все эти плюсы приходится производительностью: высокая утилизация оперативной памяти и весьма долгое изучение маршрутной информации после установления BGP-сессии. Например, после того, как дёрнулся линк с вышестоящим провайдером, полное восстановление может занять несколько минут.
- Default Route Ну, во-первых, это, конечно, сильно экономит ресурсы вашего оборудования.
Во-вторых, проще в обслуживании, можно сказать. Не нужно по всей своей AS гонять сотни тысяч маршрутов.
В-третьих, никакого представления о состоянии интернета и реальной доступности получателей нет – вы просто слепо доверяетесь дефолту, полученному от апстрима. То есть в случае проблемы выше, вы о ней не узнаете и часть сервисов может упасть. Но тут мы надеемся, что у вышестоящих провайдеров надёжность сети на порядки выше и нам не о чем беспокоиться.
Балансировка и распределение входящего трафика при получении маршрута по умолчанию никак не затрагивается – проблемы те же. А вот с исходящим, конечно, всё, немного иначе, былой гибкости тут уже не будет.
В общем, очень грубый совет прозвучит так:
Если вы не собираетесь организовывать через себя транзит (подключать клиентов со своими АС) и нет нужды в тонком распределении исходящего трафика, то вам хватит Default Route.
Но уж точно нет смысла принимать от одного провайдера Full View, а от другого Default – в этом случае один линк будет всегда простаивать на исходящий трафик, потому что маршрутизатор будет выбирать более специфический путь.
При этом от всех провайдеров вы можете брать Default плюс определённые префиксы (например, именно этого провайдера). Таким образом до нужных ресурсов у вас будут специфические маршруты без Full View.
Вот пример настройки передачи Default Route нижестоящему маршрутизатору:
balagan-router(config-router)#neighbor 101.0.0.2 default-originate
И вот как после этого выглядит таблица маршрутов на нашем бордере:

То есть помимо обычных маршрутов (Full View) передаётся ещё маршрут по умолчанию.
Сейчас вы уже должны начинать догадываться, что Default Route – это не противопоставление Full View. Не обязательно здесь стоит «или то или другое» (надо бы ввести понятие хили или ксили, как английское XOR), вы вполне можете использовать Default Route в дополнение к Full View или Default Route и часть каких-то других маршрутов.
Задача №2
Схема: Общая схема сети
Задание:
Настроить фильтрацию со стороны провайдера таким образом, чтобы он передавал нам только маршрут по умолчанию и ничего лишнего.
То есть, чтобы таблица BGP выглядела так:
Подробности задачи тут
Looking Glass и другие инструменты
Одним из очень мощных инструментов работы с BGP – Looking Glass. Это сервера, расположенные в Интернете, которые позволяют взглянуть на сеть извне: проверить доступность, просмотреть через какие AS лежит путь в вашу автономную систему, запустить трассировку до своих внутренних адресов.


Это как если бы вы попросили кого-то: “слушай, а посмотри, как там мои анонсы видятся?”, только просить никого не нужно.
Не стоит недооценивать силу внешних инструментов. Однажды у меня была проблема с очень низкой скоростью отдачи вовне. Она едва переваливала за несколько мегабит. После довольно продолжительного траблшутинга, решил взглянуть в Looking Glass. Какого же было моё удивление, когда я обнаружил, что трафик идёт ко мне, через VPN канал до филиала в другом городе, с которым установлен IBGP. Естественно, ширина канала была небольшой и утилизировалась практически полностью.
Существуют также специальные организации, которые отслеживают анонсы BGP в Интернете и, если вдруг происходит что-то неожиданное, они могут уведомить владельца сети – BGPMon, Renesys, RouteViews. Благодаря им было предотвращено несколько глобальных аварий.
С помощью сервиса BGPlay можно визуализировать информацию о распространении маршрутов.
На nag.ru можно почитать о самых ярких случаях, когда некорректные анонсы BGP вызывали глобальные проблемы в Интернете, таких как ”AS 7007 Incident” и “Google’s May 2005 Outage”.
Очень хорошая статья по разнообразным прекраснейшим инструментам для работы с BGP.
Список серверов Looking Glass.
Control Plane и Data Plane
Перед тем, как окунуться в глубокий омут управления маршрутами, сделаем последнее лирическое отступление. Надо разобраться с понятиями в заголовке главы.
В своё время, читая MPLS Enabled Application, я сломал свой мозг на них. Просто никак не мог сообразить, о чём авторы ведут речь.
Итак, дабы не было конфузов у вас.
Это не уровни модели, не уровни среды или моменты передачи данных – это весьма абстрактное деление.
Управляющий уровень (Control Plane) – работа служебных протоколов, обеспечивающих условия для передачи данных.
Например, когда запускается BGP, он пробегает все свои состояния, обменивается маршрутной информацией итд.
Или в MPLS-сети LDP распределяет метки на префиксы.
Или STP, обмениваясь BPDU, строит L2-топологию.
Всё это примеры процессов Control Plane. То есть это подготовка сети к передаче – организация коммутации, наполнение таблицы маршрутизации.
Передающий уровень (Data Plane) – собственно передача полезных данных клиентов.
Часто случается так, что данные двух уровней ходят в разных направлениях, “навстречу друг другу”. Так в BGP маршруты передаются из AS100 в AS200 для того, чтобы AS200 могла передать данные в AS100.

Более того, на разных уровнях могут быть разные парадигмы работы. Например, в MPLS Data Plane ориентирован на создание соединения, то есть данные там передаются по заранее определённому пути – LSP.
А вот сам этот путь подготавливается по стандартным законам IP – от хоста к хосту.
Важно понять назначение уровней и в чём разница.
Для BGP это принципиальный вопрос. Когда вы анонсируете свои маршруты, фактически вы создаёте путь для входящего трафика. То есть маршруты исходят от вас, а трафик к вам.
Выбор маршрута
Ситуация с маршрутами у нас такая.
Есть BGP-таблица, в которой хранятся абсолютно все маршруты, полученные от соседей.

То есть если есть у нас несколько маршрутов, до сети 100.0.0.0/23, то все они будут в BGP-таблице, независимо от “плохости” оных:

А есть знакомая нам таблица маршрутизации, хранящая только лучшие из лучших. Точно также BGP анонсирует не все приходящие маршруты, а только лучшие. То есть от одного соседа вы никогда не получите два маршрута в одну сеть.
Итак, критерии выбора лучших:
- Максимальное значение Weight (локально для маршрутизатора, только для Cisco)
- Максимальное значение Local Preference (для всей AS)
- Предпочесть локальный маршрут маршрутизатора (next hop = 0.0.0.0)
- Кратчайший путь через автономные системы. (самый короткий AS_PATH)
- Минимальное значение Origin Code (IGP < EGP < incomplete)
- Минимальное значение MED (распространяется между автономными системами)
- Путь eBGP лучше чем путь iBGP
- Выбрать путь через ближайшего IGP-соседа.
Если это условие выполнено, то происходит балансировка нагрузки между несколькими равнозначными линками Следующие условия могут различаться от вендора к вендору. - Выбрать самый старый маршрут для eBGP-пути
- Выбрать путь через соседа с наименьшим BGP router ID
- Выбрать путь через соседа с наименьшим IP-адресом
Как видите, очень много критериев выбора. Причём они довольно сложные и с ходу их все понять непросто. Втягивайтесь потихоньку.
О некоторых упомянутых атрибутах мы поговорим ниже, а конкретно на выборе маршрутов остановимся в отдельной статье.
Задача №3
Схема: Общая схема сети
Условие: Full View на всех маршрутизаторах
Если вы сейчас посмотрите таблицу BGP на маршрутизаторе провайдера Балаган Телеком, то увидите 3 маршрута в сеть 102.0.0.0/21 – сеть Филькина Сертификата. И один из маршрутов ведёт через нашу сети ЛинкМиАп.
![]()
Это говорит о том, что наш бордер анонсирует чужие маршруты дальше, иными словами наша AS является транзитной.
Задание:
Настроить фильтрацию таким образом, чтобы наша AS64500 перестала быть транзитной.
Подробности задачи тут
Управление маршрутами
Прежде чем переходить к большой теме распределения нагрузки с помощью BGP просто необходимо разобраться с тем, каким образом мы вообще можем управлять маршрутами в этом протоколе. Именно возможность такого управления обменом маршрутной информации делает BGP таким гибким и подходящим для взаимодействия нескольких различных провайдеров, в отличии от любого IGP.
И инструментов для этого у нас немало:
- AS-Path ACL
- Prefix-list
- Weight
- Local Preference
- MED
Но только первые два из них позволяют фильтровать анонсируемые или принимаемые маршруты, остальные лишь устанавливают приоритеты.
AS-Path ACL
Весьма мощный, но не самый популярный механизм.
С помощью AS-Path ACL вы можете, например, запретить принимать анонсы маршрутов, принадлежащих AS 200. Ну вот просто не хотите – пусть они через другого провайдера будут известны, а через этого нет.
Самое сложное в таком подходе – запомнить все регулярные выражения и научиться их использовать. Сначала голова от них кругом:
- . — любой символ, включая пробел
- * — ноль или больше совпадений с выражением
- + — одно или больше совпадений с выражением
- ? — ноль или одно совпадение с выражением
- ^ — начало строки
- $ — конец строки
- _ — любой разделитель (включая, начало, конец, пробел)
- \ — не воспринимать следующий символ как специальный
- [ ] — совпадение с одним из символов в диапазоне
- | — логическое «или»
Чтобы было чуть более понятно, приведём несколько примеров:
- _127_ — Маршруты проходящие через AS 127. До и после номера AS идут знаки “_”, означающие, что в AS-path номер 200 может стоять в начале, середине или конце, главное, чтобы он был.
- ^127$ — Маршруты из соседней AS 127. “^” означает начало списка, а “$” – конец. То есть в AS-path всего лишь один номер AS – это означает, что маршрут был зарождён в AS 127 и оттуда сразу был передан нам.
- _127$ — Маршруты отправленные из AS 127. “$” означает конец списка, то есть это самая первая AS, из неё маршрут и зародился, знак “_” говорит о том, что неважно, что находится дальше, хоть ничего, хоть 7 других AS.
- ^127_ — Сети находящиеся за AS 127. Знак “^” означает, что ASN 200 была добавлена последней, то есть маршрут к нам пришёл из AS 200, но это не значит, что родился он в ней же – знак “_” говорит о том, что это может быть конец списка, а может пробел перед следующей AS.
- ^$ — Маршруты локальной AS.
Список AS-path пуст, значит маршрут локальный, сгенерированный внутри нашей AS.
Пример
Вот в нашей сети отфильтруем маршруты, которые зародились в AS 64501. То есть мы будем от соседа 101.0.0.1 получать все интернетовские маршруты, но не будем получать их локальные.
ip as-path access-list 100 deny ^64501$
ip as-path access-list 100 permit .*
router bgp 64500
neighbor 101.0.0.1 filter-list 100 in

Prefix-list
Тут всё просто и логично. Ну почти.
Префикс-листы – это просто привычные нам сеть/маска, и мы указываем разрешить такие маршруты или нет.
Синтаксис команды:
ip prefix-list {list-name} [seq {value}] {deny|permit}
{network/length} [ge {value}] [le {value}]
- list-name – название списка. Ваш КО. Обычно указывается, как name_in или name_out. Это подсказывает нам на входящие или исходящие маршруты будет действовать (но, конечно, на данном этапе никак не определяет).
- seq – порядковый номер правила (как в ACL), чтобы проще было оперировать с ними.
- deny/permit – определяем разрешать такой маршрут или нет
- network/length – привычная для нас запись, вроде, 192.168.14.0/24.
А вот дальше, внимание, сложнее – возможны ещё два параметра: - ge и le. Как и при настройке NAT (или в ЯП Фортран), это означает «greater or equal» и «less or equal».
-
То есть вы можете задать не только один конкретный префикс, но и их диапазон.
Например, такая запись
ip prefix-list NetDay permit 10.0.0.0/8 ge 10 le 16будет означать, что в префикс-лист попадут любые маршруты с длиной от 10 до 16 бит, входящие в диапазон 10/8.
Например: 10.0.0.0/10, 10.32.0.0/11, 10.96.0.0.12, 10.0.0.0/13, 10.0.0.0/14, 10.0.0.0/15, 10.8.0.0/16 итд
Пример
Сейчас мы запретим принимать анонс сети 120.0.0.0/24 через провайдер Филькин Сертификат, а все остальные разрешим. Запись 0.0.0.0/0 le 32 означает любые подсети с любой длиной маски (меньшей или равной 32 (0-32)).
ip prefix-list TEST_PL_IN seq 5 deny 120.0.0.0/24
ip prefix-list TEST_PL_IN seq 10 permit 0.0.0.0/0 le 32
router bgp 64500
neighbor 102.0.0.1 prefix-list TEST_PL_IN in

Сделаем на всякий случай оговорку: последний пример не означает, что соседний провайдер не будет вам их передавать – конечно, будет, ведь он-то ничего не знает о ваших политиках – а вот ваш маршрутизатор, получив такой анонс, не добавит маршрут в свою BGP-таблицу.
Route Map
До сих пор все правила применялись безусловно – на все анонсы от пира или пиру.
С помощью карт маршрутов (у других вендоров они могут называться политиками маршрутизации) мы можем очень гибко применять правила, дифференцируя анонсы.
Синтаксис команды следующий:
route-map {map_name} {permit|deny} {seq}
[match {expression}]
[set {expression}]
- map_name – имя карты
- permit/deny – разрешаем или нет прохождение данных, подпадающих под условия route-map
- seq – номер правила в route-map
- match – условие подпадания трафика под данное правило.
- expression:
Критерий Команда конфигурации Network/mask match ip address prefix-list AS-path match as-path BGP community match community Route originator match ip route-source BGP next-hop address match ip next-hop set – что сделать с отфильтрованными маршрутами expression:
Параметры Команда конфигурации AS path prepend set as-path prepend Weight set weight Local Preference set local-preference BGP community set community MED set metric Origin set origin BGP next-hop set next-hop Пример применения
Укажем, что в подсеть 120.0.0.0/24 предпочтительно ходить через Балаган Телеком, а в 103.0.0.0/22 через Филькин Сертификат. Для этого воспользуемся атрибутом Local Preference. Чем выше значение этого параметра, тем выше приоритет маршрута.
prefix-list, которым выделили подсеть 120.0.0.0/24. Permit означает, что на этот префикс в будущем будут действовать правила route-map. Как и в обычных ACL далее идёт неявное правило deny для всего остального. В данном случае оно означает, что под действие route-map подпадёт только 120.0.0.0/24 и ничего другого.ip prefix-list TEST1_IN seq 5 permit 120.0.0.0/24 ip prefix-list TEST2_IN seq 5 permit 103.0.0.0/22 route-map BGP1_IN permit 10 match ip address prefix-list TEST1_IN set local-preference 50 route-map BGP1_IN permit 20 set local-preference 100 route-map BGP2_IN permit 10 match ip address prefix-list TEST2_IN set local-preference 50 route-map BGP2_IN permit 20 set local-preference 100 router bgp 64500 neighbor 101.0.0.1 route-map BGP2_IN in neighbor 102.0.0.1 route-map BGP1_IN in
В созданной карте маршрутов BGP1_IN мы разрешили прохождение маршрутной информации (permit), подпадающей под созданный prefix-list (match ip address prefix-list TEST1_IN). Для этих анонсов установим local preference в 50 – ниже, чем стандартные 100 (set local-preferеnce 50). То есть они будут менее «интересными».
И в конечном итоге привяжем карту к конкретному BGP-соседу (neighbor 102.0.0.1 route-map BGP1_IN in).
Что же получается в результате?

Конфигурация устройств
Другие примеры рассмотрим в следующем разделе.
Задача №4
Схема: Общая схема сети
Условие: ЛинкМиАп получает Full View от обоих провайдеров.
Тема: Поиск неисправностей.
От провайдеров: полная таблица маршрутов BGP
На маршрутизаторе msk-arbat-gw1 настроено распределение исходящего трафика между провайдерами Балаган Телеком и Филькин Сертификат. Трафик идущий в сети провайдера Филькин Сертификат, должен идти через него, если он доступен. Остальной исходящий трафик, должен передаваться через провайдера Балаган Телеком, когда он доступен.
При проверке исходящего трафика, оказалось, что при отключении Балаган Телеком, исходящий трафик к ЦОД (103.0.0.1) не идет через Филькин Сертификат.
Задание:
Исправить настройки так, чтобы исходящий трафик в сети провайдера ISP2, к его клиенту и в сеть удаленного офиса компании, шел через провайдера ISP2.
Подробности задачи и конфигурация тут
Балансировка и распределение нагрузки
“А какие вы знаете способы балансировки трафика в BGP?”
Это вопрос, который любят задавать на собеседованиях.
Начиная готовиться к этой статьей, я имел разговор с нашей Наташей, из которого стало понятно, что в BGP балансировка и распределение – это две большие разницы.Рассматриваемое дальше разделение условно и существуют альтернативные взгляды.
Балансировка нагрузки
Под балансировкой обычно понимается распределение между несколькими линками трафика, направленного в одну сеть.

Включается она простоrouter bgp 100 maximum-paths 2При этом должны выполняться следующие условия:
- Не менее двух маршрутов в таблице BGP для этой сети.
- Оба маршрута идут через одного провайдера
- Параметры Weight, Local Preference, AS-Path, Origin, MED, метрика IGP совпадают.
- Параметр Next Hop должен быть разным для двух маршрутов.
Последнее условие обходится скрытой командой
router bgp 64500 bgp bestpath as-path multipath-relaxВ этом случае умаляется также условие полного совпадения AS-path, но длина должна быть по-прежнему одинаковой.
Как мы можем проверить это на нашей сети? Нам ведь нужно убедиться, что балансировка работает.
Балансировка обычно осуществляется на базе потоков (IP-адрес/порт отправителя и IP-адрес/порт получателя), чтобы пакеты приходили в правильном порядке. Поэтому нам нужно создать два потока. Нет ничего проще:
1) ping непосредственно с msk-arbat-gw1 на 103.0.0.1
2) подключаемся телнетом на msk-arbat-gw1 (не забыв настроить параметры) с любого другого маршрутизатора и запускаем пинг с указанием источника (чтобы потоки чем-то отличались друг от друга)
После этого один пинг пойдёт через один линк, а второй через другой. Проверено
По умолчанию никак не учитывается пропускная способность внешних каналов. Такая возможность однако реализована и запускается командами
router bgp 64500 bgp dmzlink-bw neighbor 101.0.0.1 dmzlink-bw neighbor 102.0.0.1 dmzlink-bw
Задача №5
Схема: Общая схема сети
Условие: ЛинкМиАп получает от обоих провайдеров маршрут по умолчанию.
Задание:
Настроить балансировку исходящего трафика между маршрутами по умолчанию от провайдеров Балаган Телеком и Филькин Сертификат в пропорции 3 к 1.
Подробности задачи тут
Распределение нагрузки
Совсем другая песня с распределением – это более тонкая настройка путей исходящего и входящего трафика.
Исходящий
Исходящий трафик направляется в соответствии с маршрутами, полученными свыше.
Соответственно ими и надо управлять.
Напомним схему нашей сети
Итак, есть следующие способы:
- Настройка Weight. Это цисковский внутренний параметр – никуда не передаётся – работает в пределах маршрутизатора. У других вендоров тоже часто бывают аналоги (например, PreVal у Huawei). Тут ничего специфического – не будем даже останавливаться. (по умолчанию – 0)
Применение ко всем маршрутам полученным от соседа:
neighbor 192.168.1.1 weight 500Применение через route-map:
route-map SET_WEIGHT permit 10 set weight 500 ! router bgp 64500 neighbor 102.0.0.1 route-map SET_WEIGHT in
- Local Preference. Это параметр стандартный. По умолчанию 100 для всех маршрутов. Если вы хотите трафик на определённые подсети направлять в определённые линки, то Local Preference незаменим.
Выше мы уже рассматривали пример использования данного параметра.
- Вышеуказанная балансировка командой maximum-paths.
Задача №6
Схема: Общая схема сети
Условие: ЛинкМиАп получает Full View от обоих провайдеров.
Задание:
Не используя атрибуты weight, local preference или фильтрацию, настроить маршрутизатор msk-arbat-gw1 так, чтобы для исходящего трафика Балаган Телеком был основным, а Филькин Сертификат резервным.Подробности задачи тут
Входящий
Тут всё сложно.
Дело в том, что даже у крупных провайдеров исходящий трафик незначителен в сравнении со входящим. И там так остро не замечается неровное распределение.
Зато если речь идёт о Центрах Обработки Данных или хостинг-провайдерах, то ситуация обратная и вопрос балансировки стоит очень остро.
Тут мы крайне стеснены в средствах:
1) AS-Path Prepend
Один из самых частых приёмов – “ухудшение” пути. Нередко бывает так, что через одного провайдера ваши маршруты будут переданы с длиной AS-path больше, чем через другого. Разумеется, BGP выбирает первого, безапелляционно, и только через него будет передавать трафик. Чтобы выровнять ситуацию при анонсировании маршрутов можно добавить лишний “хоп” в AS-Path.
А бывает такая ситуация, что один провайдер предоставляет более широкий канал за небольшие деньги, но при этом путь через него длиннее и весь трафик уходит в другой – дорогой и узкий. Нам эта ситуация невыгодна и мы бы хотели, чтобы узкий канал стал резервным.
Вот её и разберём. Но придётся взять совершенно вырожденную ситуацию. К примеру, доступ из Балаган Телекома к сети ЛикМиАп.
Вот так выглядит таблица BGP и маршрутизации на провайдере Балаган Телеком в обычной ситуации:

Если мы хотим ухудшить основной путь (прямой линк между ними), то нужно добавить AS в список AS-Path:
router bgp 64500 neighbor 101.0.0.1 route-map AS_PATH_PREP out route-map AS_PATH_PREP permit 10 set as-path prepend 64500 64500Тогда выглядеть картинка будет так

Разумеется, выбирается путь с меньшей длиной AS-Path, то есть через Филькин Сертификат (AS6502)

Этот маршрут и добавится в таблицу маршрутизации.
Заметим, что обычно в AS-Path добавляют именно свой номер AS. Можно, конечно, и чужую, но вас не поймут в приличном обществе.
Таким образом мы добились того, что трафик пойдёт намеченным нами путём.Естественно, при падении одного из каналов трафик переключится на второй, независимо от настроенных AS-Path Prepend’ов.
2) MED
Multiexit Discriminator. В cisco он называется метрикой (Inter-AS метрика). MED является слабым атрибутом. Слабым, потому что он проверяется лишь на шестом шаге при выборе маршрута и оказывает по сути слабое влияние.
Если Local Preference влияет на выбор пути выхода трафика из Автономной системы, то MED передаётся в соседние AS и таким образом влияет на пути входа трафика.
Вообще MED и Local Preference часто путают новички, поэтому опишем в табличке разницу
Local Preference MED Определяет приоритет пути для выхода трафика Определяет приоритет пути для входа трафика Действует только внутри AS. Никак не передаётся в другие AS Передаётся в другие AS и намекает через какой путь передавать трафик предпочтительнее Может работать при подключении к разным AS Работает только при нескольких подключениях к одной AS Чем больше значение, тем выше приоритет Чем больше значение, тем ниже приоритет 
Не будем на нём останавливаться, потому что используют его редко, да и наша сеть для этого не подходит – должно быть несколько соединений между двумя AS, а у нас только по одному в каждую.
3) Анонс разных префиксов через разных ISP
Ещё один способ распределить нагрузку – раздавать разные сети разным провайдерам.
Сейчас в сети ЦОДа наши анонсы выглядят так:

То есть наша сеть 100.0.0.0/23 известна через два пути, но в таблицу маршрутизации добавится только один. Соответственно и весь трафик назад пойдёт одним – лучшим путём.
Но!
Мы можем разделить её на две подсети /24 и одну отдавать в Балаган Телеком, а другую в Филькин Сертификат.
Соответственно ЦОД будет знать про эти подсети через разные пути:
Настраивается это так.
Во-первых, мы прописываем все свои подсети – все 3: одну большую /23 и две маленькие /24:
router bgp 64500 network 100.0.0.0 mask 255.255.254.0 network 100.0.0.0 mask 255.255.255.0 network 100.0.1.0 mask 255.255.255.0Для того, чтобы они могли быть анонсированы, нужно создать маршруты до этих подсетей.
ip route 100.0.0.0 255.255.254.0 Null0 ip route 100.0.0.0 255.255.255.0 Null0 ip route 100.0.1.0 255.255.255.0 Null0А теперь создаём префикс-листы, которые разрешают каждый только одну подсеть /24 и общую /23.
ip prefix-list LIST_OUT1 seq 5 permit 100.0.0.0/24 ip prefix-list LIST_OUT1 seq 10 permit 100.0.0.0/23 ! ip prefix-list LIST_OUT2 seq 5 permit 100.0.1.0/24 ip prefix-list LIST_OUT2 seq 10 permit 100.0.0.0/23Осталось привязать префикс-листы к соседям.
router bgp 64500 neighbor 101.0.0.1 remote-as 64501 neighbor 101.0.0.1 prefix-list LIST_OUT1 out neighbor 102.0.0.1 remote-as 64502 neighbor 102.0.0.1 prefix-list LIST_OUT2 outПривязываем мы их на OUT – на исходящий, потому что речь о маршрутах, которые мы отправляем вовне.
Итак, соседу 101.0.0.1 (Балаган Телеком) мы будем анонсировать сети 100.0.0.0/24 и 100.0.0.0/23.
А соседу 102.0.0.1 (Филькин Сертификат) – сети 100.0.1.0/24 и 100.0.0.0/23.
Результат будет таким:

Вроде бы, неправильно, потому что у нас по два маршрута в каждую сеть /24 – через Балаган Телеком и через Филькин Сертификат.
Но если приглядеться, то вы увидите, что согласно AS-Path у нас такие маршруты:

То есть, по сути всё правильно. Да и в таблицу маршрутизации всё помещается правильно:

Теперь осталось ответить на вопрос какого лешего мы тащили за собой большую подсеть /23? Ведь согласно правилу Longest prefix match более точные маршруты предпочтительней, то есть /23, как бы и не нужен, когда есть /24.
Но вообразим себе ситуацию, когда падает сеть Балаган Телеком. Что при этом произойдёт
Существуют также специальные организации, которые отслеживают анонсы BGP в Интернете и, если вдруг происходит что-то неожиданное, может уведомить владельца сети. Подсеть 100.0.0.0/24 перестанет быть известной в интернете – ведь только Балаган Телеком что-то знал о ней благодаря нашей настройке. Соответственно, ляжет и часть нашей сети. Но! Нас спасает более общий маршрут 100.0.0.0/23. Филькин Сертификат знает о нём и анонсирует его в Интернет. Соответственно, хоть ЦОД и не знает про сеть 100.0.0.0/24, он знает про 100.0.0.0/23 и пустит трафик в сторону Филькина Сертификата.

То есть, слава Лейбницу, мы застрахованы от такой ситуации.
Надо иметь ввиду, что помимо настройки маршрутизатора вам придётся завести все три сети в базе данных RIPE. Там должны быть и обе сети /24 и сеть /23.
4) BGP Community
C помощью BGP Community можно давать провайдеру указания, что делать с префиксом, кому передавать, кому нет, какой local preference у себя ставить и т.д. Рассматривать этот вариант сейчас не будем, потому что тему коммьюнити мы перенесём в следующий выпуск.
Задача №7
Схема: Общая схема сети
Условие: На маршрутизаторе msk-arbat-gw1 настроено управление входящим и исходящим трафиком. Основной провайдер Балаган Телеком, резервый – Филькин Сертификат. При проверке настроек оказалось, что исходящий трафик передается правильно. При проверке входящего трафика, оказалось, что входящий трафик идет и через провайдера Балаган Телеком, но когда отключается Балаган Телеком, входящий трафик не идет через Филькин Сертификат.
Задание: Исправить настройки.Подробности задачи и конфигурация тут
PBR
Все технологии маршрутизации, которые мы применяли до этого момента в наших статьях, будь то статическая маршрутизация, динамическая маршрутизация (IGP или EGP), в своей работе принимали во внимание только один признак пакета: адрес назначения. Все они, упрощенно, действовали по одному принципу: смотрели, куда идет пакет, находили в таблице маршрутизации наиболее специфичный маршрут до пункта назначения (longest match), и переправляли пакет в тот интерфейс, который был записан в таблице напротив этого самого маршрута. В этом, в общем-то, и состоит суть маршрутизации. А что, если такой порядок вещей нас не устраивает? Что, если мы хотим маршрутизировать пакет, отталкиваясь от адреса источника? Или нам нужно
мальчикиHTTP направо,девочкиSNMP налево?В такой ситуации нам приходит на помощь маршрутизация на базе политик ака PBR (Policy based routing). Эта технология позволяет нам управлять трафиком, базируясь на следующих признаках пакета:
- Адрес источника (или комбинация адрес источника-адрес получателя)
- Информация 7 уровня (приложений) OSI
- Интерфейс, в который пришел пакет
- QoS-метки
- Вообще говоря, любая информация, используемая в extended-ACL (порт источника\получателя, протокол и прочее, в любых комбинациях). Т.е. если мы можем выделить интересующий нас трафик с помощью расширенного ACL, мы сможем его смаршрутизировать, как нам будет угодно.
Плюсы использования PBR очевидны: невероятная гибкость маршрутизации. Но и минусы тоже присутствуют:
- Все нужно писать руками, отсюда много работы и риск ошибки
- Производительность. На большинстве железок PBR работает медленнее, чем обычный роутинг (исключение составляют каталисты 6500, к ним есть супервайзер с железной поддержкой PBR)
Политика, на основе которой осуществляется PBR, создается командой route map POLICY_NAME, и содержит два раздела:
- Выделение нужного трафика. Осуществляется либо с помощью ACL, либо в зависимости от интерфейса, в который трафик пришел. За это отвечает команда match в режиме конфигурации route map
- Применение действия к этому трафику. За это отвечает команда set
Немного практики для закрепления
Имеем вот такую топологию:
В данный момент трафик R1-R5 и обратно идет по маршруту R1-R2-R4-R5, для удобства, адреса присвоены так, чтобы последняя цифра адреса была номером маршрутизатора:
R1#traceroute 192.168.100.5
1 192.168.0.2 20 msec 36 msec 20 msec
2 192.168.2.4 40 msec 44 msec 16 msec
3 192.168.100.5 56 msec * 84 msecR5#traceroute 192.168.0.1
1 192.168.100.4 56 msec 40 msec 8 msec
2 192.168.2.2 20 msec 24 msec 16 msec
3 192.168.0.1 64 msec * 84 msecДля примера, предположим, что нам нужно, чтобы обратно трафик от R5 (с его адресом в источнике) шел по маршруту R5-R4-R3-R1. По схеме очевидно, что решение об этом должен принимать R4. На нем сначала создаем ACL, который отбирает нужные нам пакеты:
R4(config)#access-list 100 permit ip host 192.168.100.5 anyЗатем создаем политику маршрутизации с именем “BACK”:
R4(config)#route-map BACKВнутри нее говорим, какой трафик нас интересует:
R4(config-route-map)#match ip address 100И что с ним делать:
R4(config-route-map)#set ip next-hop 192.168.3.3После чего заходим на интерфейс, который смотрит в сторону R5 (PBR работает с входящим трафиком!) и применяем на нем полученную политику:
R4(config)#int fa1/0 R4(config-if)#ip policy route-map BACKПроверяем:
R5#traceroute 192.168.0.1
1 192.168.100.4 40 msec 40 msec 16 msec
2 192.168.3.3 52 msec 52 msec 44 msec
3 192.168.1.1 56 msec * 68 msecРаботает! А теперь посмотрим внимательно на схему и подумаем: все ли хорошо?
А вот и нет!
Следуя данному ACL, у нас заворачивается на R3 весь трафик с источником R5. А это значит, что если, например, R5 захочет попасть на R2, он, вместо короткого и очевидного маршрута R5-R4-R2, будет послан по маршруту R5-R4-R3-R1-R2. Поэтому, нужно очень аккуратно и вдумчиво составлять ACL для PBR, делая его максимально специфичным.
В этом примере мы в качестве действия, применяемого к трафику, выбрали переопределение некстхопа (узла сети, куда дальше отправится пакет). А что еще можно сделать с помощью PBR? Имеются в наличие команды:
- set ip next-hop
- set interface
- set ip default next-hop
- set default interface
С первыми двумя все относительно понятно – они переопределяют некстхоп и интерфейс, из которого пакет будет выходить (чаще всего set interface применяется для point-to-point линков). А в случае, если мы применяем команды set ip default next-hop или set default interface, роутер сначала смотрит таблицу маршрутизации, и, если там имеется маршрут для проверяемого пакет, отправляет его соответственно таблице. Если маршрута нет, пакет отправляется, как сказано в политике. К примеру, если бы мы в нашей топологии вместо set ip next-hop 192.168.3.3 скомандовали set ip default next-hop 192.168.3.3, ничего бы не поменялось, так как у R4 есть маршрут к R1 (через R2). Но если бы он отсутствовал, трафик направлялся бы к R3.
Вообще говоря, с помощью команды set можно изменять очень много в подопытном пакете: начиная от меток QoS или MPLS и заканчивая атрибутами BGP
Задача №8
Условие: ЛинкМиАп использует статические маршруты к провайдерам (не BGP).Схема и конфигурация. Маршрутизаторы провайдеров также не используют BGP.
Задание: Настроить переключение между провайдерами.
Маршрут по умолчанию к Балаган Телеком должен использоваться до тех пор, пока приходят icmp-ответы на пинг google (103.0.0.10) ИЛИ yandex (103.0.0.20). Запросы должны отправляться через Балаган Телеком. Если ни один из указанных ресурсов не отвечает, маршрут по умолчанию должен переключиться на провайдера Филькин Сертификат. Для того чтобы переключение не происходило из-за временной потери отдельных icmp-ответов, необходимо установить задержку переключения, как минимум, 5 секунд.
Подробности задачи тут
IP SLA
А теперь самое вкусное: представим, что в нашей схеме основной путь R4-R2-R1 обслуживает один провайдер, а запасной R4-R3-R1 – другой. Иногда у первого провайдера бывают проблемы с нагрузкой, которые приводят к тому, что наш голосовой трафик начинает страдать. При этом, другой маршрут не нагружен и хорошо бы в этот момент перенести голос на него. Ок, пишем роут-мап, как мы делали выше, который выделяет голосовой трафик и направляем его через нормально работающего провайдера. А тут – оп, ситуация поменялась на противоположную – опять надо менять все обратно. Будни техподдержки: “И такая дребедень целый день: то тюлень позвонит, то олень”. А вот бы было круто, если можно было бы отслеживать нужные нам характеристики основного канала (например, задержку или джиттер), и в, зависимости от их значения, автоматически направлять голос или видео по основному или резервному каналу, да? Так вот, чудеса бывают. В нашем случае чудо называется IP SLA.
Эта технология, по сути, есть активный мониторинг сети, т.е. генерирование некоего трафика с целью оценить ту или иную характеристику сети. Но мониторингом все не заканчивается – роутер может, используя полученные данные, влиять на принятие решений по маршрутизации, таким образом реагируя и разрешая проблему. К примеру, разгружать занятой канал, распределяя нагрузку по другим.
Без лишних слов, сразу к настройке. Для начала, нам нужно сказать, что мы хотим мониторить. Создаем объект мониторинга, назначаем ему номер:
R4(config)#ip sla 1Так-с, что мы тут можем мониторить?
R4(config-ip-sla)#? IP SLAs entry configuration commands:
dhcp DHCP Operation
dns DNS Query Operation
exit Exit Operation Configuration
frame-relay Frame-relay Operation
ftp FTP Operation
http HTTP Operation
icmp-echo ICMP Echo Operation
icmp-jitter ICMP Jitter Operation
mpls MPLS Operation
path-echo Path Discovered ICMP Echo Operation
path-jitter Path Discovered ICMP Jitter Operation
slm SLM Operation
tcp-connect TCP Connect Operation
udp-echo UDP Echo Operation
udp-jitter UDP Jitter Operation
voip Voice Over IP OperationНужно сказать, что синтаксис команд, относящихся к IP SLA, претерпел некоторые изменения: начиная с IOS 12.4(4)T он такой, как в статье, до этого некоторые команды писались по другому. Например, вместо ip sla 1 было rtr 1 или вместо ip sla responder – rtr responder
Как видите, список внушительный, поэтому останавливаться не будем, для интересующихся есть подробная статья на циско.ком.
Задача №9
Схема и конфигурация. Маршрутизаторы провайдеров также не используют BGP.
Задание:
Настроить маршрутизацию таким образом, чтобы HTTP-трафик из локальной сети 10.0.1.0 шел через Балаган Телеком, а весь трафик из сети 10.0.2.0 через Филькин Сертификат. Если в адресе отправителя фигурирует любой другой адрес, трафик должен быть отброшен, а не маршрутизироваться по стандартной таблице маршрутизации (задание надо выполнить не используя фильтрацию с помощью ACL, примененных на интерфейсе).Дополнительное условие: Правила PBR должны работать так только если соответствующий провайдер доступен (в данной задаче достаточно проверки доступности ближайшего устройства провайдера). Иначе должна использоваться стандартная таблица маршрутизации.
Подробности задачи тут
Обычно, работу IP SLA рассматривают на простейшем примере icmp-echo. То есть, в случае, если мы можем пинговать тот конец линии, трафик идет по ней, если не можем – по другой. Но мы пойдем путем чуть посложнее. Итак, нас интересуют характеристики канала, важные для голосового трафика, например, джиттер. Конкретнее, udp-jitter, поэтому пишем
R4(config-ip-sla)#udp-jitter 192.168.200.1 55555В этой команде после указания вида проверки (udp-jitter) идет ip адрес, куда будут отсылаться пробы (т.е. меряем от нас до 192.168.200.1 – это лупбек на R1) и порт (от балды 55555). Затем можно настроить частоту проверок (по умолчанию 60 секунд):
R4(config-ip-sla-jitter)#frequency 10и предельное значение, при превышении которого объект ip sla 1 рапортует о недоступности:
R4(config-ip-sla-jitter)#threshold 10Некоторые виды измерений в IP SLA требуют наличия “на той стороне” так называемого “ответчика” (responder), некоторые (например, FTP, HTTP, DHCP, DNS) нет. Наш udp-jitter требует, поэтому, прежде чем запускать измерения, нужно подготовить R1:
R1(config)#ip sla responderТеперь нам нужно запустить сбор статистики. Командуем
R4(config)#ip sla schedule 1 start-time now life foreverТ.е. запускаем объект мониторинга 1 прямо сейчас и до конца дней.
Мы не можем менять параметры объекта, если запущен сбор статистики. Т.е. чтобы поменять, например, частоту проб, нам нужно сначала выключить сбор информации с него: no ip sla schedule 1
Теперь уже можем посмотреть, что у нас там собирается:
R4#sh ip sla statistics 1
Round Trip Time (RTT) for Index 1
Latest RTT: 36 milliseconds
Latest operation start time: *00:39:01.531 UTC Fri Mar 1 2002
Latest operation return code: OK
RTT Values:
Number Of RTT: 10 RTT Min/Avg/Max: 19/36/52 milliseconds
Latency one-way time:
Number of Latency one-way Samples: 0
Source to Destination Latency one way Min/Avg/Max: 0/0/0 milliseconds
Destination to Source Latency one way Min/Avg/Max: 0/0/0 milliseconds
Jitter Time:
Number of SD Jitter Samples: 9
Number of DS Jitter Samples: 9
Source to Destination Jitter Min/Avg/Max: 0/5/20 milliseconds
Destination to Source Jitter Min/Avg/Max: 0/16/28 milliseconds
Packet Loss Values:
Loss Source to Destination: 0 Loss Destination to Source: 0
Out Of Sequence: 0 Tail Drop: 0
Packet Late Arrival: 0 Packet Skipped: 0
Voice Score Values:
Calculated Planning Impairment Factor (ICPIF): 0
Mean Opinion Score (MOS): 0
Number of successes: 12
Number of failures: 0
Operation time to live: Foreverа также что мы там наконфигурировали
R4#sh ip sla conf
IP SLAs Infrastructure Engine-II
Entry number: 1
Owner:
Tag:
Type of operation to perform: udp-jitter
Target address/Source address: 192.168.200.1/0.0.0.0
Target port/Source port: 55555/0
Request size (ARR data portion): 32
Operation timeout (milliseconds): 5000
Packet Interval (milliseconds)/Number of packets: 20/10
Type Of Service parameters: 0x0
Verify data: No
Vrf Name:
Control Packets: enabled
Schedule:
Operation frequency (seconds): 10 (not considered if randomly scheduled)
Next Scheduled Start Time: Pending trigger
Group Scheduled: FALSE
Randomly Scheduled: FALSE
Life (seconds): 3600
Entry Ageout (seconds): never
Recurring (Starting Everyday): FALSE
Status of entry (SNMP RowStatus): Active
Threshold (milliseconds): 10
Distribution Statistics:
Number of statistic hours kept: 2
Number of statistic distribution buckets kept: 1
Statistic distribution interval (milliseconds): 4294967295
Enhanced History:Теперь настраиваем так называемый track (неправильный, но понятный перевод “отслеживатель”). Именно к его состоянию привязываются впоследствии действия в роут-мапе. В track можно выставить задержку переключения между состояниями, что позволяет решить проблему, когда у нас по одной неудачной пробе меняется маршрутизация, а по следующей, уже удачной, меняется обратно. Указываем номер track и к какому номеру объекта ip sla мы его подключаем (rtr 1):
R4(config)#track 1 rtr 1Настраиваем задержку:
R4(config-track)#delay up 10 down 15Это означает: если объект мониторинга упал и не поднялся в течение 15 секунд, переводим track в состояние down. Если объект был в состоянии down, но поднялся и находится в поднятом состоянии хотя бы 10 секунд, переводим track в состояние up.
Следующим действием нам нужно привязать track к нашей роут-мапе. Напомню, стандартный путь от R5 к R1 идет через R2, но у нас имеется роут-мапа BACK, переназначающая стандартное положение вещей в случае, если источник R5:
R4#sh run | sec route-map
ip policy route-map BACK
route-map BACK permit 10
match ip address 100
set ip next-hop 192.168.3.3Если мы привяжем наш мониторинг к этой мапе, заменив команду set ip next-hop 192.168.3.3 на set ip next-hop verify-availability 192.168.3.3 10 track 1, получим обратный нужному эффект: в случае падения трека (из-за превышения показателя джиттера в sla 1), мапа не будет отрабатываться (все будет идти согласно таблице маршрутизации), и наоборот, в случае нормальных значений, трек будет up, и трафик будет идти через R3.
Как это работает: роутер видит, что пакет подпадает под условия match, но потом не сразу делает set, как в предыдущем примере с PBR, а промежуточным действием проверяет сначала состояние трека 1, а затем, если он поднят (up), уже делается set, если нет – переходит к следующей строчке роут-мапы.
Для того, чтобы наша мапа заработала, как надо, нам нужно как-то инвертировать значение трека, т.е. когда джиттер большой, наш трек должен быть UP, и наоборот. В этом нам поможет такая штука, как track list. В IP SLA существует возможность объединять в треке список других треков (которые, по сути, выдают на выходе 1 или 0) и производить над ними логические операции OR или AND, а результатом этих операций будет состояние этого трека. Кроме этого, мы можем применить логическое отрицание к состоянию трека. Создаем трек-лист:
R4(config)#track 2 list boolean or
Единственным в этом “списке” будет логическое отрицание значения трека 1:
R4(config-track)#object 1 notТеперь привязываем роут-мап к этому треку
R4(config)#route-map BACK R4(config-route-map)#no set ip next-hop 192.168.3.3 R4(config-route-map)#set ip next-hop verify-availability 192.168.3.3 10 tr 2Цифра 10 после адреса некстхопа – это его порядковый номер (sequence number). Мы можем, к примеру, использовать его так:
route-map BACK permit 10 match ip address 100 set ip next-hop verify-availability 192.168.3.3 10 track 1 set ip next-hop verify-availability 192.168.2.2 20 track 2Тут такая логика: выбираем трафик, подпадающий под ACL 100, затем идет промежуточная проверка track 1, если он up, ставим пакету некстхоп 192.168.3.3, если down, переходим к следующему порядковому номеру (20 в данном случае), опять же промежуточно проверяем состояние трека (уже другого, 2), в зависимости от результата, ставим некстхоп 192.168.2.2 или отправляем с миром (маршрутизироваться на общих основаниях).
Давайте теперь немножко словами порассуждаем, что же мы такое накрутили: итак, измерения джиттера у нас идут от источника R4 к респондеру R1 по маршруту через R2. Максимальное допустимое значение джиттера на этом маршруте у нас – 10. В случае, если джиттер превышает это значение и держится на этом уровне 15 секунд, мы переключаем трафик, генерируемый R5, на маршрут через R3. Если джиттер падает ниже 10 и держится там минимум 10 секунд, пускаем трафик от R5 по стандартному маршруту. Попробуйте для закрепления материала найти, в каких командах задаются все эти значения.
Итак, мы достигли цели: теперь, в случае ухудшения качества основного канала (ну, по крайней мере, значений udp-джиттера), мы переходим на резервный. Но что, если и там тоже не очень? Может, попробуем с помощью IP SLA решить и эту проблему?
Попробуем выстроить логику того, что мы хотим сделать. Мы хотим перед переключением на резервный канал проверять, как у нас обстоит дело с джиттером на нем. Для этого нам нужно завести дополнительный объект мониторинга, который будет считать джиттер на пути R4-R3-R1, пусть это будет 2. Сделаем его аналогичным первому, с теми же значениями. Условием переключения на резервный канал тогда будет: объект 1 down И объект 2 up. Чтобы измерять джиттер не по основному каналу, придется пойти на хитрость: сделать loopback-интерфейсы на R1 и R4, прописать статические маршруты через R3 туда-обратно, и использовать эти адреса для объекта SLA 2.
R1(config)#int lo1 R1(config-if)#ip add 192.168.30.1 255.255.255.0 R1(config-if)#exit R1(config)#ip route 192.168.31.0 255.255.255.0 192.168.1.3 R3(config)#ip route 192.168.30.0 255.255.255.0 192.168.1.1 R3(config)#ip route 192.168.31.0 255.255.255.0 192.168.3.4 R4(config)#int lo0 R4(config-if)#ip add 192.168.31.4 255.255.255.0 R4(config-ip-sla-jitter)#exit R4(config)#ip sla 2 R4(config-ip-sla)#udp-jitter 192.168.30.1 55555 source-ip 192.168.31.4 R4(config-ip-sla-jitter)#threshold 10 R4(config-ip-sla-jitter)#frequency 10 R4(config-ip-sla-jitter)#exit R4(config)#ip route 192.168.30.0 255.255.255.0 192.168.3.3 R4(config)#ip sla schedule 2 start-time now life forever R4(config)#track 3 rtr 2Теперь меняем условие трека 2, к которому привязана роут-мапа:
R4(config)#track 2 list boolean and R4(config-track)#object 1 not R4(config-track)#object 3Вуаля, теперь трафик R5->R1 переключается на запасной маршрут только в том случае, если джиттер основного канала больше 10 и, в это же время, джиттер запасного меньше 10. В случае, если высокий джиттер наблюдается на обоих каналах, трафик идет по основному и молча страдает.
Состояние трека можно привязать также к статическому маршруту: например, мы можем командой ip route 0.0.0.0 0.0.0.0 192.168.1.1 track 1 сделать шлюзом по умолчанию 192.168.1.1, который будет связан с треком 1 (который, в свою очередь, может проверять наличие этого самого 192.168.1.1 в сети или измерять какие-нибудь важные характеристики качества связи с ним). В случае, если связанный трек падает, маршрут убирается из таблицы маршрутизации.
Также будет полезным упомянуть, что информацию, получаемую через IP SLA, можно вытащить через SNMP, чтобы потом можно было ее хранить и анализировать где-нибудь в вашей системе мониторинга. Можно даже настроить SNMP-traps.
Задача №10
Схема: как и для других задач по PBR. Конфигурация ниже.
Условие: ЛинкМиАп использует статические маршруты к провайдерам (не BGP).На маршрутизаторе msk-arbat-gw1 настроена PBR: HTTP-трафик должен идти через провайдера Филькин Сертификат, а трафик из сети 10.0.2.0 должен идти через Балаган Телеком. Указанный трафик передается правильно, но не маршрутизируется остальной трафик из локальной сети, который должен передаваться через провайдера Балаган Телеком.
Задание:
Исправить настройки таким образом, чтобы они соответствовали условиям.Подробности задачи и конфигурация тут
Материалы выпуска
Конфигурация устройств:
- Базовый BGP
- AS-PATH ACL
- AS-PATH Prepend
- Load Balancing
- Load Sharing на основе Prefix List
- Prefix List
- Route Map
Полезные ссылки
Поредели со временем - пришлось выкинуть бОльшую часть.
BGP
IP SLA
Благодарности
Статью для вас подготовили eucariot и Gluck. За помощь спасибо JDima. Задачки нам написала несравненная Наташа Самойленко.
У цикла “Сети для самых маленьких” есть свой сайт: linkmeup.ru, где вы сможете найти все выпуски аккуратно сложенными и готовыми к вдумчивому чтению.
Авторы
- eucariot - Марат Сибгатулин (inst, tg, in)
- Макс Gluck
Оставайтесь на связи
Пишите нам: info@linkmeup.ru
Канал в телеграме: t.me/linkmeup_podcast
Канал на youtube: youtube.com/c/linkmeup-podcast
Подкаст доступен в iTunes, Google Подкастах, Яндекс Музыке, Castbox
Сообщество в вк: vk.com/linkmeup
Группа в фб: www.facebook.com/linkmeup.sdsm
Добавить RSS в подкаст-плеер.
Пообщаться в общем чате в тг: https://t.me/linkmeup_chatПоддержите проект:



 68
68
 464233
464233
 61
61
Ещё статьи
 Что такое patreon и что мы там забыли?Друзья, Как было объявлено в прямом эфире 20 декабря, наш проект запустил свою страничку на сайте patreon.com и следующие несколько абзацев я, как и обещал, более подробно опишу, что это ...23 декабря 2015
Что такое patreon и что мы там забыли?Друзья, Как было объявлено в прямом эфире 20 декабря, наш проект запустил свою страничку на сайте patreon.com и следующие несколько абзацев я, как и обещал, более подробно опишу, что это ...23 декабря 2015 LINKMEETUP 8. NSK. 2026.02.05Мы умудрились сделать уже 8-й митап. Музыка играла, пиво лилось, доклады читались, люди общалис ь. Вторая наша конференция в Новосибирске собрала 300 человек, и в последние дни перед мероприятием мы ...10 февраля 2026
GNS3 в облаке=================================== Статья написана Дмитрием Фиголем для Linkmeup.ru =================================== Привет! Сегодня я вам расскажу, как настроить GNS3 сервер в облачных сервисах. А в конце будет небольшой FAQ по GNS3. Для примера ...14 марта 2016
LINKMEETUP 8. NSK. 2026.02.05Мы умудрились сделать уже 8-й митап. Музыка играла, пиво лилось, доклады читались, люди общалис ь. Вторая наша конференция в Новосибирске собрала 300 человек, и в последние дни перед мероприятием мы ...10 февраля 2026
GNS3 в облаке=================================== Статья написана Дмитрием Фиголем для Linkmeup.ru =================================== Привет! Сегодня я вам расскажу, как настроить GNS3 сервер в облачных сервисах. А в конце будет небольшой FAQ по GNS3. Для примера ...14 марта 2016
61 коментарий
Load Sharing на основе Prefix List — ссылка ведет на Load Balancing
Спасибо вам, за вашу работу!
Спасибо Вам за статью ребята! Очень благородное дело делаете, делясь бесценными знаниями. Изучал Вашу статью две недели, кучу раз пересмотрел видео 8ой части. Все очень доходчиво. Оставил коменты к некоторым задачам и еще хотел утонить по поводу схемы, которая показана в разделе «Анонс разных префиксов разным ISP». Мне кажется, что было бы нагляднее прорисовать 2 разных маршрута к сети 100.0.0.0/24 одним видом цвета. У Вас прорисовано разным видом цвета. Немного больше времени вглядывался и просматривал путь трафика от ЦОДа до нашего бордера. В любом случае еще раз спасибо за грандиозную работу. Рекомендую Ваши статьи всем начинающим, продолжающим, продвинутым сетевым инженерам, потому любой инженер из этих уровней непременно подчерпнет здесь много нового!
Имеется IOS-XE 03.06.05 на С3850-24Т в стэке, на нем поднят BGP 4194304к памяти, пару раз провайдер, упаская из виду ранее достигнутые договоренности, слал мне все маршруты, в результате чего связь падала, вся память уходила под маршруты. Подскажите как от этого затится? Сам вижу такие решения
1. Поставить нормальный роутер
2. убедить провайдера не забывать наши договоренности
3. настроить циску на принимать ничего кроме дефолт роута
Вот можно ли сделать п.3? я не знаю…
Подскажите пожалуйста, как можно проверить наличие балансировки для исходящего трафика при подключении к разным провайдерам? На интерфейсах к ним настроены разные пропускные способности (одна больше другой в 2 раза). В настройках бгп включено 2 пути для трафика и bgp bestpath as-path multipath-relax. Если делаем пинг с самого роутера + одновременно ещё один пинг, подключаясь на него с другого роутера (при этом адрес назначения пинга отличается от первого), то пакеты делятся не пропорционально, а пополам.
Добрый день,
Вот здесь, в пункте Route map, даны комментарии к данным командам, но вроде только к их первой части. Как человек только начинающий знакомиться с технологией не могу уловить смысл в данном случае.
При этом sh ip bgp filter-list показывает, что вроде-то все должно работать:
Link_ME_UP#sh ip bgp filter-list 100
BGP table version is 8, local router ID is 100.0.0.1
Status codes: s suppressed, d damped, h history, * valid, > best, i — internal,
r RIB-failure, S Stale
Origin codes: i — IGP, e — EGP,? — incomplete
Network Next Hop Metric LocPrf Weight Path
* 0.0.0.0 102.0.0.1 0 0 64502 i
*> 100.0.0.0/23 0.0.0.0 0 32768 i
* 101.0.0.0/20 102.0.0.1 0 64502 64501 i
*> 102.0.0.0/21 102.0.0.1 0 0 64502 i
* 101.0.0.1 0 64501 64502 i
* 103.0.0.0/22 102.0.0.1 0 64502 64503 i
*> 101.0.0.1 0 64501 64503 i
* 120.0.0.0/24 102.0.0.1 0 64502 64503 i
*> 101.0.0.1 0 64501 64503 i
Добрый день!
У меня не получается отфильтровать локальные маршруты от 64501 по AS-path. Делаю все как в примере — но не фильтруются, может кто подскажет в чем может быть проблема?
Link_ME_UP#sh ip as-path-access-list
AS path access list 100
deny ^64501$
permit .*
Link_ME_UP#sh run | s bgp
router bgp 64500
no synchronization
bgp log-neighbor-changes
network 100.0.0.0 mask 255.255.254.0
neighbor 101.0.0.1 remote-as 64501
neighbor 101.0.0.1 filter-list 100 in
neighbor 102.0.0.1 remote-as 64502
no auto-summary
Link_ME_UP#sh ip bgp
BGP table version is 8, local router ID is 100.0.0.1
Status codes: s suppressed, d damped, h history, * valid, > best, i — internal,
r RIB-failure, S Stale
Origin codes: i — IGP, e — EGP,? — incomplete
Network Next Hop Metric LocPrf Weight Path
* 0.0.0.0 102.0.0.1 0 0 64502 i
*> 101.0.0.1 0 0 64501 i
*> 100.0.0.0/23 0.0.0.0 0 32768 i
* 101.0.0.0/20 102.0.0.1 0 64502 64501 i
*> 101.0.0.1 0 0 64501 i
*> 102.0.0.0/21 102.0.0.1 0 0 64502 i
* 101.0.0.1 0 64501 64502 i
* 103.0.0.0/22 102.0.0.1 0 64502 64503 i
*> 101.0.0.1 0 64501 64503 i
* 120.0.0.0/24 102.0.0.1 0 64502 64503 i
*> 101.0.0.1 0 64501 64503 i
Конфигурация остальных роутеров по дефолту ( за исключением default-originate на граничных роутерах к AS64500 — sh ip bgp выше показывает это — но это никак не должно влиять на фильтрацию по сути)
Если надо могу выслать полностью файл лабы, чтобы не собирать её 🙂
Text bullying is often characterized by mean and embarrassing messages to or about someone being sent using cell phone text messaging. Navigate back to "Settings" and select the program you need to run based upon the list below: Select "Bluebug" if you need read and write access to the target device phone book contacts, read access to SMS (text messages) or the ability to place a phone call from the target device, Cell phone spyware mobistealth. After entering your username and password you will be brought to the Online Control Panel. Photo: Connect Apps regularly pop up in divorce cases, experts say. Is There Spy Software on My Cell Phone How to Detect if You are. 22 Mar 2013 I'll go over a few things you can look out for and you don't need to be a If you think someone is spying on your cell phone you need to get familiar with If you are a little more advanced it is sometimes possible to find spy If someone wants to monitor your iPhone they will need to. mobile spy reviews, How to find out if mobile spy is on your iphone. How to Remove the iPhone Monitoring Software on — Mobile Spy. Instructions for removing or uninstalling Mobile Spy from iPhone iOS. This process is designed to help you uninstall Mobile Spy from your iPhone 3G 3Gs 4 4S 5 5c or5s. Tap the Smartphone If Cydia is hidden: find us on FacebookYou can monitor your employees in order to see if they use their phone or their time for other reasons. What is Cell Phone Spy Software? You will only need to activate it once, Cell phone tracker online real. You can then view activities by logging in from any computer or mobile web browser. Every phone spy program listed below is 100% undetectable – the application runs in the background without the user being aware. They can be used in various purposes: By parents to keep an eye on their kids; By employers to track the employers’ phones usage as well as to prevent frauds; By spouses to check on their partners.
Здравствуйте. Не раз перечитывал литературу по BGP в различных источниках. Огромное спасибо и вам очень много почерпнул. Мне хочется задать вопрос по конфигурированию BGP на quagga. В линуксе есть такая конструкция:
Трафик будет распределяться согласно весу, такая конструкция была проверена, это действительно работает.
Чем не load balancing для исходящего трафика? Те как аналог bgp dmzlink-bw?
Если это нельзя использовать то не могли бы вы пояснить почему?
Добрый день. Немного не понял про Default Route BGP.Немного не понимаю, что нам будет приходить есть мы установим такую сессию с апстримом.Грубо говоря, нам будет приходить айпи бордера апстрим провайдера, а ля «у него BGP Full view, он всё про всех знает, ему отправляй всё»? Тогда какой реальный профит от BGP соединения? Только лишь анонс своей подсети?
Всем доброго здравия. Присоединяюсь к благодарностям за непочатый труд в создании сего бесценного обучающего материала.
Интересует меня одна вещь. В том месте где настроены префикс листы и отправляется длинный пинг на узел из сети 100.0.0.0/24 для эксперимента мы гасим интерфейс fa0/0 (который смотрит в msk-arbat-gw1) на маршрутизаторе балаган телекома. Пинг при этом теряется меньше чем на 1 секунду. Но ежели мы погасим интерфейс fa0/0 (который смотрит в балаган телеком) на msk-arbat-gw1, то пинг пропадёт на секунд 60. Собственно хотелось бы узнать, есть ли этому объяснение? Вроде рвём один и тот же линк, а результаты отличаются порядком.
Никак не могу понять у меня между двумя AS маршруты ходят с локал преф. все в порядке, маршрут до сети другой как дефолтный. А трафик не ходит… что это может быть…
Все понятно, доступно и интересно.
Спасибо большое!
цикл закончился, или будет продолжение?
Да, спасибо. Я думаю, это полезно будет добавить в статью. И про /25 Тоже.
Стоит добавить следующую информацию:
с 14 сентября 2012 года решением RIPE IPv4 адреса больше не выдаются.
Возможна только регистрация IPv6.
таким образом официально получить блок PI IPv4 адресов можно только став LIR’ом
>Регистрационный платеж в RIPE NCC €2000
>Ежегодный платеж в RIPE NCC €1800
Неофициально приобретение PI адресов выглядит как покупка части/всего бизнеса, так называемый черный рынок IP адресов =)
Было бы неплохо добавить информацию о /25 и ниже сетях, о том что анонсы этих сетей блокируются на большинстве провайдеров. В примере вы взяли /23 сеть и деагрегировали до /24, не указав почему выбраны именно эти размеры.
Не совсем понятно как сделать, чтоб к датацентру ходить только через один провайдер, получая от него дефолт. Но в случае падения провайдера, переключаться на другой…
Спасибо Вам за проект. А нет ли «открытых» bgp серверов что бы можно было поднять сессию и получить энное количество full view для теста железки.
Большое Вам спасибо, за и этот цикл. Но есть вопрос… А нет ли этих статей в PDF? Одним сборником или по каждой статье свой PDF?
Ребята, то, что вы делаете — это ГРАНДИОЗНАЯ РАБОТА! Спасибо вам!
Мне кажется, было бы немного удобнее смотреть, если бы в консоли шрифт был поярче. А то чёрный фон сливается с бледно-тёмно-зелёным шрифтом, если смотреть в окошке — приходится разворачивать на весь экран.
Про RouteMap, точнее про пример вопрос есть.
Задача поставлена: «в подсеть 120.0.0.0/24 предпочтительно ходить через Филькин Сертификат, а в 103.0.0.0/22 через Балаган Телеком.»
Смотрим на результат в sh ip bgp:
>103.0.0.0/22 next_hop 102.0.0.1, через Филькин
>120.0.0.0/24 next_hop 101.0.0.1, через Балаган
Т.е. если я правильно понял, либо задачу надо поменять, либо роут-мапы.
Хорошо конечно, но свалить в одну статью BGP и IP SLA ИМХО очень лишнее.
Автономная система «для маленьких» это вряд-ли, а вот два провайдера — это запросто.
Статью о SLA (опять же имхо) было лучше объединить с QoS.
ps udp-jitter не лучшая идея, к удаленной стороне редко есть доступ icmp-jitter дает тот же результат и не требует доступ к удаленной стороне.
Отличная статья!
Одно замечание:
> 1) Предотвращение петель маршрутизации. В AS-Path не должно быть повторяющихся номеров (кроме случая AS-Path Prepend)"
Это не единственный случай. Иногда нужно связать два куска одной автономной системы, не имеющие L2-соединения друг с другом. И тут нам на помощь приходят allowas-in и as-override.
Вмето перезапуска проекта, можно было сделать clear ip bgp * soft
Сам спросил сам нашел supportforums.cisco.com/document/24806/how-configure-bgp-accept-only-default-routes-using-prefix-lists, не тестировал еще…
Извиняюсь за испуг — это был глюк GNS3. Перезагрузил проеткт — все заработало как надо )
Вы меня немного не поняли, речь идет не о cisco, речь идет об linux-е с пакетом quagga. C cisco-ой как раз все понятно, используем bgp dmzlink-bw и балансируем с учетом скорости на интерфейсах.
А вот в linux-е я ни где не встречал что бы использовалась такая маршрутизация, точнее она есть но используются совместно с нат что имеет скорее образовательный интерес чем практическое применение. Поскольку не работает https, ftp и многое другое.
Так вот мой вопрос, можно ли использовать маршрутизацию такого вида совместно с BGP. Маршрут прописывается руками статически.
#ip route add 1.1.1.1 scope global nexthop via $GW1 weight 1 nexthop via $GW2 weight 3
PS Коллеги может у кого то есть возможность проверить это на реальной сети?
Собственно, в статье это прямым текстом не написано, но есть на эту тему задача для самостоятельного изучения.
Использовать это вполне можно, если поддерживает IOS. Ну и есть вопрос, как с этим дела обстоят у других вендоров.
Ограничение — длина AS-Path должна быть одинаковой для разных линков.
Вероятнее всего, да. Для локального обмена трафиком с каким-то другим провайдером.
Спасибо. Еще вопрос… Работаю в маленьком российском проавйдере, и в кач-ве бордера у нас используется микротик. Зашел на него, и нашел там интересный факт-BGP сессий две. Причем одна видимо Full View(503098 записей), и называется она inet_bgp, а вторая p2p_bgp и имеет 8200 записей. Админ мне расшифровал p2p как peer 2 peer(я думал что это point 2 point).Вопрос: что это за сессия? она объединяет пиринг партнеров, как я понимаю?
Default Route — он и есть Default Route. Мы не знаем ничего о том, что находится за этим хопом, знаем только то, что отправлять надо туда и всё. Дойдёт, не дойдёт — полагаемся чисто на вышестоящих операторов.
Плюс в том, что вы анонсируете свои сети и, что немаловажно, можете делать это нескольким операторам, обеспечивая балансировку и резервирование.
Боюсь оказаться неправым — нет возможности сейчас проверить, но, возможно, например, во втором случае не разрывается BGP-сессия и он не начинает сразу же перестраивать таблицу маршрутизации. Нужно собрать лабу, посмотреть.
Нужна конкретика. Проверяйте все таблицы маршрутизации, трассировки, смотрите на каком узле начинаются проблемы.
Очень приятно.
Сегодня опубликован выпуск №9, посвящённый мультикасту.Приглашаю к чтению и дискуссии. 🙂
Конечно, не закончился. Ещё как минимум 5 выпусков.
И, кстати, уже вышел вот такой.
В принципе, это не имеет значения в данному случае. Суть в том, что есть статический маршрут, который редистрибьютится в BGP.
Всё зависит от конкретной задачи, дизайна вашей сети. Если вы крупный провайдер, то у вас уже есть к этом требования. Если сеть предприятия, то выбираете, как вам удобнее. Исходящий трафик вполне можно рулить Local Preference — удобно, гибко и именно то, что вы хотите.
Я это понял, спасибо. Но нет ли, так сказать, какого-то best practice?
В статье я описал практически все возможные способы влияния и на входящий и на исходящий трафик.
Оперируя Local Preference, Weight, MED и AS-path prepend можно добиться того, чего желаете.
А как можно сделать чтобы весь трафик шел через один провайдер, но в случае его падения переходил на резерв?
Совершенно верно.
Еще глупый вопрос. Через параметр Weight я указал через какой провайдер ходить. Но это будет только для исходящего трафика? То есть на входящий трафик это не повлияет?
В принципе, Local Preference — то же самое, что и Weight. В примерах в статье тут и на xgu есть инструкция по применению на практике.
Если честно, то не сильно въехал=) Нашел xgu.ru/wiki/BGP_local_preference
http://www.cisco.com/en/US/tech/tk365/technologies_configuration_example09186a00800945bf.shtml#diag4
Но не понял, как сделать именно через local-preference. Пооробовал сделать через weight. Улучшил маршруты от одного провайдера и он стал основным…
Да, конечно, так или иначе BGP выбирает лучший маршрут (или балансирует его). Просто Local Preference позволяет определить, какой именно провайдер будет предпочтительным.
Я вот на похожей топологии поднял BGP с двумя соседями, получил от них только дефолт. Больше ничего не настраивал. Когда роняю один линк, то все равно доступность к удаленной сети есть. Трафик пошел через другой провайдер… Так и должно быть в базовой настройке?
Прошу прощения, я был не в себе. Неправильно понял ваш вопрос.
На маршруты от провайдеров вы можете применить Local-Preference. Использоваться будет только более приоритетный. Как только он упадёт, всё перейдёт на резервного. Тут нет никаких проблем.
Да я понимаю. Но я так понял, что есть несколько способов? Если я просто получаю от провайдеров дефолт и укажу, что что вес маршрутов от одного провайдера будет больше? Будет работать такая схема?
Достаточно сложно ответить на ваш вопрос одним комментарием. Сделать это можно, но путь нетривиальный — не просто ввести одну команду.
С трудом себе это представляю. Не слышал ни о чём подобном.
Ну вот… а я так надеялся… Какой был бы подарок на ДР =) Придется самому все компоновать =)
Мы планируем собрать все наши выпуски в единую книгу в будущем, но пока, к сожалению, такого нет.
Спасибо, Парень из стали!
Да, уже подумал об этом. Пожалуй, в следующий раз сделаю шрифт больше размером.
Спасибо за замечание. Всё верно. Сейчас поправлю статью.
Ну это не совсем так. Во-первых, показания не такие точные будут, как с респондером. Во-вторых, в статье немного топорно, упрощенно используется показатель джиттера. На самом деле, характеристики, влияющие на качество канала, или пригодности этого канала для voip (это джиттер, потери, задержка), объединяются в некую общую оценку (MOS или ICPIF), по которой уже судят. Использование icmp-jitter не дает такой возможности.
Спасибо большое. Долго пытался вспомнить в каких случаях такое может быть ещё и никак не мог. Добавлю в статью.