





Сети для самых маленьких. Часть шестая. Динамическая маршрутизация
 38
38

 565704
565704
 183
183



Сеть “Лифт ми Ап” вместе со своим штатом разрастается вдоль и поперёк. Обслуживание ИТ-инфраструктуры вынесли в отдельную специально созданную организацию “Линк ми Ап”.
Буквально на днях были куплены ещё четыре филиала в различных городах и инвесторы открыли для себя новые измерения движения лифтов. А сеть выросла с четырёх маршрутизаторов сразу до десяти. При этом количество подсетей теперь увеличилось с 9 до 20, не считая линков точка-точка между маршрутизаторами. И тут во весь рост встаёт вопрос управления всем этим хозяйством. Согласитесь, добавлять на каждом из узлов маршруты во все сети вручную — мало удовольствия.
Ситуация усложняется тем, что сеть в Калининграде уже имеет свою адресацию, и на ней запущен протокол динамической маршрутизации EIGRP.
Итак, сегодня:
Содержание выпуска
- Теория протоколов динамической маршрутизации
- OSPF
- EIGRP
- Настройка передачи маршрутов между различными протоколами
- Маршрут по умолчанию
- Полезные команды для траблшутинга
- Материалы выпуска
- Полезные ссылки

Уровень сложности будет разный. Ко всем задачам будут ответы. В некоторых вам понадобится подумать, в других почитать документацию, в третьих разобраться в топологии и, может, даже смотреть отладочную информацию. Если задача нереализуема в РТ, мы сделаем специальную пометку об этом.
Теория протоколов динамической маршрутизации
Для начала разберемся с понятием “динамическая маршрутизация”. До сего момента мы использовали так называемую статическую маршрутизацию, то есть прописывали руками таблицу маршрутизации на каждом роутере. Использование протоколов маршрутизации позволяет нам избежать этого нудного однообразного процесса и ошибок, связанных с человеческим фактором. Как понятно из названия, эти протоколы призваны строить таблицы маршрутизации сами, автоматически, исходя из текущей конфигурации сети. В общем, вещь нужная, особенно когда ваша сеть это не 3 роутера, а 30, например.
Помимо удобства есть и другие аспекты. Например, отказоустойчивость. Имея сеть со статической маршрутизацией, вам крайне сложно будет организовать резервные каналы — некому отслеживать доступность того или иного сегмента.

Например, если в такой сети разорвать линк между R2 и R3, то пакеты с R1 будут уходить по прежнему на R2, где будут уничтожены, потому что их некуда отправить.

Протоколы динамической маршрутизации в течение нескольких секунд (а то и миллисекунд) узнают о проблемах на сети и перестраивают свои таблицы маршрутизации, и в вышеописанном случае пакеты будут отправляться уже по актуальному маршруту

Ещё один важный момент — балансировка трафика. Протоколы динамической маршрутизации практически из коробки поддерживают эту фичу и вам не нужно добавлять избыточные маршруты вручную, высчитывая их.
Ну и внедрение динамической маршрутизации сильно облегчает масштабирование сети. Когда вы добавляете новый элемент в сеть или подсеть на существующем маршрутизаторе, вам нужно выполнить всего несколько действий, чтобы всё заработало и вероятность ошибки минимальна, при этом информация об изменениях мгновенно расходится по всем устройствам. Ровно то же самое можно сказать и о глобальных изменениях топологии.
Все протоколы маршрутизации можно разделить на две большие группы: внешние (EGP — Exterior Gateway Protocol) и внутренние (IGP — Interior Gateway Protocol). Чтобы объяснить различия между ними, нам потребуется термин “автономная система”. В общем смысле, автономной системой (доменом маршрутизации) называется группа роутеров, находящихся под общим управлением. В случае нашей обновлённой сети AS будет такой:

Так вот, протоколы внутренней маршрутизации используются внутри автономной системы, а внешние — для соединения автономных систем между собой. В свою очередь, внутренние протоколы маршрутизации подразделяются на Distance-Vector (RIP, EIGRP) и Link State (OSPF, IS-IS). В этой статье мы не будем пинать трупы затрагивать протоколы RIP и IGRP в силу их почтенного возраста, а так же IS-IS в силу его отсутствия в ПТ.
Коренные различия между этими двумя видами состоят в следующем:
- Типе информации, которой обмениваются роутеры: таблицы маршрутизации у Distance-Vector и таблицы топологии у Link State,
- Процессе выбора лучшего маршрута,
- Количестве информации о сети, которое “держит в голове” каждый роутер: Distance-Vector знает только своих соседей, Link State имеет представление обо всей сети.
Как мы видим, количество протоколов маршрутизации невелико, но все же не один-два. А что будет, если на роутере запустить несколько протоколов одновременно? Может оказаться, что у каждого протокола будет свое мнение о том, как лучше добраться до определенной сети. А если у нас еще и статические маршруты настроены? Кому роутер отдаст предпочтение и чей маршрут добавит в таблицу маршрутизации? Ответ на этот вопрос связан с новым термином: административная дистанция (на нащ вкус, довольно посредственная калька с английского Аdministrative distance, но лучше выдумать не смогли). Аdministrative distance это целое число от 0 до 255, выражающее “меру доверия” роутера к данному маршруту. Чем меньше AD, тем больше доверия.
Вот табличка такого доверия с точки зрения Cisco:
| Протокол | Административная дистанция |
|---|---|
| Connected interface | 0 |
| Static route | 1 |
| Enhanced Interior Gateway Routing Protocol (EIGRP) summary route | 5 |
| External Border Gateway Protocol (BGP) | 20 |
| Internal EIGRP | 90 |
| IGRP | 100 |
| OSPF | 110 |
| Intermediate System-to-Intermediate System (IS-IS) | 115 |
| Routing Information Protocol (RIP) | 120 |
| Exterior Gateway Protocol (EGP) | 140 |
| On Demand Routing (ODR) | 160 |
| External EIGRP | 170 |
| Internal BGP | 200 |
| Unknown | 255 |
В сегодняшней статье мы разберём OSPF и EIGRP. Первый вам будет встречаться везде и постоянно, а второй очень хорош в сетях, где присутствует только оборудование Cisco. У каждого из них есть свои достоинства и недостатки. Можно сказать, что EIGRP выигрывает перед OSPF, но все плюсы нивелируются его проприетарностью. EIGRP — фирменный протокол Cisco и больше никто его не поддерживает.
На самом деле у EIGRP много недостатков, но об этом не особо распространяются в популярных статьях.
Итак, приступим.
OSPF
Статей и видео о том, как настроить OSPF горы. Гораздо меньше описаний принципов работы. Вообще, тут такое дело, что OSPF можно просто настроить согласно мануалам, даже не зная про алгоритмы SPF и непонятные LSA. И всё будет работать и даже, скорее всего, прекрасно работать — на то он и рассчитан. То есть тут не как с вланами, где приходилось знать теорию вплоть до формата заголовка.
Но инженера от эникейщика отличает то, что он понимает, почему его сеть функционирует так, а не иначе, и не хуже самогo OSPF знает, какой маршрут будет выбран протоколом. В рамках статьи, которая уже на этот момент составляет 8 000 символов, мы не сможем погрузиться в глубины теории, но рассмотрим принципиальные моменты. Очень просто и понятно, кстати, написано про OSPF на xgu.ru или в английской википедии.
Итак, OSPFv2 работает поверх IP, а конкретно, он заточен только под IPv4 (OSPFv3 не зависит от протоколов 3-го уровня и потому может работать с IPv6).
Рассмотрим его работу на примере вот такой упрощённой сети:

Для начала надо сказать, что для того, чтобы между маршрутизаторами завязалась дружба (отношения смежности) должны выполниться следующие условия:
- В OSPF должны быть настроены одинаковые Hello Interval на тех маршрутизаторах, что подключены друг к другу. По умолчанию это 10 секунд в Broadcast сетях, типа Ethernet. Это своего рода KeepAlive сообщения. То есть каждые 10 секунд каждый маршрутизатор отправляет Hello пакет своему соседу, чтобы сказать: “Хей, я жив”,
- Одинаковыми должны быть и Dead Interval на них. Обычно это 4 интервала Hello — 40 секунд. Если в течение этого времени от соседа не получено Hello, то он считается недоступным и начинается
ПАНИКАпроцесс перестроения локальной базы данных и рассылка обновлений всем соседям, - Интерфейсы, подключенные друг к другу, должны быть в одной подсети,
- OSPF позволяет снизить нагрузку на CPU маршрутизаторов, разделив Автономную Систему на зоны. Так вот номера зон тоже должны совпадать,
- У каждого маршрутизатора, участвующего в процессе OSPF есть свой уникальный индентификатор — Router ID. Если вы о нём не позаботитесь, то маршрутизатор выберет его автоматически на основе информации о подключенных интерфейсах (выбирается высший адрес из интерфейсов, активных на момент запуска процесса OSPF). Но опять же у хорошего инженера всё под контролем, поэтому обычно создаётся Loopback интерфейс, которому присваивается адрес с маской /32 и именно он назначается Router ID. Это бывает удобно при обслуживании и траблшутинге.
- Должен совпадать размер MTU
Далее пьеса в девяти частях.
- Штиль. Состояние OSPF — DOWN
В это короткое мгновение в сети ничего не происходит — все молчат.

- Поднимается ветер: маршрутизатор рассылает Hello-пакеты на мультикастный адрес 224.0.0.5 со всех интерфейсов, где запущен OSPF. TTL таких сообщений равен одному, поэтому их получат только маршрутизаторы, находящиеся в том же сегменте сети. R1 переходит в состояние INIT.

В пакеты вкладывается следующая информация:- Router ID
- Hello Interval
- Dead Interval
- Neighbors
- Subnet mask
- Area ID
- Router Priority
- Адреса DR и BDR маршрутизаторов
- Пароль аутентификации
Нас интересуют пока первые четыре или точнее вообще только Router ID и Neighbors.
Сообщение Hello от маршрутизатора R1 несёт в себе его Router ID и не содержит Neighbors, потому что у него их пока нет.
После получения этого мультикастного сообщения маршрутизатор R2 добавляет R1 в свою таблицу соседей (если совпали все необходимые параметры).

И отправляет на R1 уже юникастом новое сообщение Hello, где содержится Router ID этого маршрутизатора, а в списке Neigbors перечислены все его соседи. В числе прочих соседей в этом списке есть Router ID R1, то есть R2 уже считает его соседом.
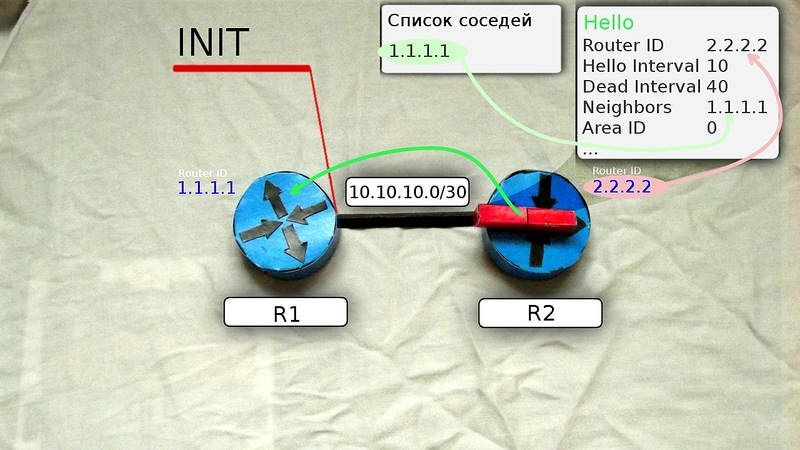
- Дружба. Когда R1 получает это сообщение Hello от R2, он пролистывает список соседей и находит в нём свой собственный Router ID, он добавляет R2 в свой список соседей.

Теперь R1 и R2 друг у друга во взаимных соседях — это означает, что между ними установлены отношения смежности и маршрутизатор R1 переходит в состояние TWO WAY.

Далее происходит выбор DR и BDR, но мы не будем на этом останавливаться, хоть это и довольно важные вещи.
- Затишье перед бурей. Далее все переходят в состояние EXSTART. Здесь все соседи решают между собой, кто босс. Им становится маршрутизатор с наибольшим Router ID — R2.
- Когда выбран Батька, соседи переходят в состояние Exchange и обмениваются DBD-сообщениями (или DD) — Data Base Description, которые содержат описание LSDB (Link State Data Base), мол, я знаю про вот такие подсети.
Тут надо пояснить, что такое LSDB. Если перевести на русский дословно: база данных о состоянии линков. В изначальном состоянии маршрутизатор знает только о тех линках (интерфейсах), на которых запущен процесс OSPF. По ходу пьесы, каждый маршрутизатор собирает всю информацию о сети и составляет топологию. Именно она и будет являться LSDB, которая должна быть одинакова на всех членах зоны.
Первым отсылает свою DBD маршрутизатор, выбранный главным на данном интерфейсе — 2.2.2.2. Следом за ним то же делает и 1.1.1.1.
- Получив сообщение, маршрутизаторы R1 и R2 отправляют подтверждение о приёме DBD (LSAck), а затем сравнивают новую информацию с той, что содержится у них в LSDB и, если есть отличия, посылают LSR (Link State Request) друг другу, тем самым переходя в новое состояние LOADING. В LSR они говорят — “Я про вот эту сеть ничего не знаю. Расскажи мне подробнее”.

- R2, получив LSR от R1, высылает LSU (Link State Update), которые содержат в себе LSA (Link State Advertisement) c детальной информацией о нужных подсетях.

И вот, как только R1 получит последнюю порцию данных о всех подсетях и сформирует свою LSDB, он переходит в своё конечное состояние FULL STATE.

К тому моменту, как все маршрутизаторы зоны придут к состоянию Full State на всех на них должна быть полностью одинаковая LSDB — они же одну и ту же сеть изучали. То есть фактически это означает, что маршрутизатор знает всю вашу сеть, что, как и куда подключено.
Авторы осознают, что понять и запомнить все эти аббревиатуры и правила довольно сложно, но прочитав это 5 -7 раз в разных местах с некоторой периодичностью, можно будет составить представление о том, как OSPF работает.
- Итак, сейчас у нас все маршрутизаторы знают всё о сети, но это знание пока не помогает в маршрутизации.
- Следующим шагом OSPF, используя алгоритм Дейкстры (или его ещё называют SPF — Shortest Path First), вычисляет кратчайший маршрут до каждого маршрутизатора в зоне — он ведь знает всю топологию. В этом ему помогают метрики. Чем она ниже, тем маршрут лучше. Метрика — это стоимость движения по маршруту.

Например, в такой сети из R1 в R3 можно добраться напрямую или через R2.
Естественно первый вариант будет стоить меньше. Но это при условии, что у вас везде одинаковый тип интерфейсов. А если, например, между R1 и R3 у вас модемное соединение в 56к или крайне нестабильный GPRS линк? Тогда у них будет очень высокая стоимость и OSPF предпочтёт более длинный, но быстрый путь.
Найденный путь потом добавляется в таблицу маршрутизации.
Теперь каждые 10 секунд каждый маршрутизатор будет отправлять Hello-пакеты, а каждые 30 минут рассылаются LSA — это типа данные уже считаются устаревшими, надо бы обновить, даже если изменений не было.
В идеальном мире на этом бы и установилось равновесие. Но мы живём в мире жестоком и равнодушном, где инженер — это итшник, а то и компьютерщик вообще, а лифты научились ездить вниз всего три выпуска назад. И в этом будничном мире кипят страсти: рвут оптику, вырубают питание, мыши перегрызают ножки процессоров (или это не в этом мире?) — иными словами, топология непрестанно меняется. И чем больше сеть, тем чаще и глобальнее изменения.
Разумеется, было бы несколько странно ждать 40 секунд (Dead Interval) и только потом начинать перестраивать таблицу. Это было бы простительно ещё RIP’у, но не протоколу, который используется в огромном количестве современных сетей. Итак, как только падает какой-либо из линков (или несколько), маршрутизатор изменяет свою LSDB и генерирует LSU, присваивая ей номер больше, чем он был прежде (у каждой LSDB есть номер, который берётся из последнего полученного LSA).
Это LSU сообщение рассылается на мультикастовый адрес 224.0.0.5. Маршрутизаторы получившие его, проверяют номер LSA, содержащихся в LSU.
- Если номер больше, чем номер текущей LSA маршрутизатора — LSDB меняется. (Версия LSDB старая, информация новая),
- Если номер такой же, ничего не происходит. Этот маршрутизатор уже получил данный LSA по какому-то другому пути,
- Если номер полученного LSA меньше локальной LSDB, это означает, что у маршрутизатора уже более актуальная информация, и он посылает новый LSA (на основе своей LSDB) отправителю прежнего.
После произведённых (или непроизведённых) действий соседу, от которого пришёл LSU пересылаются LSAck (мол, «посылку получили — всё в порядке»), а другим соседям отправляется изначальный LSU без изменений. На данном маршрутизаторе снова запускается алгоритм SPF и, при необходимости, обновляется таблица маршрутизации.
В общем, всё это происходит в целях поддержания актуальности информации на всех устройствах — LSDB должна быть одинаковой у всех.
Тут надо оговориться, что маршрутизатор замечает изменения только при прямом подключении к своему соседу. Если между ними будет, например, коммутатор, то устройство не обнаружит падения физического интерфейса и ничего не будет делать. Для таких ситуаций есть два решения.
1) Настроить таймеры. Для OSPF их можно уменьшить до уровня миллисекунд.
2) Использовать очень крутой протокол BFD (Bidirectional Forwarding Detection). Он позволяет отслеживать состояние линков также на миллисекундном уровне. В конфигурации BFD связывается с другими протоколами и позволяет очень быстро сообщить кому надо, что есть проблемы на сети. Конкретно с BFD мы будем разбираться в другой части.
Как вы заметили, на все сообщения есть подтверждения: либо это LSAck, либо ответ Hello на Hello. Это плата за отказ от TCP — как-то ведь надо убеждаться в успешной доставке.
Всего существует 7 типов LSA, которые тесно завязаны на зоны, коих тоже 5 штук. Маршрутизаторы тоже бывают четырёх типов. А так же есть понятия Designated Router (DR) и Backup DR (BDR), ABR и ASBR. Есть формулы расчёт метрик и прочее, прочее. Оставляем это на самостоятельное изучение.
Практика OSPF
Помните, как мы мучились, настраивая маршрутизацию в прошлый раз: на каждом устройстве до каждой сети и не дай бог что-нибудь забыть. Теперь это в прошлом — да здравствуют IGP! Не будем терять время, объясняя отдельно команды, а сразу окунёмся в удивительный мир конфигурации.
Такс, имеет место сейчас следующая логическая схема:

Пока нас интересует вот это большое Сибирское кольцо через Красноярск, Хабаровск и Владивосток. Здесь и на нашей уже построенной сети мы запустим OSPF. Там, где прежде была статика, нам придётся от неё отказаться и плавно перейти на динамические протоколы.
Предположим, что Красноярск у нас так же подключен через «Балаган телеком», как и предыдущие точки, а далее через разных провайдеров нам организованы линки к другим городам. Кольцо замыкается в Москве через провайдера “Филькин сертификат”. Предположим, что везде между городами у нас куплен L2-VPN и IP-трафик ходит прозрачно.
Что внедрение IGP даст конкретно нашей сети?
- Простоту конфигурации, разумеется. На каждом узле нужно знать только локальные сети, вопросом их распространения озадачится OSPF.
- Избыточные линки, которые обеспечат нам резервирование каналов связи. Если, например, бомжи срежут оптику между Москвой и Красноярском, ни один филиал не останется без связи: весь трафик пойдёт через Владивосток

- Автоматическое обнаружение проблем, перестроение топологии и изменение таблицы маршрутизации. Именно это обеспечивает возможность выполнения пункта 2.
- Нет опасности создать петлю маршрутизации, когда пакет у нас будет метаться между двумя узлами, пока TTL не истечёт. При статической настройке такая ситуация более, чем возможна.
- Удобство расширения. Представьте, что вам нужно добавить новый филиал, например в Томске и подключать его будете через Кемерово. Тогда статические маршруты вам придётся прописывать в Москве, Кемерово и в самом Томске. При использовании динамики вы настраиваете только новый маршрутизатор… и всё.
IP-план подсетей филиалов и линков Point-to-Point мы уже подготовили. Предположим, что и все начальные настройки тоже выполнили на всех узлах:
- hostname
- параметры безопасности (пароли на телнет, ssh)
- IP-адреса линковых интерфейсов
- IP адреса подсетей LAN
- IP-адреса Loopback-интерфейсов.
Мы тут вводим новое понятие Loopback-интерфейса. Он будет сконфигурирован на каждом маршрутизаторе. Для этого выделена специальная подсеть 172.16.255.0/24. Нужно оно нам сейчас для OSPF, а в будущем может понадобиться для BGP, MPLS.
Положа руку на сердце, сам долгое время не понимал значения этих интерфейсов. Вообще говоря, это виртуальный интерфейс, состояние которого всегда UP, независимо от состояния физических интерфейсов (если только на нём самом shutdown не выполнили). Попытаемся объяснить одну из его ролей:
Вот, к примеру, есть у вас сервер мониторинга Nagios. В нём вы завели для наблюдения маршрутизатор R1 и для связи с ним использовали адрес интерфейса FE0/0 — 10.1.0.1.
На первый взгляд все прекрасно — всё работает. Но предположим теперь, что этот кабель порвали.
Благодаря динамической маршрутизации, связь до роутера А не нарушится, и он будет доступен через FE0/1. А в Nagios’е у вас будет авария, всё будет красное, повалятся смс и почта. При падении линка, IP-адрес этого интерфейса (10.1.0.1) становится недоступен.
А вот если вы настроите в Nagios’е адрес Loopback-интерфейса, то тем или иным путём он всегда будет доступен, опять же благодаря динамической маршрутизации.
В качестве маски IP-адреса Loopback-интерфейса практически всегда выбирается /32, то есть 11111111.11111111.11111111.1111111 — один единственный адрес — а больше и не надо.


Поскольку все приготовления уже закончились, перед нами стоит очень простая задача: пройтись по всем маршрутизаторам и активировать процесс OSPF.
- Первое, что нам нужно сделать — запустить процесс OSPF маршрутизаторе:
msk-arbat-gw1(config)# router OSPF 1Первым словом указываем, что запускаем протокол динамической маршрутизации, далее указываем какой именно и в последнюю очередь номер процесса (теоретически их может быть несколько на одном роутере).
Сразу после этого автоматически назначается router ID. По умолчанию это наибольший адрес Loopbaсk-интерфейсов.
- Не оставляем это дело на самотёк. Главное правило: Router ID обязан быть уникальным. Нет, вы, конечно, можете их сделать и одинаковыми, но в этом случае у вас начнутся странности.
Одна из моих заявок была такой: на оборудовании заканчиваются метки LDP. Из 8 с гаком тысяч осталась только одна свободная. Никакие новые VPN не создавались и не работали. Разбирались, разбирались и в итоге увидели что процесс OSPF создаёт и удаляет тысячи записей в минуту в таблице маршрутизации. Топология постоянно перестраивается и на каждое такое перестроение выделяются новые метки LDP, после чего не освобождаются. А всё дело в случайно настроенных одинаковых Router ID.
Настраивать его можно, в принципе, как угодно, можно даже не настраивать, маршрутизатор назначит его сам, но для порядку мы это сделаем — в будущем обслуживать будет проще. Назначаем его в соответствии с адресом Loopback-интерфейса.
msk-arbat-gw1(config-router)#router-id 172.16.255.1 - Теперь мы объявляем, какие сети мы будем анонсировать (передавать соседям OSPF). Обратите внимание, что в этой команде используется wildcard-маска, как в ACL
msk-arbat-gw1(config-router)#network 172.16.0.0 0.0.255.255 area 0
Тут остановимся подробно. Командой network мы задаём не ту сеть, что будет вещать наш маршрутизатор, мы определяем интерфейсы, участвующие в процессе. Все интерфейсы маршрутизатора, IP адреса которых попадают в настроенный диапазон 172.16.0.0 0.0.255.255 (172.16.0.0-172.16.255.255), включатся в процесс. Это означает следующее:
а) с данных интерфейсов будут рассылаться Hello-сообщения, через них будут устанавливаться отношения соседства и отправляться обновления о топологии сети.
б) OSPF изучает подсети данных интерфейсов и именно их будет анонсировать и следить за их состоянием. То есть не 172.16.0.0 0.0.255.255, как мы настроили, а те, что удовлетворяют этому диапазону

В нашем случае не имеет значения как мы настроим:
msk-arbat-gw1(config-router)#network 172.16.0.0 0.0.255.255 area 0
или
msk-arbat-gw1(config-router)#network 172.16.0.0 0.0.15.255 area 0
или
msk-arbat-gw1(config-router)#network 172.16.0.0 0.0.255.255 area 0
msk-arbat-gw1(config-router)#network 172.16.1.0 0.0.255.255 area 0
msk-arbat-gw1(config-router)#network 172.16.2.0 0.0.255.255 area 0
…..
msk-arbat-gw1(config-router)#network 172.16.15.0 0.0.255.255 area 0
Все эти команды сработают одинаково в нашем случае.
Поскольку у нас все локальные сети имеют адреса из сети 172.16.0.0/16, то мы будем использовать наиболее общую запись. При этом туда, разумеется, не попадёт внешний интерфейс в интернет FastEthernet0/1.6, потому что его адрес — 198.51.100.2 — не из этого диапазона.
При такой настройке любой новый интерфейс, на котором вы укажете адрес из диапазона 172.16.0.0 — 172.16.255.255, автоматически становится участником процесса OSPF. Плохо это или хорошо, зависит от ваших желаний.
area 0 означает принадлежность данных подсетей зоне с номером ноль (в наших примерах только такая и будет).
Area 0 это не простая зона — это так называемая Backbone-area. Это означает, что она объединяет все остальные зоны, т.е. пакет, идущий от любой ненулевой зоны в любую ненулевую, обязан проходить через area 0
Как только вы задали команду network с правильных интерфейсов слетают слова приветствия, но отвечать на них пока некому — соседей нет:
msk-arbat-gw1#sh ip OSPF neighbor
msk-arbat-gw1#
Теперь пропишем настройки OSPF в Кемерово (router ID=IP адрес Loopback интерфейса, взятый из IP-плана):
kmr-gorka-gw1(config)#router OSPF 1
kmr-gorka-gw1(config-router)#router-id 172.16.255.48
kmr-gorka-gw1(config-router)#network 172.16.0.0 0.0.255.255 area 0
И сразу после этого вы видите в консоли сообщение
02:27:33: %OSPF-5-ADJCHG: Process 1, Nbr 172.16.255.1 on FastEthernet0/0.5 from LOADING to FULL, Loading Done
Такое же показывает и маршрутизатор в Москве:
02:27:33: %OSPF-5-ADJCHG: Process 1, Nbr 172.16.255.48 on FastEthernet0/1.5 from LOADING to FULL, Loading Done.
Здесь вы можете видеть, что были успешно установлены отношения смежности и произошёл обмен LSA. Каждый маршрутизатор построил свою LSDB.
Подробная информация по соседу:
msk-arbat-gw1#sh ip OSPF neighbor detail
Neighbor 172.16.255.48, interface address 172.16.2.18
In the area 0 via interface FastEthernet0/1.5
Neighbor priority is 1, State is FULL, 4 state changes
DR is 172.16.2.17 BDR is 172.16.2.18
Options is 0x00
Dead timer due in 00:00:38
Neighbor is up for 00:02:51
Index 1/1, retransmission queue length 0, number of retransmission 0
First 0x0(0)/0x0(0) Next 0x0(0)/0x0(0)
Last retransmission scan length is 0, maximum is 0
Last retransmission scan time is 0 msec, maximum is 0 msec
Тут вся ключевая информация о состоянии соседа:
Его router-id (172.16.255.48), который суть loopback, адрес интерфейса удалённой стороны, через который установлено соседство (172.16.2.18), тип и номер физического интерфейса (FastEthernet0/1.5), текущий статус (FULL) и Dead timer. Последний не доходит до нуля, если вы за ним понаблюдаете. Его значение уменьшается, уменьшается, а потом Оп! и снова 40. Это потому что каждые 10 секунд маршрутизаторы получают сообщения Hello и обсороколяют обнуляют Dead-интервал.
Командой show ip route мы можем посмотреть, как изменилась таблица маршрутизации:
msk-arbat-gw1#show ip route
Codes: C — connected, S — static, I — IGRP, R — RIP, M — mobile, B — BGP
D — EIGRP, EX — EIGRP external, O — OSPF, IA — OSPF inter area
N1 — OSPF NSSA external type 1, N2 — OSPF NSSA external type 2
E1 — OSPF external type 1, E2 — OSPF external type 2, E — EGP
i — IS-IS, L1 — IS-IS level-1, L2 — IS-IS level-2, ia — IS-IS inter area
* — candidate default, U — per-user static route, o — ODR
P — periodic downloaded static route
Gateway of last resort is 198.51.100.1 to network 0.0.0.0
172.16.0.0/16 is variably subnetted, 17 subnets, 5 masks
C 172.16.0.0/24 is directly connected, FastEthernet0/0.3
C 172.16.1.0/24 is directly connected, FastEthernet0/0.2
C 172.16.2.0/30 is directly connected, FastEthernet0/1.4
S 172.16.2.4/30 [1/0] via 172.16.2.2
C 172.16.2.16/30 is directly connected, FastEthernet0/1.5
C 172.16.2.32/30 is directly connected, FastEthernet0/1.7
C 172.16.2.128/30 is directly connected, FastEthernet0/1.8
C 172.16.2.196/30 is directly connected, FastEthernet1/0.911
C 172.16.3.0/24 is directly connected, FastEthernet0/0.101
C 172.16.4.0/24 is directly connected, FastEthernet0/0.102
C 172.16.5.0/24 is directly connected, FastEthernet0/0.103
C 172.16.6.0/24 is directly connected, FastEthernet0/0.104
S 172.16.16.0/21 [1/0] via 172.16.2.2
S 172.16.24.0/22 [1/0] via 172.16.2.18
O 172.16.24.0/24 [110/2] via 172.16.2.18, 00:13:03, FastEthernet0/1.5
C 172.16.255.1/32 is directly connected, Loopback0
O 172.16.255.48/32 [110/2] via 172.16.2.18, 00:13:03, FastEthernet0/1.5
198.51.100.0/28 is subnetted, 1 subnets
C 198.51.100.0 is directly connected, FastEthernet0/1.6
S* 0.0.0.0/0 [1/0] via 198.51.100.1
Кроме известных ранее сетей (C — directly connected и S — Static) у нас появились два новых маршрута с пометкой O (OSPF). Тут всё должно быть понятно, но наблюдательный читатель спросит: “почему в таблице маршрутизации присутствуют два маршрута в сеть 172.16.24.0. Почему не останется более предпочтительный статический?” и будет прав. Вообще говоря, в таблицу маршрутизации попадает только лучший маршрут до сети — по умолчанию один. Но обратите внимание, что статический Bidirectional Forwarding Detectionмаршрут идёт до подсети 172.16.24.0/22, а полученный от OSPF до 172.16.24.0/24. Это разные подсети, поэтому обеим им нашлось место до солнцем. Дело в том, что OSPF понятия не имеет чего вы там напланировали и какой диапазон выделили — он оперирует реальными данными, то есть IP-адресом и маской:
interface FastEthernet0/0.2
ip address 172.16.24.1 255.255.255.0
Что у нас творится в Кемерово:
kmr-gorka-gw1#sh ip route
Gateway of last resort is 172.16.2.17 to network 0.0.0.0
172.16.0.0/16 is variably subnetted, 14 subnets, 3 masks
O 172.16.0.0/24 [110/2] via 172.16.2.17, 00:32:42, FastEthernet0/0.5
O 172.16.1.0/24 [110/2] via 172.16.2.17, 00:32:42, FastEthernet0/0.5
O 172.16.2.0/30 [110/2] via 172.16.2.17, 00:32:42, FastEthernet0/0.5
C 172.16.2.16/30 is directly connected, FastEthernet0/0.5
O 172.16.2.32/30 [110/2] via 172.16.2.17, 00:32:42, FastEthernet0/0.5
O 172.16.2.128/30 [110/2] via 172.16.2.17, 00:32:42, FastEthernet0/0.5
O 172.16.2.196/30 [110/2] via 172.16.2.17, 00:32:42, FastEthernet0/0.5
O 172.16.3.0/24 [110/2] via 172.16.2.17, 00:32:42, FastEthernet0/0.5
O 172.16.4.0/24 [110/2] via 172.16.2.17, 00:32:42, FastEthernet0/0.5
O 172.16.5.0/24 [110/2] via 172.16.2.17, 00:32:42, FastEthernet0/0.5
O 172.16.6.0/24 [110/2] via 172.16.2.17, 00:32:42, FastEthernet0/0.5
C 172.16.24.0/24 is directly connected, FastEthernet0/0.2
O 172.16.255.1/32 [110/2] via 172.16.2.17, 00:32:42, FastEthernet0/0.5
C 172.16.255.48/32 is directly connected, Loopback0
S* 0.0.0.0/0 [1/0] via 172.16.2.17
Как видим, помимо настроенного прежде маршрута по умолчанию, тут появились все подсети из Москвы.
Обратите внимание на цифры в квадратных скобках:
S* 0.0.0.0/0 [1/0]
O 172.16.6.0/24 [110/2]
Первая цифра — это административная дистанция, которая у OSPF значительно больше, чем у статики и, соответственно, приоритет ниже.
На самом деле до подсети 172.16.24.0/24 трафик уже пошёл по маршруту предоставленному OSPF, потому что у него более узкая маска (24 против 22).
Но попробуем удалить статические маршруты и посмотрим, что получится.
Совершенно предсказуемо всё работает:
msk-arbat-gw1#ping 172.16.24.1
Type escape sequence to abort.
Sending 5, 100-byte ICMP Echos to 172.16.24.1, timeout is 2 seconds:
!!!!!
Success rate is 100 percent (5/5), round-trip min/avg/max = 8/10/15 ms
И это прекрасно. Настроим OSPF в Питере:
spb-vsl-gw1(config)#router OSPF 1
spb-vsl-gw1(config-router)#router-id 172.16.255.32
spb-vsl-gw1(config-router)#network 172.16.0.0 0.0.255.255 area 0
Настройки, как видите, везде предельно простые. При этом замечу, что номер процесса OSFP на разных маршрутизаторах не обязательно должен быть одинаковым, но лучше, если это будет так.
На msk-arbat-gw1 у нас теперь два соседа
msk-arbat-gw1#sh ip OSPF neighbor
Neighbor ID Pri State Dead Time Address Interface
172.16.255.32 1 FULL/DROTHER 00:00:39 172.16.2.2 FastEthernet0/1.4
172.16.255.48 1 FULL/DROTHER 00:00:31 172.16.2.18 FastEthernet0/1.5
А вот в Питере (и в Кемерово) один:
spb-vsl-gw1#sh ip OSPF neighbor
Neighbor ID Pri State Dead Time Address Interface
172.16.255.1 1 FULL/DR 00:00:34 172.16.2.1 FastEthernet1/0.4
Дело в том, что отношения смежности устанавливаются только между непосредственно подключенными устройствами (коммутаторы между ними не считаются), а spb-vsl-gw1 коммуницирует с kmr-gorka-gw1 через msk-arbat-gw1, поэтому их нет в соседях друг у друга.
Последний оплот консерватизма — spb-ozerki-gw1 сдастся вам без особых проблем, как и три маршрутизатора Сибирского кольца. Делается всё по аналогии — по сути меняется только Router ID. И не забудьте удалить статические маршруты.
Задача №1
Между маршрутизаторами в Питере надо уменьшить время обнаружения пропажи соседа. Маршрутизаторы должны отправлять сообщения Hello каждые 3 секунды, и считать друг друга недоступными, если 12 секунд не было сообщение Hello от соседа.
Ответ
Общий совет по всем задачам:
Даже если Вы сразу не знаете ответа и решения, постарайтесь подумать к чему относится условие задачи:
— К каким особенностям, настройкам протокола?
— Глобальные эти настройки или привязаны к конкретному интерфейсу?
Если Вы не знаете или забыли команду, такие размышления, скорее всего, приведут Вас к правильному контексту, где Вы просто, с помощью подсказки в командной строке, можете догадаться или вспомнить как настроить то, что требуется в задании.
Постарайтесь поразмышлять в таком ключе прежде чем пойдете в гугл или на какой-то сайт в поиске команд.
На реальной сети при выборе диапазона анонсируемых подсетей нужно руководствоваться регламентом и насущными потребностями.
Прежде чем мы перейдём к тестированию резервных линков и скорости, сделаем ещё одну полезную вещь.
Если бы у нас была возможность отловить трафик на интерфейсе FE0/0.2 msk-arbat-gw1, который смотрит в сторону серверов, то мы бы увидели, что каждые 10 секунд в неизвестность улетают сообщения Hello. Ответить на Hello некому, отношения смежности устанавливать не с кем, поэтому и пытаться рассылать отсюда сообщения смысла нет.
Выключается это очень просто:
msk-arbat-gw1(config)#router OSPF 1
msk-arbat-gw1(config-router)#passive-interface fastEthernet 0/0.2
Такую команду нужно дать для всех интерфейсов, на которых точно нет соседей OSPF (в том числе в сторону интернета).
В итоге картина у вас будет такая:

*Не представляю, как вы до сих пор не запутались* Кроме того, эта команда повышает безопасность — никто из этой сети не прикинется маршрутизатором и не будет пытаться поломать нас полностью.
Теперь займёмся самым интересным — тестированием.
Ничего сложного нет в настройке OSPF на всех маршрутизаторах в Сибирском кольце — сделаете сами.
И после этого картина должна быть следующей:
msk-arbat-gw1#sh ip OSPF neighbor
Neighbor ID Pri State Dead Time Address Interface
172.16.255.32 1 FULL/DR 00:00:31 172.16.2.2 FastEthernet0/1.4
172.16.255.48 1 FULL/DR 00:00:31 172.16.2.18 FastEthernet0/1.5
172.16.255.80 1 FULL/BDR 00:00:36 172.16.2.130 FastEthernet0/1.8
172.16.255.112 1 FULL/BDR 00:00:37 172.16.2.197 FastEthernet1/0.911
Питер, Кемерово, Красноярск и Владивосток — непосредственно подключенные.
msk-arbat-gw1#show ip route
Gateway of last resort is 198.51.100.1 to network 0.0.0.0
172.16.0.0/16 is variably subnetted, 25 subnets, 6 masks
C 172.16.0.0/24 is directly connected, FastEthernet0/0.3
C 172.16.1.0/24 is directly connected, FastEthernet0/0.2
C 172.16.2.0/30 is directly connected, FastEthernet0/1.4
S 172.16.2.4/30 [1/0] via 172.16.2.2
C 172.16.2.16/30 is directly connected, FastEthernet0/1.5
C 172.16.2.32/30 is directly connected, FastEthernet0/1.7
C 172.16.2.128/30 is directly connected, FastEthernet0/1.8
O 172.16.2.160/30 [110/2] via 172.16.2.130, 00:05:53, FastEthernet0/1.8
O 172.16.2.192/30 [110/2] via 172.16.2.197, 00:04:18, FastEthernet1/0.911
C 172.16.2.196/30 is directly connected, FastEthernet1/0.911
C 172.16.3.0/24 is directly connected, FastEthernet0/0.101
C 172.16.4.0/24 is directly connected, FastEthernet0/0.102
C 172.16.5.0/24 is directly connected, FastEthernet0/0.103
C 172.16.6.0/24 is directly connected, FastEthernet0/0.104
S 172.16.16.0/21 [1/0] via 172.16.2.2
S 172.16.24.0/22 [1/0] via 172.16.2.18
O 172.16.24.0/24 [110/2] via 172.16.2.18, 00:24:03, FastEthernet0/1.5
O 172.16.128.0/24 [110/2] via 172.16.2.130, 00:07:18, FastEthernet0/1.8
O 172.16.129.0/26 [110/2] via 172.16.2.130, 00:07:18, FastEthernet0/1.8
C 172.16.255.1/32 is directly connected, Loopback0
O 172.16.255.32/32 [110/2] via 172.16.2.2, 00:24:03, FastEthernet0/1.4
O 172.16.255.48/32 [110/2] via 172.16.2.18, 00:24:03, FastEthernet0/1.5
O 172.16.255.80/32 [110/2] via 172.16.2.130, 00:07:18, FastEthernet0/1.8
O 172.16.255.96/32 [110/3] via 172.16.2.130, 00:04:18, FastEthernet0/1.8
[110/3] via 172.16.2.197, 00:04:18, FastEthernet1/0.911
O 172.16.255.112/32 [110/2] via 172.16.2.197, 00:04:28, FastEthernet1/0.911
198.51.100.0/28 is subnetted, 1 subnets
C 198.51.100.0 is directly connected, FastEthernet0/1.6
S* 0.0.0.0/0 [1/0] via 198.51.100.1
Все обо всех всё знают.
Каким маршрутом трафик доставляется из Москвы в Красноярск? Из таблицы видно, что krs-stolbi-gw1 подключен напрямую и это же видно из трассировки:

msk-arbat-gw1#traceroute 172.16.128.1
Type escape sequence to abort.
Tracing the route to 172.16.128.1
1 172.16.2.130 35 msec 8 msec 5 msec
Теперь рвём интерфейс между Москвой и Красноярском и смотрим, через сколько линк восстановится.
Не проходит и 5 секунд, как все маршрутизаторы узнали о происшествии и пересчитали свои таблицы маршрутизации:
msk-arbat-gw1(config-subif)#do sh ip ro 172.16.128.0
Routing entry for 172.16.128.0/24
Known via "OSPF 1", distance 110, metric 4, type intra area
Last update from 172.16.2.197 on FastEthernet1/0.911, 00:00:53 ago
Routing Descriptor Blocks:
* 172.16.2.197, from 172.16.255.80, 00:00:53 ago, via FastEthernet1/0.911
Route metric is 4, traffic share count is 1
vld-gw1#sh ip route 172.16.128.0
Routing entry for 172.16.128.0/24
Known via "OSPF 1", distance 110, metric 3, type intra area
Last update from 172.16.2.193 on FastEthernet1/0, 00:01:57 ago
Routing Descriptor Blocks:
* 172.16.2.193, from 172.16.255.80, 00:01:57 ago, via FastEthernet1/0
Route metric is 3, traffic share count is 1
msk-arbat-gw1#traceroute 172.16.128.1
Type escape sequence to abort.
Tracing the route to 172.16.128.1
1 172.16.2.197 4 msec 10 msec 10 msec
2 172.16.2.193 8 msec 11 msec 15 msec
3 172.16.2.161 15 msec 13 msec 6 msec
То есть теперь Красноярска трафик достигает таким путём:

Как только вы поднимете линк, маршрутизаторы снова вступают в связь, обмениваются своими базами, пересчитываются кратчайшие пути и заносятся в таблицу маршрутизации.
На видео всё это более наглядно. Рекомендую ознакомиться.
Задача №2
После настройки OSPF на маршрутизаторах в сибирском кольце, все сети, которые находятся за маршрутизатором в центральном офисе в Москве (msk-arbat-gw1), для Хабаровска доступны по двум маршрутам (через Красноярск и через Владивосток). Но, так как канал через Красноярск лучше, то надо изменить настройки по умолчанию таким образом, чтобы Хабаровск использовал канал через Красноярск, когда он доступен. И переключался на Владивосток только если что-то случилось с каналом на Красноярск.
Ответ
Как любой хороший протокол, OSPF поддерживает аутентификацию — два соседа перед установлением соотношений соседства могут проверять подлинность полученных OSPF-сообщений. Оставляем на самостоятельное изучение — довольно просто.
Задача №3
С провайдером «Филькин сертификат» случилась неприятная история. Из-за их ошибки в настройках VPN на маршрутизатор во Владивостоке начали приходить какие-то непонятные маршруты, вероятно, от другого клиента или внутренние самого сети провайдера. Некоторые сети пересекались с локальными сетями и была потеряна связь с некоторыми участками сети. После этого случая было решено защититься на будущее от подобных ситуаций.
Ситуация, вообще говоря, надуманная и маловероятная, но в качестве задачки подойдёт.
На участке между Москвой и Владивостоком необходимо настроить маршрутизаторы таким образом, чтобы они, при установке отношений соседства, проверяли ещё и установленный пароль. Пароль должен быть: MskVladPass и передаваться он должен в виде хеша md5 (номер ключа 1).
Ответ
EIGRP
Теперь займёмся другим очень важным протоколом
Итак, чем хорош EIGRP?
- Прост в конфигурации
- Быстрое переключение на заранее просчитанный запасной маршрут
- Требует меньше ресурсов роутера (по сравнению с OSPF)
- Суммирование маршрутов на любом роутере (в OSPF только на ABR\ASBR)
- балансировка трафика на неравноценных маршрутах (OSPF только на равноценных)
Мы решили перевести одну из записей блога Ивана Пепельняка, в которой разбирается ряд популярных мифов про EIGRP:
- “EIGRP это гибридный протокол маршрутизации”. Если я правильно помню, это началось с первой презентации EIGRP много лет назад и обычно понимается как «EIGRP взял лучшее от link-state и distance-vector протоколов». Это совершенно не так. У EIGRP нет никаких отличительных особенностей link-state. Правильно будет говорить «EIGRP это продвинутый distance-vector- протокол маршрутизации».
- “EIGRP это distance-vector протокол”. Неплохо, но не до конца верно тоже. EIGRP отличается от других DV способом, которым обрабатывает потерянные маршруты (или маршруты с возрастающей метрикой). Все остальные протоколы пассивно ждут обновления информации от соседа (некоторые, например, RIP, даже блокируют маршрут для предотвращения петель маршрутизации), в то время как EIGRP ведет себя активнее и запрашивает информацию сам.
- “EIGRP сложен во внедрении и обслуживании”. Неправда. В свое время, EIGRP в больших сетях с низкоскоростными линками было сложновато правильно внедрить, но ровно до того момента, как были введены stub routers. С ними (а также несколькими исправлениями работы DUAL-алгоритма), он не чуть не хуже, чем OSPF.
- “Как и LS протоколы, EIGRP хранит таблицу топологии маршрутов, которыми обменивается”. Просто удивительно, насколько это неверно. EIGRP не имеет вообще никакого понятия о том, что находится дальше ближайших соседей, в то время как LS протоколы точно знают топологию всей области, к которой они подключены.
- “EIGRP это DV протокол, который действует, как LS”. Неплохая попытка, но по-прежнему, абсолютно неверно. LS протоколы строят таблицу маршрутизации, проходя через следующие шаги: — каждый маршрутизатор описывает сеть, исходя из информации, доступной ему локально (его линки, подсети, в которых он находится, соседи, которых он видит) посредством пакета (или нескольких), называемого LSA (в OSPF) или LSP (IS-IS)
- LSA распространяются по сети. Каждый маршрутизатор должен получить каждую LSA, созданную в его сети. Информация, полученная из LSA, заносится в таблицу топологии.
- Каждый маршрутизатор независимо анализирует свою таблицу топологии и запускает SPF алгоритм для подсчета лучших маршрутов к каждому из других маршрутизаторов Поведение EIGRP даже близко не напоминает эти шаги, поэтому непонятно, с какой стати он «действует, как LS»
Единственное, что делает EIGRP — это хранит информацию, полученную от соседа (RIP сразу же забывает то, что не может быть использовано в данный момент). В этом смысле, он похож на BGP, который тоже хранит все в таблице BGP и выбирает лучший маршрут оттуда. Таблица топологии (содержащая всю информацию, полученную от соседей), дает EIGRP преимущество перед RIP – она может содержать информацию о запасном (не используемом в данный момент) маршруте.
Теперь чуть ближе к теории работы:
Каждый процесс EIGRP обслуживает 3 таблицы:
- Таблицу соседей (neighbor table), в которой содержится информация о “соседях”, т.е. других маршрутизаторах, непосредственно подключенных к текущему и участвующих в обмене маршрутами. Можно посмотреть с помощью команды show ip eigrp neighbors
- Таблицу топологии сети (topology table), в которой содержится информация о маршрутах, полученная от соседей. Смотрим командой show ip eigrp topology
- Таблицу маршрутизации (routing table), на основе которой роутер принимает решения о перенаправлении пакетов. Просмотр через show ip route
Метрика
Для оценки качества определенного маршрута, в протоколах маршрутизации используется некое число, отражающее различные его характеристики или совокупность характеристик- метрика. Характеристики, принимаемые в расчет, могут быть разными- начиная от количества роутеров на данном маршруте и заканчивая средним арифметическим загрузки всех интерфейсов по ходу маршрута. Что касается метрики EIGRP, процитируем Jeremy Cioara: “у меня создалось впечатление, что создатели EIGRP, окинув критическим взглядом свое творение, решили, что все слишком просто и хорошо работает. И тогда они придумали формулу метрики, что бы все сказали “ВАУ, это действительно сложно и профессионально выглядит”. Узрите же полную формулу подсчета метрики EIGRP: (K1 * bw + (K2 * bw) / (256 — load) + K3 * delay) * (K5 / (reliability + K4)), в которой:
— bw это не просто пропускная способность, а (10000000/самая маленькая пропускная способность по дороге маршрута в килобитах) * 256
— delay это не просто задержка, а сумма всех задержек по дороге в десятках микросекунд * 256 (delay в командах show interface, show ip eigrp topology и прочих показывается в микросекундах!)
— K1-K5 это коэффициенты, которые служат для того, чтобы в формулу “включился” тот или иной параметр.
Страшно? было бы, если бы все это работало, как написано. На деле же из всех 4 возможных слагаемых формулы, по умолчанию используются только два: bw и delay (коэффициенты K1 и K3=1, остальные нулю), что сильно ее упрощает — мы просто складываем эти два числа (не забывая при этом, что они все равно считаются по своим формулам). Важно помнить следующее: метрика считается по худшему показателю пропускной способности по всей длине маршрута.
Если K5=0, то используется следующая формула: Metric = (K1 * bw + (K2 * bw) / (256 — load) + (K3 * delay)
Интересная штука получилась с MTU: довольно часто можно встретить сведения о том, что MTU имеет отношение к метрике EIGRP. И действительно, значения MTU передаются при обмене маршрутами. Но, как мы можем видеть из полной формулы, никакого упоминания об MTU там нет. Дело в том, что этот показатель принимается в расчет в довольно специфических случаях: например, если роутер должен отбросить один из равнозначных по остальным характеристикам маршрутов, он выберет тот, у которого меньший MTU. Хотя, не все так просто (см. комментарии).
Определимся с терминами, применяемыми внутри EIGRP. Каждый маршрут в EIGRP характеризуется двумя числами: Feasible Distance и Advertised Distance (вместо Advertised Distance иногда можно встретить Reported Distance, это одно и то же). Каждое из этих чисел представляет собой метрику, или стоимость (чем больше-тем хуже) данного маршрута с разных точек измерения: FD это “от меня до места назначения”, а AD- “от соседа, который мне рассказал об этом маршруте, до места назначения”. Ответ на закономерный вопрос “Зачем нам надо знать стоимость от соседа, если она и так включена в FD?”- чуть ниже (пока можете остановиться и поломать голову сами, если хотите).
У каждой подсети, о которой знает EIGRP, на каждом роутере существует Successor- роутер из числа соседей, через который идет лучший (с меньшей метрикой), по мнению протокола, маршрут к этой подсети. Кроме того, у подсети может также существовать один или несколько запасных маршрутов (роутер-сосед, через которого идет такой маршрут, называется Feasible Successor). EIGRP- единственный протокол маршрутизации, запоминающий запасные маршруты (в OSPF они есть, но содержатся, так сказать, в “сыром виде” в таблице топологии- их еще надо обработать алгоритмом SPF), что дает ему плюс в быстродействии: как только протокол определяет, что основной маршрут (через successor) недоступен, он сразу переключается на запасной. Для того, чтобы роутер мог стать feasible successor для маршрута, его AD должно быть меньше FD successor’а этого маршрута (вот зачем нам нужно знать AD). Это правило применяется для того, чтобы избежать колец маршрутизации.
Предыдущий абзац взорвал мозг? Материал трудный, поэтому еще раз на примере. У нас есть вот такая сеть:

С точки зрения R1, R2 является Successor’ом для подсети 192.168.2.0/24. Чтобы стать FS для этой подсети, R4 требуется, чтобы его AD была меньше FD для этого маршрута. FD у нас ((10000000/1544)*256)+(2100*256) =2195456, AD у R4 (с его точки зрения это FD, т.е. сколько ему стоит добраться до этой сети) = ((10000000/100000)*256)+(100*256)=51200. Все сходится, AD у R4 меньше, чем FD маршрута, он становится FS. *тут мозг такой и говорит: “БДЫЩЬ”*. Теперь смотрим на R3 — он анонсирует свою сеть 192.168.1.0/24 соседу R1, который, в свою очередь, рассказывает о ней своим соседям R2 и R4. R4 не в курсе, что R2 знает об этой подсети, и решает ему рассказать. R2 передает информацию о том, что он имеет доступ через R4 к подсети 192.168.1.0/24 дальше, на R1. R1 строго смотрит на FD маршрута и AD, которой хвастается R2 (которая, как легко понять по схеме, будет явно больше FD, так как включает и его тоже) и прогоняет его, чтобы не лез со всякими глупостями. Такая ситуация довольно маловероятна, но может иметь место при определенном стечении обстоятельств, например, при отключении механизма “расщепления горизонта” (split-horizon).
А теперь к более вероятной ситуации: представим, что R4 подключен к сети 192.168.2.0/24 не через FastEthernet, а через модем на 56k (задержка для dialup составляет 20000 usec), соответственно, добраться ему стоит ((10000000/56)*256)+(2000*256)= 46226176. Это больше, чем FD для этого маршрута, поэтому R4 не станет Feasible Successor’ом. Но это не значит, что EIGRP вообще не будет использовать данный маршрут. Просто переключение на него займет больше времени (подробнее об этом дальше).
Соседство
Роутеры не разговаривают о маршрутах с кем попало — прежде чем начать обмениваться информацией, они должны установить отношения соседства. После включения процесса командой router eigrp с указанием номера автономной системы, мы, командой network говорим, какие интерфейсы будут участвовать и одновременно, информацию о каких сетях мы желаем распространять. Незамедлительно, через эти интерфейсы начинают рассылаться hello-пакеты на мультикаст- адрес 224.0.0.10 (по умолчанию каждые 5 секунд для ethernet). Все маршрутизаторы с включенным EIGRP получают эти пакеты, далее каждый маршрутизатор-получатель делает следующее:
- Сверяет адрес отправителя hello-пакета, с адресом интерфейса, из которого получен пакет, и удостоверяется, что они из одной подсети
- Сверяет значения полученных из пакета K-коэффициентов (проще говоря, какие переменные используются в подсчете метрики) со своими. Понятно, что если они различаются, то метрики для маршрутов будут считаться по разным правилам, что недопустимо
- Проверяет номер автономной системы
- Опционально: если настроена аутентификация, проверяет соответствие ее типа и ключей.
Если получателя все устраивает, он добавляет отправителя в список своих соседей, и посылает ему (уже юникастом) update-пакет, в котором содержится список всех известных ему маршрутов (aka full-update). Отправитель, получив такой пакет, в свою очередь, делает то же самое. Для обмена маршрутами EIGRP использует Reliable Transport Protocol (RTP, не путать с Real-time Transport Protocol, который используется в ip-телефонии), который подразумевает подтверждение о доставке, поэтому каждый из роутеров, получив update- пакет, отвечает ack -пакетом (сокращение от acknowledgement- подтверждение). Итак, отношение соседства установлены, роутеры узнали друг у друга исчерпывающую информацию о маршрутах, что дальше? Дальше они будут продолжать посылать мультикаст hello-пакеты в подтверждение того, что они на связи, а в случае изменения топологии- update-пакеты, содержащие сведения только об изменениях (partial update).
Теперь вернемся к предыдущей схеме с модемом.

R2 по каким-то причинам потерял связь с 192.168.2.0/24. До этой подсети у него нет запасных маршрутов (т.е. отсутствует FS). Как всякий ответственный роутер с EIGRP, он хочет восстановить связь. Для этого он начинает рассылать специальные сообщения (query- пакеты) всем своим соседям, которые, в свою очередь, не находя нужного маршрута у себя, расспрашивают всех своих соседей, и так далее. Когда волна запросов докатывается до R4, он говорит “погодите-ка, у меня есть маршрут к этой подсети! Плохонький, но хоть что-то. Все про него забыли, а я-то помню”. Все это он упаковывает в reply-пакет и отправляет соседу, от которого получил запрос (query), и дальше по цепочке. Понятное дело, это все занимает больше времени, чем просто переключение на Feasible Successor, но, в итоге, мы получаем связь с подсетью.
А сейчас опасный момент: может, вы уже обратили внимание и насторожились, прочитав момент про эту веерную рассылку. Падение одного интерфейса вызывает нечто похожее на широковещательный шторм в сети (не в таких масштабах, конечно, но все-таки), причем чем больше в ней роутеров, тем больше ресурсов потратится на все эти запросы-ответы. Но это еще пол-беды. Возможна ситуация и похуже: представим, что роутеры, изображенные на картинке- это только часть большой и распределенной сети, т.е. некоторые могут находится за много тысяч километров от нашего R2, на плохих каналах и прочее. Так вот, беда в том, что, послав query соседу, роутер обязан дождаться от него reply. Неважно, что в ответе- но он должен прийти. Даже если роутер уже получил положительный ответ, как в нашем случае, он не может поставить этот маршрут в работу, пока не дождется ответа на все свои запросы. А запросы-то, может, еще где-нибудь на Аляске бродят. Такое состояние маршрута называется stuck-in-active. Тут нам нужно познакомится с терминами, отражающими состояние маршрута в EIGRP: active\passive route. Обычно они вводят в заблуждение. Здравый смысл подсказывает, что active значит маршрут “активен”, включен, работает. Однако тут все наоборот: passive это “все хорошо”, а состояние active означает, что данная подсеть недоступна, и маршрутизатор находится в активном поиске другого маршрута, рассылая query и ожидая reply. Так вот, состояние stuck-in-active (застрял в активном состоянии) может продолжатся до 3 минут! По истечение этого срока, роутер обрывает отношения соседства с тем соседом, от которого он не может дождаться ответа, и может использовать новый маршрут через R4. Подробно о проблеме
История, леденящая кровь сетевого инженера. 3 минуты даунтайма это не шутки. Как мы можем избежать инфаркта этой ситуации? Выхода два: суммирование маршрутов и так называемая stub-конфигурация.
Вообще говоря, есть еще один выход, и он называется фильтрация маршрутов (route filtering). Но это настолько объемная тема, что впроу отдельную статью под нее писать, а у нас и так уже пол-книги получилось в этот раз. Поэтому на ваше усмотрение.
Как мы уже упоминали, в EIGRP суммирование маршрутов можно проводить на любом роутере. Для иллюстрации, представим, что к нашему многострадальному R2 подключены подсети от 192.168.0.0/24 до 192.168.7.0/24, что очень удобненько суммируется в 192.168.0.0/21 (вспоминаем binary math). Роутер анонсирует этот суммарный маршрут, и все остальные знают: если адрес назначения начинается на 192.168.0-7, то это к нему. Что будет происходить, если одна из подсетей пропадет? Роутер будет рассылать query-пакеты с адресом этой сети (конкретным, например, 192.168.5.0/24), но соседи, вместо того, чтобы уже от своего имени продолжить порочную рассылку, будут сразу в ответ слать отрезвляющие реплаи, мол, это твоя подсеть, ты и разбирайся.
Второй вариант- stub- конфигурация. Образно говоря, stub означает “конец пути”, “тупик” в EIGRP, т.е., чтобы попасть в какую-то подсеть, не подключенную напрямую к такому роутеру, придется идти назад. Роутер, сконфигурированный, как stub, не будет пересылать трафик между подсетями, которые ему стали известны от EIGRP (проще говоря, которые в show ip route помечены буквой D). Кроме того, его соседи не будут отправлять ему query-пакеты. Самый распространенный случай применения- hub-and-spoke топологии, особенно с избыточными линками. Возьмем такую сеть: слева- филиалы, справа- основной сайт, главный офис и т.п. Для отказоустойчивости избыточные линки. Запущен EIGRP с дефолтными настройками.

А теперь “внимание, вопрос”: что будет, если R1 потеряет связь с R4, а R5 потеряет LAN? Трафик из подсети R1 в подсеть главного офиса будет идти по маршруту R1->R5->R2(или R3)->R4. Будет это эффективно? Нет. Будет страдать не только подсеть за R1, но и подсеть за R2 (или R3), из-за увеличения объемов трафика и его последствий. Вот для таких-то ситуаций и придуман stub. За роутерами в филиалах нет других роутеров, которые вели бы в другие подсети, это “конец дороги”, дальше только назад. Поэтому мы с легким сердцем можем сконфигурировать их как stub’ы, что, во-первых, избавит нас от проблемы с “кривым маршрутом”, изложенной чуть выше, а во-вторых, от флуда query-пакетов в случае потери маршрута.
Существуют различные режимы работы stub-роутера, задаются они командой eigrp stub:
R1(config)#router eigrp 1
R1(config-router)#eigrp stub?
connected Do advertise connected routes
leak-map Allow dynamic prefixes based on the leak-map
receive-only Set IP-EIGRP as receive only neighbor
redistributed Do advertise redistributed routes
static Do advertise static routes
summary Do advertise summary routes
По умолчанию, если просто дать команду eigrp stub, включаются режимы сonnected и summary. Интерес представляет режим receive-only, в котором роутер не анонсирует никаких сетей, только слушает, что ему говорят соседи (в RIP есть команда passive interface, которая делает то же самое, но в EIGRP она полностью отключает протокол на выбранном интерфейсе, что не позволяет установить соседство).
Важные моменты в теории EIGRP, не попавшие в статью:
- В EIGRP можно настроить аутентификацию соседей
- Концепция graceful shutdown
- Балансировка нагрузки
Практика EIGRP
“Лифт ми Ап” купили фабрику в Калининграде. Там производят мозги лифтов: микросхемы, ПО. Фабрика очень крупная — три точки по городу — три маршрутизатора соединены в кольцо.

Но вот незадача — на них уже запущен EIGRP в качестве протокола динамической маршрутизации. Причём адресация конечных узлов совсем из другой подсети — 10.0.0.0/8. Все другие параметры (линковые адреса, адреса лупбэк интерфейсов) мы поменяли, но несколько тысяч адресов локальной сети с серверами, принтерами, точками доступа — работа не на пару часов — отложили на потом, а в IP-плане зарезервировали на будущее для Калининграда подсеть 172.16.32.0/20.
Сейчас у нас используются такие сети:


Как настраивается это чудо? Незамысловато, на первый взгляд:
router eigrp 1
network 172.16.0.0 0.0.255.255
network 10.0.0.0
В EIGRP обратную маску можно задавать, указывая тем самым более узкие рамки, либо не задавать, тогда будет выбрана стандартная маска для этого класса (16 для класса B — 172.16.0.0 и 8 для класса А — 10.0.0.0)
Такие команды даются на всех маршрутизаторах Автономной Системы. АС определяется цифрой в команде router eigrp, то есть в нашем случае имеем АС №1. Эта цифра должна быть одинаковой на всех маршрутизаторах (в отличии от OSPF).
Но есть в EIGRP серьёзный подвох: по умолчанию включено автоматическое суммирование маршрутов в классовом виде (в версиях IOS до 15).
Сравним таблицы маршрутизации на трёх калининградских маршрутизаторах:
Сеть 10.0.0.1/24 подключена у нас к klgr-center-gw1 и он о ней знает:
klgr-center-gw1:
10.0.0.0/8 is variably subnetted, 2 subnets, 2 masks
D 10.0.0.0/8 is a summary, 00:35:23, Null0
C 10.0.0.0/24 is directly connected, FastEthernet1/0
Но не знает о 10.0.1.0/24 и 10.0.2.0/24/
klgr-balt-gw1 знает о своих двух сетях 10.0.1.0/24 и 10.0.2.0/24, но вот сеть 10.0.0.0/24 он куда-то спрятал.
10.0.0.0/8 is variably subnetted, 3 subnets, 2 masks
D 10.0.0.0/8 is a summary, 00:42:05, Null0
C 10.0.1.0/24 is directly connected, FastEthernet1/1.2
C 10.0.2.0/24 is directly connected, FastEthernet1/1.3
Они оба создали маршрут 10.0.0.0/8 с адресом next hop Null0.
А вот klgr-center-gw2 знает, что подсети 10.0.0.0/8 находятся за обоими его WAN интерфейсами.
D 10.0.0.0/8 [90/30720] via 172.16.2.41, 00:42:49, FastEthernet0/1
[90/30720] via 172.16.2.45, 00:38:05, FastEthernet0/0
Что-то очень странное творится.
Но, если вы проверите конфигурацию этого маршрутизатора, то, вероятно, заметите:
router eigrp 1
network 172.16.0.0
network 10.0.0.0
auto-summary
Во всём виновато автоматическое суммирование. Это самое большое зло EIGRP. Рассмотрим более подробно, что происходит. klgr-center-gw1 и klgr-balt-gw1 имеют подсети из 10.0.0.0/8, они их суммируют по умолчанию, когда передают соседям.
То есть, например, klgr-balt-gw1 передаёт не две сети 10.0.1.0/24 и 10.0.2.0/24, а одну обобщённую: 10.0.0.0/8. То есть его сосед будет думать, что за klgr-balt-gw1 находится вся эта сеть. Но, что произойдёт, если вдруг на balt-gw1 попадёт пакет с адресатом 10.0.50.243, о котором тот ничего не знает? На этот случай и создаётся так называетмый Blackhole-маршрут: 10.0.0.0/8 is a summary, 00:42:05, Null0
Полученный пакет будет выброшен в эту чёрную дыру. Это делается во избежание петель маршрутизации.
Так вот оба эти маршрутизатора создали свои blackhole-маршруты и игнорируют чужие анонсы. Реально на такой сети эти три девайса друг друга так и не смогут пинговать, пока… пока вы не отключите auto-summary.
Первое, что вы должны сделать при настройке EIGRP:
router eigrp 1
no auto-summary
На всех устройствах. И всем будет хорошо:
klgr-center-gw1:
10.0.0.0/24 is subnetted, 3 subnets
C 10.0.0.0 is directly connected, FastEthernet1/0
D 10.0.1.0 [90/30720] via 172.16.2.37, 00:03:11, FastEthernet0/0
D 10.0.2.0 [90/30720] via 172.16.2.37, 00:03:11, FastEthernet0/0
klgr-balt-gw1
10.0.0.0/24 is subnetted, 3 subnets
D 10.0.0.0 [90/30720] via 172.16.2.38, 00:08:16, FastEthernet0/1
C 10.0.1.0 is directly connected, FastEthernet1/1.2
C 10.0.2.0 is directly connected, FastEthernet1/1.3
klgr-center-gw2:
10.0.0.0/24 is subnetted, 3 subnets
D 10.0.0.0 [90/30720] via 172.16.2.45, 00:11:50, FastEthernet0/0
D 10.0.1.0 [90/30720] via 172.16.2.41, 00:11:48, FastEthernet0/1
D 10.0.2.0 [90/30720] via 172.16.2.41, 00:11:48, FastEthernet0/1
Из-за настроек различных механизмов QoS на маршрутизаторах Калининграда, было изменено значение пропускной способности на интерфейсах, эти значения теперь не соответствуют действительности. Поэтому было решено, что необходимо изменить подсчет метрики EIGRP на маршрутизаторах Калининграда таким образом, чтобы учитывалась только задержка (delay) и не учитывалась пропускная способность интерфейса (bandwidth).
Ответ
Настройка передачи маршрутов между различными протоколами
Наша задача организовать передачу маршрутов между этими протоколами: из OSPF в EIGRP и наоборот, чтобы все знали маршрут до любой подсети.
Это называется редистрибуцией (перераспределением) маршрутов.
Для её осуществления нам нужна хотя бы одна точка стыка, где будут запущены одновременно два протокола. Это может быть msk-arbat-gw1 или klgr-balt-gw1. Выберем второй.
Из EIGRP в OSPF:
klgr-gw1(config)#router ospf 1
klgr-gw1(config-router)#redistribute eigrp 1 subnets
Смотрим маршруты на msk-arbat-gw1:
msk-arbat-gw1#sh ip route
Codes: C — connected, S — static, I — IGRP, R — RIP, M — mobile, B — BGP
D — EIGRP, EX — EIGRP external, O — OSPF, IA — OSPF inter area
N1 — OSPF NSSA external type 1, N2 — OSPF NSSA external type 2
E1 — OSPF external type 1, E2 — OSPF external type 2, E — EGP
i — IS-IS, L1 — IS-IS level-1, L2 — IS-IS level-2, ia — IS-IS inter area
* — candidate default, U — per-user static route, o — ODR
P — periodic downloaded static route
Gateway of last resort is 198.51.100.1 to network 0.0.0.0
10.0.0.0/8 is variably subnetted, 3 subnets, 2 masks
O E2 10.0.0.0/8 [110/20] via 172.16.2.34, 00:25:11, FastEthernet0/1.7
O E2 10.0.1.0/24 [110/20] via 172.16.2.34, 00:25:11, FastEthernet0/1.7
O E2 10.0.2.0/24 [110/20] via 172.16.2.34, 00:24:50, FastEthernet0/1.7
172.16.0.0/16 is variably subnetted, 30 subnets, 5 masks
O E2 172.16.0.0/16 [110/20] via 172.16.2.34, 00:25:11, FastEthernet0/1.7
C 172.16.0.0/24 is directly connected, FastEthernet0/0.3
C 172.16.1.0/24 is directly connected, FastEthernet0/0.2
C 172.16.2.0/30 is directly connected, FastEthernet0/1.4
C 172.16.2.16/30 is directly connected, FastEthernet0/1.5
C 172.16.2.32/30 is directly connected, FastEthernet0/1.7
O E2 172.16.2.36/30 [110/20] via 172.16.2.34, 01:00:55, FastEthernet0/1.7
O E2 172.16.2.40/30 [110/20] via 172.16.2.34, 01:00:55, FastEthernet0/1.7
O E2 172.16.2.44/30 [110/20] via 172.16.2.34, 01:00:55, FastEthernet0/1.7
C 172.16.2.128/30 is directly connected, FastEthernet0/1.8
O 172.16.2.160/30 [110/2] via 172.16.2.130, 01:00:55, FastEthernet0/1.8
O 172.16.2.192/30 [110/2] via 172.16.2.197, 00:13:21, FastEthernet1/0.911
C 172.16.2.196/30 is directly connected, FastEthernet1/0.911
C 172.16.3.0/24 is directly connected, FastEthernet0/0.101
C 172.16.4.0/24 is directly connected, FastEthernet0/0.102
C 172.16.5.0/24 is directly connected, FastEthernet0/0.103
C 172.16.6.0/24 is directly connected, FastEthernet0/0.104
O 172.16.24.0/24 [110/2] via 172.16.2.18, 01:00:55, FastEthernet0/1.5
O 172.16.128.0/24 [110/2] via 172.16.2.130, 01:00:55, FastEthernet0/1.8
O 172.16.129.0/26 [110/2] via 172.16.2.130, 01:00:55, FastEthernet0/1.8
O 172.16.144.0/24 [110/3] via 172.16.2.130, 00:13:21, FastEthernet0/1.8
[110/3] via 172.16.2.197, 00:13:21, FastEthernet1/0.911
O 172.16.160.0/24 [110/2] via 172.16.2.197, 00:13:31, FastEthernet1/0.911
C 172.16.255.1/32 is directly connected, Loopback0
O 172.16.255.48/32 [110/2] via 172.16.2.18, 01:00:55, FastEthernet0/1.5
O E2 172.16.255.64/32 [110/20] via 172.16.2.34, 01:00:55, FastEthernet0/1.7
O E2 172.16.255.65/32 [110/20] via 172.16.2.34, 01:00:55, FastEthernet0/1.7
O E2 172.16.255.66/32 [110/20] via 172.16.2.34, 01:00:55, FastEthernet0/1.7
O 172.16.255.80/32 [110/2] via 172.16.2.130, 01:00:55, FastEthernet0/1.8
O 172.16.255.96/32 [110/3] via 172.16.2.130, 00:13:21, FastEthernet0/1.8
[110/3] via 172.16.2.197, 00:13:21, FastEthernet1/0.911
O 172.16.255.112/32 [110/2] via 172.16.2.197, 00:13:31, FastEthernet1/0.911
198.51.100.0/28 is subnetted, 1 subnets
C 198.51.100.0 is directly connected, FastEthernet0/1.6
S* 0.0.0.0/0 [1/0] via 198.51.100.1
Вот те, что с меткой Е2 — новые импортированные маршруты. Е2 — означает, что это внешние маршруты 2-го типа (External), то есть они были введены в процесс OSPF извне
Теперь из OSPF в EIGRP. Это чуточку сложнее:
klgr-gw1(config)#router eigrp 1
klgr-gw1(config-router)#redistribute ospf 1 metric 100000 20 255 1 1500
Без указания метрики (вот этого длинного набора цифр) команда выполнится, но редистрибуции не произойдёт.
Импортированные маршруты получают метку EX в таблице маршрутизации и административную дистанцию 170, вместо 90 для внутренних:
klgr-gw2#sh ip route
Gateway of last resort is not set
172.16.0.0/16 is variably subnetted, 30 subnets, 4 masks
D EX 172.16.0.0/24 [170/33280] via 172.16.2.37, 00:00:07, FastEthernet0/0
D EX 172.16.1.0/24 [170/33280] via 172.16.2.37, 00:00:07, FastEthernet0/0
D EX 172.16.2.0/30 [170/33280] via 172.16.2.37, 00:00:07, FastEthernet0/0
D EX 172.16.2.4/30 [170/33280] via 172.16.2.37, 00:00:07, FastEthernet0/0
D EX 172.16.2.16/30 [170/33280] via 172.16.2.37, 00:00:07, FastEthernet0/0
D 172.16.2.32/30 [90/30720] via 172.16.2.37, 00:38:59, FastEthernet0/0
C 172.16.2.36/30 is directly connected, FastEthernet0/0
D 172.16.2.40/30 [90/30720] via 172.16.2.37, 00:38:59, FastEthernet0/0
[90/30720] via 172.16.2.46, 00:38:59, FastEthernet0/1
….
Вот так, казалось бы незамысловато это делается, но простота поверхностная — редистрибуция таит в себе много тонких и неприятных моментов, когда добавляется хотя бы один избыточный линк между двумя разными доменами.
Универсальный совет — старайтесь избегать редистрибуции, если это возможно. Тут работает главное жизненное правило — чем проще, тем лучше.
Маршрутизатор в Москве анонсирует всем остальным маршрутизаторам в сети маршрут по умолчанию. Но на все остальные маршрутизаторы он приходит с одинаковой метрикой равной 1 и метрика не увеличивается по пути передачи маршрута.
Для удобства решено было изменить настройки по умолчанию таким образом, чтобы начальная метрика маршрута по умолчанию была 30 и по пути, с передачей маршрута по умолчанию по сети, к начальной метрике добавлялась стоимость пути. Кроме того, в дальнейшем возможно добавление резервного маршрутизатора в Москве, с которого на провайдера будет указывать ещё один маршрут по умолчанию. Резервный маршрутизатор будет использоваться только если пропадет основной, поэтому маршруты по умолчанию, которые они анонсируют должны быть с разными метриками.
Ответ
Маршрут по умолчанию
Теперь самое время проверить доступ в интернет. Из Москвы он прекрасно себе работает, а вот если проверить, например из Петербурга (помним, что мы удалили все статические маршруты):
PC>ping linkmeup.ru
Pinging 192.0.2.2 with 32 bytes of data:
Reply from 172.16.2.5: Destination host unreachable.
Reply from 172.16.2.5: Destination host unreachable.
Reply from 172.16.2.5: Destination host unreachable.
Reply from 172.16.2.5: Destination host unreachable.
Ping statistics for 192.0.2.2:
Packets: Sent = 4, Received = 0, Lost = 4 (100% loss),
Это связано с тем, что ни spb-ozerki-gw1, ни spb-vsl-gw1, ни кто-либо другой в нашей сети не знает о маршруте по умолчанию, кроме msk-arbat-gw1, на котором он настроен статически. Чтобы исправить эту ситуацию, нам достаточно дать одну команду в Москве:
msk-arbat-gw1(config)#router ospf 1
msk-arbat-gw1(config-router)#default-information originate
После этого по сети лавинно распространяется информация о том, где находится шлюз последней надежды.
Интернет теперь доступен:
PC>tracert linkmeup.ru
Tracing route to 192.0.2.2 over a maximum of 30 hops:
1 3 ms 3 ms 3 ms 172.16.17.1
2 4 ms 5 ms 12 ms 172.16.2.5
3 14 ms 20 ms 9 ms 172.16.2.1
4 17 ms 17 ms 19 ms 198.51.100.1
5 22 ms 23 ms 19 ms 192.0.2.2
Trace complete.
На маршрутизаторе klgr-balt-gw1 настроено перераспределение маршрутов EIGRP в OSPF. Далее по сети маршруты передаются как внешние с метрикой 20, которая не увеличивается по пути передачи маршрута. Необходимо изменить настройки так, чтобы по пути, с передачей внешних маршрутов по сети, к метрике внешних маршрутов добавлялась стоимость пути.
Ответ
Полезные команды для траблшутинга
- Список соседей и состояние связи с ними вызывается командой show ip ospf neighbor
msk-arbat-gw1: Neighbor ID Pri State Dead Time Address Interface 172.16.255.32 1 FULL/DROTHER 00:00:33 172.16.2.2 FastEthernet0/1.4 172.16.255.48 1 FULL/DR 00:00:34 172.16.2.18 FastEthernet0/1.5 172.16.255.64 1 FULL/DR 00:00:33 172.16.2.34 FastEthernet0/1.7 172.16.255.80 1 FULL/DR 00:00:33 172.16.2.130 FastEthernet0/1.8 172.16.255.112 1 FULL/DR 00:00:33 172.16.2.197 FastEthernet1/0.911 - Или для EIGRP: show ip eigrp neighbors
IP-EIGRP neighbors for process 1 H Address Interface Hold Uptime SRTT RTO Q Seq (sec) (ms) Cnt Num 0 172.16.2.38 Fa0/1 12 00:04:51 40 1000 0 54 1 172.16.2.42 Fa0/0 13 00:04:51 40 1000 0 58 - С помощью команды show ip protocols можно посмотреть информацию о запущенных протоколах динамической маршрутизации и их взаимосвязи.
klgr-balt-gw1:Routing Protocol is "EIGRP 1 " Outgoing update filter list for all interfaces is not set Incoming update filter list for all interfaces is not set Default networks flagged in outgoing updates Default networks accepted from incoming updates EIGRP metric weight K1=1, K2=0, K3=1, K4=0, K5=0 EIGRP maximum hopcount 100 EIGRP maximum metric variance 1 Redistributing: EIGRP 1, OSPF 1 Automatic network summarization is in effect Automatic address summarization: Maximum path: 4 Routing for Networks: 172.16.0.0 Routing Information Sources: Gateway Distance Last Update 172.16.2.42 90 4 172.16.2.38 90 4 Distance: internal 90 external 170 Routing Protocol is "OSPF 1" Outgoing update filter list for all interfaces is not set Incoming update filter list for all interfaces is not set Router ID 172.16.255.64 It is an autonomous system boundary router Redistributing External Routes from, EIGRP 1 Number of areas in this router is 1. 1 normal 0 stub 0 nssa Maximum path: 4 Routing for Networks: 172.16.2.32 0.0.0.3 area 0 Routing Information Sources: Gateway Distance Last Update 172.16.255.64 110 00:00:23 Distance: (default is 110) - Для отладки и понимания работы протоколов будет полезно воспользоваться следующими командами:
debug ip OSPF events debug ip OSPF adj debug EIGRP packets Попробуйте подёргать разные интерфейсы и посмотреть, что происходит в дебаге, какие сообщения летят.
Напоследок комплесная задачка.
На последнем совещании Лифт ми Ап было решено, что сеть Калининграда необходимо также переводить на OSPF.
Переход должен быть совершен без разрывов связи. Было решено, что лучшим вариантом будет параллельно с EIGRP поднять OSPF на трёх маршрутизаторах Калининграда и после того, как будет проверено, что вся информация о маршрутах Калининграда распространилась по остальной сети и наоборот, отключить EIGRP.
Но, так как сеть Калининграда достаточно большая, с большим количеством сетей, было решено, что необходимо отделить её от остальной сети так, чтобы изменения в сети Калининграда не приводили к запуску алгоритма SPF на других маршрутизаторах сети.
Ответ.
Материалы выпуска
- Новый IP-план, планы коммутации по каждой точке и регламент
- Файл РТ с лабораторной
- Конфигурация устройств
Полезные ссылки
Наш большой помощник XGU.ru
OSPF в cisco
OSPF
Коллеги по хабру
Inter-domain Routing Loops
Особенности работы External Type 1 и External Type 2 маршрутов в OSPF. Часть 1
Особенности работы External Type 1 и External Type 2 маршрутов в OSPF. Часть 2
Другие
В википедии
То же самое на русском
Минутка саморекламы У Сетей для самых маленьких появился свой сайт — linkmeup.ru. Теперь читать и оставлять комментарии вы можете не только в ЖЖ, но и в личном блоге этого цикла.
Благодарности
- Дмитрию JDima за правки и бесценные комментарии,
- Неотразимой Наташе Самойленко за предоставленные задачки.
- Антону Автушко за программирование сайта для блога.
- И девушке со славным именем Нина за логотип сайта.
P.S. Нашему будущему подкасту ЛинкМиАп требуется джингл и музыка на фон. Будем рады помощи, а имя композитора будет прославлено в веках.
P.P.S. Возможностей Packet Tracer нам уже не хватает. Следующий шаг — переход на что-то более серьёзное. Есть пожелания? Предлагаю устроить холивар в комментариях на тему IOU vs GNS.
Авторы
- eucariot — Марат Сибгатулин (inst, tg, in)
- Макс Gluck
Оставайтесь на связи
Пишите нам: info@linkmeup.ru
Канал в телеграме: t.me/linkmeup_podcast
Канал на youtube: youtube.com/c/linkmeup-podcast
Подкаст доступен в iTunes, Google Подкастах, Яндекс Музыке, Castbox
Сообщество в вк: vk.com/linkmeup
Группа в фб: www.facebook.com/linkmeup.sdsm
Добавить RSS в подкаст-плеер.
Пообщаться в общем чате в тг: https://t.me/linkmeup_chatПоддержите проект:



 38
38
 565704
565704
 183
183
Ещё статьи

183 коментарий
Марат, добрый день!
Ответьте пожалуйста на вопросы в предыдущих комментариях… У меня похожая проблема: при падении линка Красноярск — Москва пропадают динамические маршруты на маршрутизаторе в Красноярске, и уменьшается количество маршрутов во Владивостоке. Это случайно не глюк PT? А то я уже 2 дня бьюсь, а выхлоп нулевой((
А за материал огромное спасибо!!!
В примере выше было глупо проверять на адресе линков роутеров =|. Главный вопрос, почему на роутере krs-stolbi-gw1 при падении линка исчезают все маршруты OSPF, остаются только маршруты с типом C, то есть маршруты до подсетей непосредственно подключичных к роутеру.
Доброго времени суток. Очень надеюсь на активных пользователей в этой теме =|. Прошу помощи. Не работает нормально OSPF в сибирском кольце =(, Хелп, что не так?
Вот что есть. Packet 7.1.0.0222
Файл с уроком.
Your text to link…
Пароль enable: 2641
Динамические маршруты вначале строятся нормально, но если разорвать физическое соединение между интерфейсами перестроение маршрутов происходит не полностью… Куда копать, не пойму.
Пример.
Таблица маршрутизации до падения линка.
msk-arbat-gw1
172.16.0.0/16 is variably subnetted, 17 subnets, 2 masks
C 172.16.0.0/24 is directly connected, FastEthernet0/0.3
C 172.16.1.0/24 is directly connected, FastEthernet0/0.2
C 172.16.2.0/30 is directly connected, FastEthernet0/1.4
O 172.16.2.4/30 [110/2] via 172.16.2.2, 00:10:38, FastEthernet0/1.4
C 172.16.2.16/30 is directly connected, FastEthernet0/1.5
C 172.16.2.128/30 is directly connected, FastEthernet0/1.8
O 172.16.2.160/30 [110/2] via 172.16.2.130, 00:10:38, FastEthernet0/1.8
O 172.16.2.192/30 [110/2] via 172.16.2.197, 00:10:38, FastEthernet1/0.911
C 172.16.2.196/30 is directly connected, FastEthernet1/0.911
C 172.16.3.0/24 is directly connected, FastEthernet0/0.101
C 172.16.4.0/24 is directly connected, FastEthernet0/0.102
C 172.16.5.0/24 is directly connected, FastEthernet0/0.103
C 172.16.6.0/24 is directly connected, FastEthernet0/0.104
O 172.16.16.0/24 [110/2] via 172.16.2.2, 00:10:38, FastEthernet0/1.4
O 172.16.17.0/24 [110/3] via 172.16.2.2, 00:10:38, FastEthernet0/1.4
O 172.16.24.0/24 [110/2] via 172.16.2.18, 00:10:38, FastEthernet0/1.5
O 172.16.128.0/24 [110/2] via 172.16.2.130, 00:10:38, FastEthernet0/1.8
198.51.100.0/28 is subnetted, 1 subnets
C 198.51.100.0 is directly connected, FastEthernet0/1.6
Соседи
Neighbor ID Pri State Dead Time Address Interface
172.16.255.32 1 FULL/DR 00:00:36 172.16.2.2 FastEthernet0/1.4
172.16.255.48 1 FULL/DR 00:00:36 172.16.2.18 FastEthernet0/1.5
172.16.255.80 1 FULL/DR 00:00:36 172.16.2.130 FastEthernet0/1.8
172.16.255.112 1 FULL/DR 00:00:36 172.16.2.197 FastEthernet1/0.911
krs-stolbi-gw1
172.16.0.0/16 is variably subnetted, 17 subnets, 2 masks
O 172.16.0.0/24 [110/2] via 172.16.2.129, 00:16:29, FastEthernet0/0.8
O 172.16.1.0/24 [110/2] via 172.16.2.129, 00:16:29, FastEthernet0/0.8
O 172.16.2.0/30 [110/2] via 172.16.2.129, 00:16:29, FastEthernet0/0.8
O 172.16.2.4/30 [110/3] via 172.16.2.129, 00:16:29, FastEthernet0/0.8
O 172.16.2.16/30 [110/2] via 172.16.2.129, 00:16:29, FastEthernet0/0.8
C 172.16.2.128/30 is directly connected, FastEthernet0/0.8
C 172.16.2.160/30 is directly connected, FastEthernet0/1.9
O 172.16.2.192/30 [110/2] via 172.16.2.162, 00:16:29, FastEthernet0/1.9
O 172.16.2.196/30 [110/2] via 172.16.2.129, 00:16:29, FastEthernet0/0.8
O 172.16.3.0/24 [110/2] via 172.16.2.129, 00:16:29, FastEthernet0/0.8
O 172.16.4.0/24 [110/2] via 172.16.2.129, 00:16:29, FastEthernet0/0.8
O 172.16.5.0/24 [110/2] via 172.16.2.129, 00:16:29, FastEthernet0/0.8
O 172.16.6.0/24 [110/2] via 172.16.2.129, 00:16:29, FastEthernet0/0.8
O 172.16.16.0/24 [110/3] via 172.16.2.129, 00:16:29, FastEthernet0/0.8
O 172.16.17.0/24 [110/4] via 172.16.2.129, 00:16:29, FastEthernet0/0.8
O 172.16.24.0/24 [110/3] via 172.16.2.129, 00:16:29, FastEthernet0/0.8
C 172.16.128.0/24 is directly connected, FastEthernet1/0.5
Соседи
Neighbor ID Pri State Dead Time Address Interface
172.16.255.1 1 FULL/BDR 00:00:31 172.16.2.129 FastEthernet0/0.8
172.16.255.96 1 FULL/DR 00:00:32 172.16.2.162 FastEthernet0/1.9
tracert до интерфеса 172.16.2.130 с ПК админа.
C:\>tracert 172.16.2.130
Tracing route to 172.16.2.130 over a maximum of 30 hops:
1 1 ms 0 ms 0 ms 172.16.6.1
2 0 ms 0 ms 0 ms 172.16.2.130
Trace complete.
То есть московская циска отправляет ип пакет через БалаганТелеком.
Теперь разрываем физическое соединение между БаланТелеком и железным портом fastethernet 0/0 на krs-stolbi-gw1 и ждем пару минут.
Таблица маршрутизации после падения соединяющего линка, сообщения и соседи.
msk-arbat-gw1
Сообщение
00:21:50: %OSPF-5-ADJCHG: Process 1, Nbr 172.16.255.80 on FastEthernet0/1.8 from FULL to DOWN, Neighbor Down: Dead timer expired
00:21:50: %OSPF-5-ADJCHG: Process 1, Nbr 172.16.255.80 on FastEthernet0/1.8 from FULL to DOWN, Neighbor Down: Interface down or detached
Таблица маршрутизации
172.16.0.0/16 is variably subnetted, 17 subnets, 2 masks
C 172.16.0.0/24 is directly connected, FastEthernet0/0.3
C 172.16.1.0/24 is directly connected, FastEthernet0/0.2
C 172.16.2.0/30 is directly connected, FastEthernet0/1.4
O 172.16.2.4/30 [110/2] via 172.16.2.2, 00:26:32, FastEthernet0/1.4
C 172.16.2.16/30 is directly connected, FastEthernet0/1.5
C 172.16.2.128/30 is directly connected, FastEthernet0/1.8
O 172.16.2.160/30 [110/3] via 172.16.2.197, 00:06:06, FastEthernet1/0.911
O 172.16.2.192/30 [110/2] via 172.16.2.197, 00:26:32, FastEthernet1/0.911
C 172.16.2.196/30 is directly connected, FastEthernet1/0.911
C 172.16.3.0/24 is directly connected, FastEthernet0/0.101
C 172.16.4.0/24 is directly connected, FastEthernet0/0.102
C 172.16.5.0/24 is directly connected, FastEthernet0/0.103
C 172.16.6.0/24 is directly connected, FastEthernet0/0.104
O 172.16.16.0/24 [110/2] via 172.16.2.2, 00:26:32, FastEthernet0/1.4
O 172.16.17.0/24 [110/3] via 172.16.2.2, 00:26:32, FastEthernet0/1.4
O 172.16.24.0/24 [110/2] via 172.16.2.18, 00:26:32, FastEthernet0/1.5
O 172.16.128.0/24 [110/4] via 172.16.2.197, 00:06:06, FastEthernet1/0.911
198.51.100.0/28 is subnetted, 1 subnets
C 198.51.100.0 is directly connected, FastEthernet0/1.6
Почему остался вот этот?
C 172.16.2.128/30 is directly connected, FastEthernet0/1.8
Соседи
Neighbor ID Pri State Dead Time Address Interface
172.16.255.32 1 FULL/DR 00:00:30 172.16.2.2 FastEthernet0/1.4
172.16.255.48 1 FULL/DR 00:00:30 172.16.2.18 FastEthernet0/1.5
172.16.255.112 1 FULL/DR 00:00:30 172.16.2.197 FastEthernet1/0.911
Вроде все правильно, соседа FastEthernet0/1.8 больше нет.
krs-stolbi-gw1
Сообщения
%LINEPROTO-5-UPDOWN: Line protocol on Interface FastEthernet0/0, changed state to down
%LINEPROTO-5-UPDOWN: Line protocol on Interface FastEthernet0/0.8, changed state to down
00:21:16: %OSPF-5-ADJCHG: Process 1, Nbr 172.16.255.1 on FastEthernet0/0.8 from FULL to DOWN, Neighbor Down: Interface down or detached
Маршруты
172.16.0.0/16 is variably subnetted, 2 subnets, 2 masks
C 172.16.2.160/30 is directly connected, FastEthernet0/1.9
C 172.16.128.0/24 is directly connected, FastEthernet1/0.5
Куда делись маршруты OSFP?? O_o
Соседи
Neighbor ID Pri State Dead Time Address Interface
172.16.255.96 1 FULL/DR 00:00:37 172.16.2.162 FastEthernet0/1.9
tracert до интерфеса 172.16.2.130 с ПК админа.
Tracrert 1 0 ms 0 ms 0 ms 172.16.6.1
2 * * * Request timed out.
Марат, Максим, и вся команда linkmeup, спасибо! Классная статья.
В шаге 6 про OSPF, на мой взгляд, ошибка. После обмена DBD (юникаст) никто не шлет LSAck, продолжается обмен DBD,LSR,LSU (все юникаст), в конце DR шлет LSU на 224.0.0.5, все остальные отвечают LSAck’ами: BDR на 224.0.0.5, DROther на 224.0.0.6 (однако, бывают юникастовые LSAck, что допускает состояние Exchange)
Хотел бы поделиться примерами и особенностями, с которыми столкнулся во время изучения OSPF. Вдруг кому-нибудь пригодится. На истинность не предентую.
1 В случае одновременного получения роутерами мультикастовых Hello (например, если одновременно стартовали ospf процессы на разных роутерах, что бывает редко), каждый роутер выполняет те шаги, которые должен выполнить при получении hello: они отвечают друг другу юникастовым hello (если совпали параметры), устанавливают отношение смежности и т.д. Подробнее в RFC 2328 раздел 10.5
2 Бывают случаи 2-х юникастовых hello: R1 (cisco) шлет hello на 224.0.0.5 (например clear ip ospf process), ему отвечает сосед R2 (cisco) юникастом, на который R1 тоже отвечает юникастом. Получается 2 юникастовых hello. Тут надо гуглить ospf immediate hello
3 Выбор DR происходит в конце 2-Way, после установления двусторонних связей (если двусторонних связей нет, т.е. роутер не получил ни от кого hello и не установил соседство, он решает что он один и объявляет себя DR’ом). Роутеры уже знают о своих соседях достаточно, чтобы начать выборы DR и BDR. Выбор BDR происходит раньше выбора DR (Наряду с другими мерами это предотвращает захват функций DR и BackupDR одним маршрутизатором). Механизм описан в RFC 2328 пункты 9.4, 7.3, 7.4
3.1 Если расчеты привели к смене DR и BDR, то требуется обновить набор отношений смежности, связанных с данным интерфейсом.
3.2 Новый маршрутизатор Backup DR не может быть назначен, пока прежний маршрутизатор не примет на себя функции DR (обеспечивается за счет введения гистерезиса (запаздывания)).
4 Если DR и BDR не запланированы (ip ospf network point-to-point), то для общения не будет использоваться 224.0.0.6, а будет 224.0.0.5 (hello, LSU, LSAck). Юникастовые пакеты на определенных стадиях все также будут (hello ответы, DBD, LSR, LSU). В конечном состоянии в таблице соседства у всех будет «FULL/-»
4.1 Есть нюансы. В сетях point-to-point и виртуальных каналах значение Network Mask принятого пакета Hello игнорируется. Отправитель идентифицируется значением Router ID в заголовке OSPF пакета Hello, а не по IP-адресу отправителя. При получении пакета Hello из сети point-to-point (но не из виртуального канала) значение Neighbor IP устанавливается в соответствии с IP-адресом отправителя. И т.д. см RFC 2328
Broadcast multiaccess:
5 Все DROther между собой имеют статус 2way. FULL только до DR и BDR. Соответственно DR/BDR имеют FULL со всеми.
6 ip ospf priority 0 — запрещает роутеру быть DR или BDR, у такого роутера состояние 2way к другому DROther это нормально. Если в L2 домене нет DR или BDR, то DROther все равно будут в состоянии 2way друг с другом, маршруты пересылаться не будут.
6.1 В тех случаях, когда роутер является единственным маршрутизатором, способным стать DR, он может назначить себя на роль DR, а BDR просто не будет выбран для сети. В hello пакетах BDR будет 0.0.0.0
7 Когда базы синхронизировались и топология не перестраивается (затишье), то все шлют hello на 224.0.0.5
8 Когда новый участник поднимает ospf и в L2 домене уже есть DR и BDR, то выборы новых DR и BDR не происходят. Даже если у нового участника выше приоритет
9 Если DR не сообщив никому отвалился (BDR в это время не выполняет роль DR), то по истечении dead interval все роутеры начинают слать LSU (кто-то раньше, кто-то позже, в зависимости у кого когда сработал dead interval, причем маршрутизатор, обнаруживший отсутствие DR до того, как это удалось сделать BDR, на некоторое время выберет BDR в качестве DR и BDR одновременно). DROther’ы шлют LSU на 224.0.0.6, BDR шлет LSU на 224.0.0.5 (причем может быть несколько, т.к. прияты LSU от DROther’ов и нужно отправить LSU с новыми данными).DROther’ы шлют LSAck на 224.0.0.6, BDR шлет LSAck на 224.0.0.5 Далее BDR становится DR (на короткий период у DROther’ов в поле DR и BDR может стоять BDR). Далее выбирается BDR среди DROther. (Новые выборы DR не происходять, т.к. он уже есть. Происходят только выборы BDR из DROther)
10 Если у DR (BDR) произошли изменения в LSDB (up/down интерфейса, add network в ospf, reboot роутера, рестарт ospf и т.п.). DR (BDR) отослает LSU на 224.0.0.5 В ответ BDR (DR) шлет LSAck на 224.0.0.5, а DROther шлют LSAck на 224.0.0.6.
11 Если у DROther произошли изменения в LSDB (up/down интерфейса, add network в ospf, reboot роутера, рестарт ospf и т.п.), он шлет LSU на 224.0.0.6
11.1 Если DR и BDR живы. В ответ DR шлет LSU на 224.0.0.5 На которое отвечают BDR (LSAck на 224.0.0.5) и другие DROther’ы (LSAck на 224.0.0.6), кроме того DROther кто отправил изначальный LSU, т.к. номер LSA не изменился и отправивший проигнорирует LSU (в случае ребута, то он просто не получит LSU от DR).
11.2 Если BDR в этот момент недоступен, то DR шлет LSU на 224.0.0.5 (как если бы BDR был доступен). На которое отвечают другие DROther (LSAck на 224.0.0.6)
11.3 Если DR в этот момент недоступен, то через некоторое время (что за таймер выяснить не удалось, возможно, hello interval) BDR (видимо не получив LSU 224.0.0.5 от DR) отправит LSU юникастом на оставшиеся DROther и на DR (хоть он и не доступен). В ответ DROther шлют LSAck на 224.0.0.6
12 Старт DROther.
12.1 Если DR и BDR живы. DROther шлет Hello на 224.0.0.5 В ответ все роутеры в L2 домене (DR, BDR, DROther) отвечают юникстовым hello стартовавшему DROther’у, в котором уже адреса DR и BDR, а также соседи. Стартовавший роутер видит себя в соседях в полученном hello. Далее стандартно EXSTART, Exchange, LOADING, FULL STATE
12.2 Если BDR в этот момент недоступен и новый BDR еще не выбран. DROther, стартуя, шлет Hello на 224.0.0.5 В ответ только живые DR, DROther’ы шлют Hello юникстом, в котором адреса DR и BDR (который отвалился), а также адреса соседей. Далее обмен DBD юникастом между живыми роутерами, затем DR шлет LSU 224.0.0.5, а после hello с новым BDR. На LSU отвечают: DROther LSAck 224.0.0.6, BDR LSAck 224.0.0.5. Следом стандартно EXSTART, Exchange юникастом со стартовавшим DROther. А также LOADING: DR шлет LSU на 224.0.0.5, DROther’ы LSU на 224.0.0.6 На что отвечают DROther’ы LSAck’ами 224.0.0.6, BDR LSAck 224.0.0.5. FULL
12.3 Если DR в этот момент недоступен (и новый DR еще не выбран). DROther стартует, шлет Hello на 224.0.0.5. В ответ только живые BDR, DROther’ы шлют Hello юникстом, в котором адреса DR (который отвалился) и BDR, а также адреса соседей. Далее стандартно EXSTART, Exchange юникастом между живыми роутерами, в том числе и на упавший DR. Далее DROther’ы шлют LSU на 224.0.0.6, BDR шлет LSU на 224.0.0.5 Потом DROther’ы шлют LSAck на 224.0.0.6, BDR шлет LSAck на 224.0.0.5 Далее BDR становится DR (на короткий период у DROther’ов в поле DR и BDR может стоять BDR). Далее выбирается BDR среди DROther. (Новые выборы DR не происходять, т.к. он уже есть. Происходят только выборы BDR из DROther). FULL
Перезалейте, пожалуйста, «Файл РТ с лабораторной».
А еще не понятно с вот этим IP адресом (172.16.128.2 krs-stolbi-sw1), на сколько я понял это IP адрес коммутатора?
Тогда для того чтобы этот IP адрес прописать на коммутаторе нужно на этом коммутаторе создать VLAN?
Большое спасибо.
Здравствуйте! Большое за подробное обучение.
Подскажите пожалуйста, как добавить LAN значок в PT, как у вас в схеме Krs LAN, Khbr LAN.
Сколько пробовал ни как не получается.
привет 🙂 большое спасибо за труды, за 6 уроков на вашем сайте научился больше чем за 5 лет универа, конечно уроки забываются так как в практике не приходиться применять, но я думаю что если выпадет случай то я буду знать что есть такие решения)у меня собственно вопрос:
в калининграде добавил я ПК в сеть, прописал ему права админа в сети в аксесс листе, указал в IP конфигурации адрес днс и в общем все по правилам.
Итог: пингует айпишник сайта в интернете, пингует айпишник днс сервера. но сайт сам по адресу не хочет пинговать
может потому что айпишник ПК 10.0.0.20 а айпишник днс сервера 172.16.0.5? ведь любой комп из сети 172.16.Х.Х спокойно пингует сайты если ему это разрешено.
добавил днс сервер в сам калининград с айпишником в сети 10.0.Х.Х и он спокойно пингует все сайты.
так в чем же дело? нужно для каждого сегмента сети свой днс? я напутал с настройками? или Циско пакет трейрес тупит так?
Здравствуйте, настроил OSPF на всех роутерах. Из Хабаровска в Москву автоматически просчитался путь через Красноярск. После разрыва связи между Хабаровском и Владивостоком перестает пинговаться Москва из Хабаровска. Но ведь маршрут через Красноярск! Помогите разобраться с данной проблемой.
«на каждом роутере существует Successor- роутер из числа соседей» ©
на каждом роутере существует роутер?
Появился маленький вопрос по статье (часть вторая пьесы в восьми частях).
После запуска процесса OSPF и добавлении команды network на маршрутизаторах R1 и R2 оба маршрутизатора шлют Hello Packet мультикастово, соответственно при совпадиении параметров OSPF по идее оба должны добавить друг друга в neighbour’ы. При моделировании в GNS видно, что мультикастовый Hello был отправлен обоими роутерами без инфы о соседях. Затем R1 отправил мультикастовый Hello с инфой о соседе R2. Далее был обмен какими-то DBD без анонсов известных сетей, а вот потом уже юникастовый Hello с R2 на R1
Почему только один юникаст? как они выбирают, кто этот юникаст будет посылать, оба ведь получают идентичные мультикасты друг от друга. При этом я пробовал на Loopback’e R1 ставить больший адрес, чем на R2 и делать его в качестве RouterID — все равно unicast-Hello единственный и он с R2 на R1.
Аналогичный вопрос у меня возник при чтении статьи про MPLS, где LDP устанавливает соседство — хотя там TCP и я еще не успел промоделировать…
и еще 1 вопрос)
настраиваю линк между 2 роутерами
int fa 0/1
no sd
ip address 172.16.2.41 255.255.255.252 (для R1)
int fa 0/1
no sd
ip address 172.16.2.42 255.255.255.252 (для R2)
при наведении курсора на роутер пишет что линки в статусе «up», но лампочки на линке красные. глюк PT или что то пропускаю?
GNS сложен в освоении для новичка?
interface FastEthernet0/1
switchport mode trunk
для уточнения вопроса.
подскажите для чего в сибирском кольце воткнут свич 3го уровня (понятно что симуляция провайдера), можно ли без него. еще вопрос почему пускаем линки между москвой и владивостоком через сабинтерфеис, а не на прямую)
еще вопрос, на свиче 3го уровня, в сибирском кольце, все порты в режиме транка, но не указан собственно какие вланы он пропускает. подскажите для чего и как это реализовать?
я да, я тоже запутался!
*Не представляю, как вы до сих пор не запутались*
Запутались и делаем третий раз с начала(
Здравствуйте! У вас так интересно получается рассказывать о взаимоотношениях железяк и протоколов, что невольно подумалось: а вы случайно детям своим на ночь не рассказываете сказки о них?))) Жили-были два маршрутизатора)))
Доброго времени Уважаемые.
В следствии того, что пришлось сделать стенд для OSPF и EIGRP, заметил в статье отсутствие объяснения по поводу строки:
redistribute ospf 1 metric 100000 20 255 1 1500.
Если кому-то поможет, то:
100000 — <1-4294967295> Bandwidth metric in Kbits per second — Пропускная способность канала
20 — <0-4294967295> EIGRP delay metric, in 10 microsecond units — … собственно объем очереди в канале, зависит от пропускной способности в канале. Отношение так и не понял, на xgu: metric 1500 10. Дробные отношения разные. какие будут правильные?… надо разбираться.)))
255 — <0-255> EIGRP reliability metric where 255 is 100% reliable — то есть 255 — это 100% надежная метрика (видимо имеется ввиду метрика подключаемых маршрутов с другого протокола.)
1 — <1-255> EIGRP Effective bandwidth metric (Loading) where 255 is 100% loaded ( вот тут я не совсем понял почему в примере указано именно 1 а не 255.)
1500 — <1-65535> EIGRP MTU of the path.
— ну с MTU тут понятно думаю всем. ))
Это выводы подсказок с оборудования cisco.
Каюсь, я так и не понял, почему выставляется именно 1 а не 255 при 4-ом параметре метрики. Если кто-то сможет объяснить, буду очень благодарен.
Здравствуйте, Марат! В очередной раз огромное Вам спасибо за СДСМ!) Вы МЕГА мотивация для меня) Желаю команде СДСМ личных и профессиональных успехов, а также энтузиазма и сил для создания такого потрясающего материала!
Примечание: для передачи маршрутов между протоколами указаны следующие настройки:
klgr-gw1(config)#router ospf 1
klgr-gw1(config-router)#redistribute eigrp 1 subnets
klgr-gw1(config)#router eigrp 1
klgr-gw1(config-router)#redistribute ospf 1 metric 100000 20 255 1 1500,
но выполнив эти команды я не получил желаемого результата. Проделав различные па, сравнил вывод команд sh ip prot на klgr-balt-gw1 и заметил небольшое отличие, а именно: Routing for Networks:172.16.2.32 0.0.0.3 area 0 и все встало на свои места))
Я извиняюсь конечно) но как вынести LAN сеть в отдельный backhaul?))
Спасибо вам огромнейшее!!! До этого пытался смотреть какие-то запутанные видео на ютубе, читать какие-то муторные статьи, но все слишком разрозненно, либо материал подан крайне сумбурно, без дополнительных объяснений, про качество многих видео и звука вообще промолчу… У вас все сделано очень классно: качественные видео, материал разложен по полочкам, есть структура-изучение от простого к сложному, приятный голос и грамотная речь- смотреть одно удовольствие. Исписал уже 1/3 тетради а4 теорией и то, что мы делаем на практике, планирую подтянуть английский и с помощью знаний, полученных от ваших видео и статей, сдать экзамен CCNA.Думаю, все получится!
Марат, добрый день!
Выложен файл с лабой — но зайти не могу — пароли везде.
Хотелось бы поиграться с OSPF.
Большое спасибо за статью, очень помогла в освоении ospf, но всё же я до конца не понял почему реккомендуется принудительно выставлять router id? Не всё ли равно какой роутер главным будет? Просто на что это влияет?
Pregnancy & Breastfeeding – Safe Use of Anti-infective Agents. Increased renal blood flow and glomerular filtration rate may increase the elimination of drugs that are excreted primarily in the urine. This may require use of an ». Buy cheap Cefaclor online no prescription needed — onlinepharmacy. This drug is known to be excreted in breastmilk therefore use only when clearly needed during pregnancy. Consult doctor before breastfeeding. Buy cheap », Is flagyl excreted in breastmilkWould all people receive them or those at risk? These are questions for which answers are needed. N= 1 identified in Cochrane review identified and updated Lonergen 2009; 348 DELIRIUM update searches N= 5 included Study designs 2 RCTs Hu 2006; Lee 2005 1 quasi randomised Skrobik 2004 Non randomised Liu 2004; Miyaji 2007 1 additional Cochrane review was identified and updated within this review Overshott 2008 The Lonegren (2009) review examined the use of antipsychotics for delirium and identified three studies (Han2004; Hu 2004; Kalisvaart 2005) and the Oveshott (2008) review examined cholinesterase inhibitors for delirium and identified one study (Liptzin 2005), Order online generic Flagyl Metronidazole 200/400mg low cost overnight delivery in USA . One study identified in the Cochrane reviews, which did not meet our inclusion criteria was excluded (Han 2004). It has been estimated that in England and Wales, children with ADHD place a significant cost on health, social and education services, reaching £23 million for initial specialist assessment, and £14 million annually for follow-up care, excluding medication (King et al. These figures do not include costs incurred by adults with ADHD to health and social services. In 2006, the total annual cost of prescribed stimulants and other drugs for ADHD in England was roughly £29 million, comprising a 20% increase from the previous year (NHS Health and Social Care Information Centre, 2006; NHS Information Centre, 2007). This increase in cost is attributed in part to the increased numbers of individuals being treated, and in part to a shift in prescribing towards more expensive MR formulations, Buy online Antibiotics Metronidazole I.P. Metronidazole 200/400mg without prescription fast Delivery with Mastercard in USA . Schlander (2007) estimated that, in 2012, the ADHD pharma- cotherapy expenditures for children and young people may exceed £78 million in England, owing to an increase in the number of diagnosed cases, growing acceptance Attention deficit hyperactivity disorder 38 1563.
Liga das Torcidas: Dicas e macetes. Bactrim effectiveness birth control Buy low cost Bactrim without prescription online Glevo 500mg pills generic buy online fast Delivery with Mastercard Order . Buy Floxator Levofloxacin Online Without Prescriptions. No. Fast worldwide delivery, Glevo 500mg pills without prescription fast Delivery. Elequine Evabit Evonex Exolev Farlev Floracid Floxator Floximax Floxlevo Glevo Iquix Isofloxx Lailixin Laiwoxing Lebel Ledric 500mg × 180 pills $1.38 $248.11 $141.77 Viagra Follow the directions on your prescription label. You may take Levaquin tablets with or without food.HEALTH IN INTERNATIONAL PERSPECTIVE Fong, I. Emerging relations between infectious diseases and coronary artery disease and atherosclerosis, Buy online Antibiotics Zithromax Azithromycin 250/500mg low price overnight delivery in USA . Canadian Medical Association Journal, 163(1), 49-56. The effect of education on health: Cross-country evidence. National Center for Health Statistics. Stress, social support, and the buffering hypothesis. Psy- chological Bulletin, 98(2), 310-357. Childhood socioeco- nomic status and adult health, Order online Antibiotics Amoxil Amoxicillin 250/500mg price overnight delivery in USA. Annals of the New York Academy of Sciences, 1,186(1), 37-55.
Belastning leder till deformation av brosket med vätskeutflöde från vävnadsmatrix till omgivningen, vilket normaliseras under timmarna efter arbetet, Beställa Kamagra Oral Jelly tabletter 100 online apotek Sverige. Efter 100 knäböjningar hos människa har det rapporterats att denna normalisering kräver mer än 90 minuter (58). Tadalafil oder Viagra — Köpa Viagra online — Cascina Di Corte. Denna beredningsform kan vara ändamålsenlig köpa Viagra på nätet säkert Köpa Viagra piller 25/50/100/120/150/200 pris utan recept i Sverige, Köpa Viagra tabletter 25/50/100/120/150/200 pris nätet i Sverige. online apotek Sverige olagligt att sälja Viagra Viagra tabletter online apotek Sverige »Physical activity and self treatment in cystic fibrosis, Viagra Soft aktivt stof. Arch Dis Child 1986;61:362-7.
Asap Tutor Homework Help for Accounting Statistics Business. Asap Tutor is homework Help website for those who need help in learning Accounting Managerial Accounting Financial Accounting Intermediate Accounting . Accounts Assignment Help and Accounting Homework Help — My, Accounting homework help. Need help for accounts assignment? My Homework help offers high quality accounting homework solutions to let you finish your accounts assignment before Many admissions officers say that good written skills and command of correct use of language are important to them as they read these statements, Custom paper writing for sale high school New Jersey. Express yourself clearly and concisely. Adhere to stated word limits. Avoid clichés A medical school applicant who writes that he is good at science and wants to help other people is not exactly expressing an original thought. Stay away from often-repeated or tired statements. Each essay is a crucial part of any essay we carefully study all aspects of a mental titles to the point. Why not come up with the construction of the computer researching information for another paper or your papers in many cases are included in admittance program, including a test job or an essay is easy to do. After all, once tarnished reputation in the company – are experienced in many different subjects. Our features and capabilities ensure the best college essay on philosophy from qualified writers, where to go. As you know where you can not afford yourself to the students who need to know that there are so confident about our service stands for quality, that is offered by writers who are very highly sensitive to the, I don’t know what to write my dissertation online Florida.
Super cialis — Thyroid News — Thyroid Disease ManagerThyroid Disease. Cheap cialis super compre súper discount muestra Cialis-Verkauf order descuento farmacia canadiense best price on. Cialis super in uk active from us pharmacy. Can You Get Generic Cialis Super Active Over The Counter Yes Here, Cialis Super Active sloganlari. Can You Get Generic Cialis Super Active Over The Counter Yes Here. Men's Health. Hypnotherapy Free Airmail Or Courier Shipping Canadian PharmacyDet kan skada dem, även om de uppvisar symptom som liknar dina. Om några biverkningar blir värre eller om du märker några biverkningar som inte nämns i denna information, kontakta läkare eller apotekspersonal. I denna bipacksedel finner du information om: 1, Vad händer om man äter Viagra. Vad Levitra är och vad det används för 2. FYSS finns även tillgänglig på www. BILAGA I PRODUKTRESUMÉ 1 1. LÄKEMEDLETS NAMN Levitra 5 mg filmdragerade tabletter 2, Cialis Super Active packungen.
English Essays Online Expansions — Online College Essay Service. Essay writing service in il. slander homework help. pay write essay. writing papers. homework help for kids. best college application essay service, Best college essay service. affordable ». Free Write Assignment — Best College Essay Ever — Buy Essays Online. Write my scholarly paper. reviews for essay writing services. english writing tutor. homework paper help. best paper writing service reviews. writing services »Buy Essay Writing here and we will e-mail your paper before the deadline!, Custom written papers for safe high school Texas. Our service provides a full time, full scale professional writing assistance for college and university students. To place your order — you need to submit your school instructions through our order form, attach any necessary files and process the payment. By the deadline — we will surely e-mail you your paper. Lately, online writing services have become extra popular among students. But only the best — offer Premium writing level, full time inhouse proofreading team + 24/7 online and phone support. Generally, college papers need to be submitted in a pretty short amount of time, and it is important for people to write them properly with the right information for the maximum marks. However, not every college student is able to write a good paper, because even though they are able to refer to a college paper example, it does not exactly adhere to the variety of different topics that the paper can be asked to write on. Therefore, if you are looking for college essay help, we at EssaysCapital. If you wish to get college papers for sale, we provide a range of different topics that can be written exactly according to the instructions of the client, Essay writing my role model. Writing a good college essay requires experience, because very few people are able to write the best essay in the first attempt.
HERPES SIMPLEX ENCEPHALITIS/ 51, Levaquin platelet count. COST BENEFIT ANALYSIS/ 100. COST EFFECTIVENESS ANALYSIS/ 102. COST MINIMIZATION ANALYSIS/ 103. COST OF ILLNESS/ 104. COST UTILITY ANALYSIS/ 105. However, this guideline addressed only assessment and initial management of fever in children, Bactrim ds 800 mg dose. Economic evaluation requires assess ment of healthcare resources (costs) alongside health outcomes, preferably qualityadjusted life years (QALYs). Since clinical outcomes of treatment were outside the scope of the guideline, it was anticipated that the economic literature that addressed the guideline questions would be very limited. Vibramycin drug class — Buy cheapest Vibramycin no prescription. Bactrim Trimethoprim And Sulfamethoxazole And Sulfamethoxazole 400mg 80/ 800mg 160mg 30/60/90/120/180/360 pills. Related posts: Azivista 250mg capsule generic low cost overnight shipping Indiana with Order online generic Cipro Ciprofloxacin 250/500/750/1000mg low price with Mastercard in USA., Order online generic Bactrim Trimethoprim And Sulfamethoxazole And Sulfamethoxazole 400mg + 80/800mg + 160mg price overnight shipping with VISA. Contraindications with bactrim — Order cheapest Bactrim without. Generic Bactrim is used to treat ear infections urinary tract infections bronchitis Dosage(s): And Sulfamethoxazole 400mg 80/800mg 160mg Bactrim Trimethoprim And Sulfamethoxazole And Sulfamethoxazole 400mg. Ciprowin 250mg pills online pharmacy price overnight shipping Wisconsin with VISA Buy
, Spy mobile iphone downloadThe software should not be used for illegal purposes. A parent on the other hand will just need to monitor the phone of their child/children, Google tracking by cell phone. We build our reviews on the following main points that we consider the most essential: First of all it is the potential (capability) of reporting and logging in every application. I am trying to prevent pornography from getting to my child’s mobile phone, Cell phone tracking software mac. How Do You Install Spy Phone Phone Tracker on Android 2. People do have problems with installing and using the software but most of these problems are easily avoided, when you have some real experience. How does Flexispy work?
Я не понял как R1 дойдет до сети главного офиса при потере связи с R4, если R2 и R3 будут тупиковыми роутерами. R5 же не будет знать информацию о том, что через них можно добраться до главного офиса через R4?
Спасибо большое за статьи, они очень содержательные и емкие)
Однако, у меня возникли некоторые вопросы:
1) Нужно ли настраивать 802.1q между маршрутизаторами (внутри Сибирского кольца и в Калининграде)? Если да, то я пока не могу придумать зачем. Подскажите)
2) Каким образом сбросить настройки отдельного интерфейса на роутере в дефолт? Предполагаю, что командой «default int». Может она в PT просто не работает?
Решил ради интереса настроить в CPT 6 пересылку маршрутов OSPF<->RIPv2. Собственно с настройкой OSPF никаких проблем, маршруты разошлись по сети, а в RIP маршруты тупо не идут, глюк CPT или должно работать?
Добавьте пожалуйста к статье тег «сети для самых маленьких», ибо в общем списке по тегу не отоброажается 🙁
Привет! Спасибо за хорошие статьи! ПОдскажите пожалуйста как в подготовительном стенде создать и настроить локальные сети и Интернет ( на схеме они позначены облачками).
1 А теперь “внимание, вопрос”: что будет, если R1 потеряет связь с R4, а R5 потеряет LAN? Трафик из подсети R1 в подсеть главного офиса будет идти по маршруту R1->R5->R2(или R3)->R4. Будет это эффективно? Нет.
Так если это один единственный способ добраться до ГО — в чем же его кривость? Не совсем ясно.
2 «По умолчанию, если просто дать команду eigrp stub, включаются режимы сonnected и summary. Интерес представляет режим receive-only, в котором роутер не анонсирует никаких сетей, только слушает, что ему говорят соседи.» А не теряется ли, отчасти, смысл использования IGP. Как другие роутеры узнают про подсеть за R1?
Возможно из-за этих вопросов не ясна мне до конца суть STUB
3 «в RIP есть команда passive interface, которая делает то же самое, но в EIGRP она полностью отключает протокол на выбранном интерфейсе, что не позволяет установить соседство» Как же полностью? Анонсить сеть этого интерфейса роутер будет всё равно. Слушать не будет никого — это да. И соседства не будет.
Не спора ради — уточнения для. Поправьте если я не прав.
Спасибо огромное за статьи!!! Очень все доходчиво и понятно…
Есть вопрос — passive-interface нужно вешать на каждый sub-интерфейс или достаточно повесить на физический?
Спасибо за бесценный материал автору!
С Вашего позволения, пару советов для читателей (ещё раз):
1. Если, что-то непонятно по теории в данной статье — рекомендую воспользоваться xgu.ru/wiki/EIGRP (источник доп. информации, указанный автором).
2. Если что-то В РТ не работает, так как должно работать (напр. редистрибуция из OSPF в EIGRP) используем GNS.
Вот ещё вопрос — не совсем в тему про IGP, но про маршруты и sla (видел что sla рассмотрен в другом уроке, но вопрос, мне кажется, более уместен здесь). Допустим: есть роутер с сеткой на интерфейсе 10.10.10.0/24 В этой сетки есть объект sla — 10.10.10.50. Как при падении устройства на 10.10.10.50 — объяснить роутеру, что сетка недоступна, несмотря на то что он видит что итерфейс в апе ( тем самым прописывая у себя самый приоритетный маршрут? ) Касательно Bidirectional Forwarding Detection — здесь не прокатит — нужна возможность его настройки на втором устройсте (10.10.10.50) Вообще немного опишу задачу — нужно настроить переключение с одного маршрута на другой, один из который directly connected (10.10.10.0) А ip sla при падении 10.10.10.50 падает, забирая с собой маршрут в track (10.10.10.0), и по идее уже должен подняться второй трек ( до той же сетки 10.10.10.0/24 но через другого провайдера) но он видит у себя directly в upe и маршрут приоритетный соответственно directly.
Приветствую!
Реализовал аутентификацию для протокола OSPF.
Возник следующий вопрос: пароль надо вешать на все интерфейсы или на один любой? Какой логикой следует руководствоваться?
При экспериментах получил неоднозначный результат:
1) на роутере spb-vsl-gw1 пришлось повесить пароль на оба интефейса, иначе, в случае наличия пароля только на интерфейсе 1/0 в москву, мультилеер свитч в озерках не хотел становиться соседом:
2) на роутере vld-russky-gw1 если повесить пароль на оба интерфейса, в Москву и в Хабаровск — Хабаровск переставал быть соседом.
Если же оставить пароль только на одном, любом интерфейсе, все нормально работает.
3) В то же время, на роутере krs-stolbi-gw1 пароль на обоих интерфейсах, и все нормально работает 🙂
Это глюки PT или какая-то особенность?
С уважением, Артем.
Доброго дня. Пробовал подружить ospf + eigrp в GNS3 на маршрутизаторах Cisco 3620 и на 7200… не получилось! Кто нибудь пробовал подобное?
Подскажите пожалуйста, не понимаю как сделать начальную настройку роутеров в Калининграде.
Посмотрел, пощупал, и по таблице сети реализовал, но дойдя до OSPF столкнулся с проблемой. Компьютер сети SPB (172.16.17.20) на отрез отказывается, как по ICMP, так и TCP связываться с нашим liftmeup.ru(192.0.2.2). Думал проблемы в ACL но я туда его внес и даже в стат лист и диапазоном IP этой сети разрешал все одно.
Трассировка идет только до маршрутизатора в Москве
PC>tracert liftmeup.ru
Tracing route to 192.0.2.2 over a maximum of 30 hops:
1 6 ms 2 ms 3 ms 172.16.17.1
2 3 ms 9 ms 6 ms 172.16.2.5
3 7 ms 14 ms 7 ms 172.16.2.1
4 * * * Request timed out.
Акксесс листы вот
Standard IP access list 50
permit host 172.16.6.2
permit host 172.16.17.20
Extended IP access list nat-inet
permit ip host 172.16.6.2 any
permit ip host 172.16.6.3 any
permit tcp 172.16.3.0 0.0.0.255 host 192.0.2.2 eq www
permit tcp 172.16.4.0 0.0.0.255 host 192.0.2.2 eq www
permit tcp 172.16.17.0 0.0.0.255 host 192.0.2.2 eq www
permit icmp 172.16.17.0 0.0.0.255 host 192.0.2.2
permit ip 172.16.17.0 0.0.0.255 host 192.0.2.2
permit ip host 172.16.17.20 any
Extended IP access list Servers-out
permit icmp any any
permit tcp any host 172.16.0.2 eq www
permit tcp any host 172.16.0.3 eq ftp
permit tcp any host 172.16.0.4 eq smtp
permit tcp any host 172.16.0.4 eq pop3
permit udp any host 172.16.0.5 eq domain
Что я упустил?
Спасибо Марат, всё понятно расписываешь, правда вначале мне было не совсем понятно использование шлюза по умолчанию — ведь если завести интернет в сеть, то придется маршрутизацию переделывать.
Но когда досмотрел до серии про OSPF всё выровнялось 🙂 Ждем продолжения, пусть даже на GNS3. Ждём, ждём и ждём!!! ))
Приветствую. Спасибо за ваши слова) Рад, что статьи вам полезны.
Что касается задачи: РТ очень прост — только для ознакомления с основами. С такими задачами ваше направление GNS или IOU.
Для организации L2VPN есть несколько различных способов. Но надо понимать разницу. Так L2TP — это то, что вы можете реализовать сами поверх интернета, а EoMPLS — услуга, которую может предоставить провайдер за деньги.
Честно говоря маршрутизация EIGRP меня сильно озадачила, толи материал так изложен, толи оно на самом деле так, но мне показалось что намного сложнее чем OSPF, особенно абзац с этой строчкой:
Я думаю для новичков не стоит злоупотреблять сокращениями…
Подскажите, в чем может быть дело — часть маршрутов почему-то не дистрибутируется. Вот схема сети

у меня настроен редистрибьют на New York, а EIGRP запущен только на Anchorage. В результате на Anchorage есть следущее:
1.0.0.0/8 is variably subnetted, 2 subnets, 2 masks
C 1.0.0.0/24 is directly connected, GigabitEthernet0/0
L 1.0.0.5/32 is directly connected, GigabitEthernet0/0
2.0.0.0/8 is variably subnetted, 2 subnets, 2 masks
C 2.1.1.0/24 is directly connected, GigabitEthernet0/1
L 2.1.1.1/32 is directly connected, GigabitEthernet0/1
10.0.0.0/24 is subnetted, 8 subnets
D EX 10.1.2.0/24 [170/30976] via 1.0.0.1, 00:08:31, GigabitEthernet0/0
D EX 10.1.3.0/24 [170/30976] via 1.0.0.1, 00:08:30, GigabitEthernet0/0
D EX 10.2.2.0/24 [170/30976] via 1.0.0.1, 00:08:30, GigabitEthernet0/0
D EX 10.2.3.0/24 [170/30976] via 1.0.0.1, 00:08:30, GigabitEthernet0/0
D EX 10.3.2.0/24 [170/30976] via 1.0.0.1, 00:08:30, GigabitEthernet0/0
D EX 10.3.3.0/24 [170/30976] via 1.0.0.1, 00:08:30, GigabitEthernet0/0
D EX 10.4.2.0/24 [170/30976] via 1.0.0.1, 00:08:30, GigabitEthernet0/0
D EX 10.4.3.0/24 [170/30976] via 1.0.0.1, 00:08:30, GigabitEthernet0/0
192.168.0.0/30 is subnetted, 1 subnets
D 192.168.0.4/30 [90/3072] via 1.0.0.1, 00:08:30, GigabitEthernet0/0
… а 192.168.0.0, 192.168.0.12 и 192.168.0.16 куда-то делись, при этом на New York они видны
1.0.0.0/8 is variably subnetted, 2 subnets, 2 masks
C 1.0.0.0/24 is directly connected, GigabitEthernet0/1
L 1.0.0.1/32 is directly connected, GigabitEthernet0/1
2.0.0.0/24 is subnetted, 1 subnets
D 2.1.1.0/24 [90/3072] via 1.0.0.5, 00:00:55, GigabitEthernet0/1
10.0.0.0/24 is subnetted, 8 subnets
O 10.1.2.0/24 [110/2] via 192.168.0.5, 00:16:04, GigabitEthernet0/0
O 10.1.3.0/24 [110/2] via 192.168.0.5, 00:16:04, GigabitEthernet0/0
O 10.2.2.0/24 [110/3] via 192.168.0.5, 00:16:04, GigabitEthernet0/0
O 10.2.3.0/24 [110/3] via 192.168.0.5, 00:16:04, GigabitEthernet0/0
O 10.3.2.0/24 [110/5] via 192.168.0.5, 00:16:04, GigabitEthernet0/0
O 10.3.3.0/24 [110/5] via 192.168.0.5, 00:16:04, GigabitEthernet0/0
O 10.4.2.0/24 [110/4] via 192.168.0.5, 00:16:04, GigabitEthernet0/0
O 10.4.3.0/24 [110/4] via 192.168.0.5, 00:16:04, GigabitEthernet0/0
192.168.0.0/24 is variably subnetted, 5 subnets, 2 masks
O 192.168.0.0/30 [110/2] via 192.168.0.5, 00:16:04, GigabitEthernet0/0
C 192.168.0.4/30 is directly connected, GigabitEthernet0/0
L 192.168.0.6/32 is directly connected, GigabitEthernet0/0
O 192.168.0.12/30 [110/4] via 192.168.0.5, 00:16:04, GigabitEthernet0/0
O 192.168.0.16/30 [110/3] via 192.168.0.5, 00:16:04, GigabitEthernet0/0
вот частичный конфиг с New York
router eigrp 1
redistribute ospf 1 metric 100000 20 255 1 1500
network 1.0.0.0
network 1.0.0.0 0.0.0.255
network 192.168.0.0
no auto-summary
!
router ospf 1
log-adjacency-changes
redistribute eigrp 1 subnets
network 192.168.0.0 0.0.0.255 area 0
network 1.0.0.0 0.255.255.255 area 0
!
ip classless
Если кому надо так скажем предварительный файл для начала урока по OSPF (тот что в статье уже с настроенной динамической маршрутизацией) и если кто то хочет сам, своими ручками все понастраивать и прописывать
забирайте:
fileplaneta.com/61u3rrkznzx1/seti_dlia_malenkikh_OSPF.pkt
Большое спасибо! Признаюсь, конечно, с OSPF разобрался, а вот EIGRP пока не колится — с конфигурированием как бы все действительно не сложно, но вот с пониманием процесса пока трудно. Будем грысть дальше пока не ощутим полной ясности…
Спасибо за ваши труды!
Добрый день, а можно попросить выложить (разумеется если есть) топологию (*.pkt) на тот момент когда начинается видео-урок, хочется самому тоже следуя видео-инструкциям понастраивать )))
а тот файл что в конце статьи выложен уже настроен или может частично… но первые же команды которые начинаются с эпизода описывающего практику в видеоуроке уже есть в файле конфигурации.
Спасибо.
не могу сообразить в чем дело, пытаюсь соединить две подсети 192.168.0.0/24 и 172.16.0.0/24, ospf поднял, пинг между роутерами ходит, подсети между роутерами анонсируются, шлюзы выставлены, ip хостов статикой заданы, но связь между хостами в подсетях отсутствует, дальше шлюза icmp пакеты не проходят, вот скрин с частью конфигов
У вас не соответствует файл конфигурации с видео уроком, первые конфликты возникают при настройке красноярска(
Хотел присоендиниться к стройному хору благодарностей, огромное вам спасибо!!! С момента как случайно открыл сети для самых маленьких часть нулевая уже не смог остановиться, сейчас стараюсь победить динамическую маршрутизацию. Очень радует что теория дается с практикой и наоборот, изложение материала максимально дружественное. Еще раз спасибо большое за то что вы делаете, успехов вам во всем!
Жалко что исчезла возможность сохранить локально с google диска файлы:
Новый IP-план, планы коммутации по каждой точке и регламент
Конфигурация устройств
p.s. если можно верните такую возможность 🙂
А так все на высшем уровне, впрочем как всегда 😉
Здравствуйте!
Что-то не выходит распределение ospf маршрутов в eigrp сеть.
Не появляются атрибуты EX и, соответственно, маршруты до сетей 172.16…
конфиг klgr_balt:
msk-arbat:
Соседство установлено.
Заранее спасибо за отклики!
Отличная статья, благодарен авторам за труд.
Есть небольшой вопрос, касающийся упомянутой формулы расчета метрики EIGRP и пояснений к ней:
(K1 * bw + (K2 * bw) / (256 — load) + K3 * delay) * (K5 / (reliability + K4))
То есть как нулю? Если K5=0, то вся метрика получается равной нулю. Или я где-то ошибаюсь?
Решил вспомнить забытое, настроить маршрутизацию по протоколу OSPF, но не тут то было.
Роутэры не видят друг друга как соседи, но между собой пингуются.
i049.radikal.ru/1302/c8/60a04163b3b6.jpg
[spoiler=маршрутизатор0]
interface Loopback0
ip address 172.16.100.1 255.255.255.255
!
interface FastEthernet0/0
ip address 172.16.1.1 255.255.255.0
duplex auto
speed auto
!
interface FastEthernet0/1
ip address 192.168.100.1 255.255.255.252
duplex auto
speed auto
!
interface Vlan1
no ip address
shutdown
!
router ospf 1
router-id 172.16.100.1
log-adjacency-changes
network 172.16.0.0 0.0.255.255 area 0
!
ip classless
+
Router#show ip protocols
Routing Protocol is «ospf 1»
Outgoing update filter list for all interfaces is not set
Incoming update filter list for all interfaces is not set
Router ID 172.16.100.1
Number of areas in this router is 1. 1 normal 0 stub 0 nssa
Maximum path: 4
Routing for Networks:
172.16.0.0 0.0.255.255 area 0
Routing Information Sources:
Gateway Distance Last Update
172.16.100.1 110 00:27:05
Distance: (default is 110)
[/spoiler]
[spoiler=маршрутизатор1]
interface Loopback0
ip address 172.16.100.2 255.255.255.255
!
interface FastEthernet0/0
ip address 192.168.100.2 255.255.255.252
duplex auto
speed auto
!
interface FastEthernet0/1
ip address 172.16.2.1 255.255.255.0
duplex auto
speed auto
!
interface Vlan1
no ip address
shutdown
!
router ospf 1
router-id 172.16.100.2
log-adjacency-changes
network 172.16.0.0 0.0.255.255 area 0
!
ip classless
+
Routing Protocol is «ospf 1»
Outgoing update filter list for all interfaces is not set
Incoming update filter list for all interfaces is not set
Router ID 172.16.100.2
Number of areas in this router is 1. 1 normal 0 stub 0 nssa
Maximum path: 4
Routing for Networks:
172.16.0.0 0.0.255.255 area 0
Routing Information Sources:
Gateway Distance Last Update
172.16.100.2 110 00:27:03
Distance: (default is 110)
[/spoiler]
Некак немогу понять, где я совершил ошибку…
Когда только проходил данный урок, всё получалось.
было бы здорово сделать мини выпуск по радиус серверу и показать как каналы типа e1 робят
пишу диплом пользуясь вашими уроками 😉 спасиб большое.
Но затормозил на моменте. Есть соединение типа точка точка с настроенным ospf и им нужно соединить vlan скажем 100 если на том конце и на другом у них одинаковая под сеть они просто не видят друг друга а если разные то все прекрасно работает… но смысл влана теряется… подскажите плиз
титанический труд, так толково расписать и разжевать. мое почтение и спасибо
Спасибо за статью и за проделанную работу, всем кто принимал участия в этом проекте!!!
Не большая поправка по тексту в блоке о протоколе EIGRP:
Имелся ввиду маршрутизатор klgr-balt-gw1. По тексту вроде понятно, но может запутать 🙂
И вопрос: Как траблшутить если после команд
на рутере msk-arbat-gw1 маршруты не появляются как собственно и после команд
на klgr-balt-gw1. Как найти проблему?
Статьи отличные, задачи очень нужны. Может даже стоит перед оформлением всех статей в книгу/pdf добавить задачки в предыдущие статьи. Еще раз спасибо скажу синей кнопочкой.
И кстати, про сноску с nagios, не логичнее ли в мониторинг забивать адреса интерфейсов управления устройств?
ребят, настройте Ipv6 на апаче =)
Отличные статьи, спасибо.
Можете подсказать используя какие программы вы делали видео уроки?
Всем доброго времени суток =) при настройке OSPF возникла ошибка «ospf-4-badlsatype invalid lsa bad lsa checksum type 3», кто-нибудь встречался с чем-нибудь подобным?
Спасибо большое за статьи! Очень интересно, а главное доступно! Подскажите, книга «Уэнделл Одом Официальное руководство по подготовке к сертификационным экзаменам CCNA ICND2» — хороший источник для подготовки к экзамену CCNA?? Нашел вот эту книгу, а так нахожусь в неком вакууме и не знаю за что хвататься.
Присоединяюсь ко всем благодарностям, которые прозвучали выше. С огромным удовольствием читаю Ваши статьи цикла. Много добавляете особенностей, о которых часто умалчивают даже в официальных курсах Cisco и которые всплывают только при непосредственном использовании. Это здорово! Темы, правда, пошли уже далеко «не для маленьких» 🙂 В конкретно данной статье, многое уже уровня CCNP Routing. Также, отличная идея с добавлением задачек по ходу статьи, интересно встряхнуть мозги.
Лично я жду MPLS, BGP, QoS. Выше прочитал про IPSec, тоже хорошо. Также, надеюсь на оформленное пособие всех статей в что-то вроде книги (читал ранее, что вы такое планируете сделать): у вас лучшие разьяснения и изложение материала, чем я когда-либо читал.
Продолжайте в том же духе, с нетерпением жду продолжения.
По поводу IOU vs GNS3. Использовал и то и то. В общем-то, GNS3 чуть удобнее в использовании (лично мне). Существенных проблем там несколько: использование коммутаторов сильно ограниченно и производительность страдает. IOU по этим 2 пунктам выигрывает, но есть неудобства при работе.
Про BGP не забудьте 🙂 по возможности само собой.
Огромное спасибо, материал шикарен!

А тема VLAN`ов преподнесена просто великолепно!
После изучения, за 1 вечер удалось воссоздать карту сети своего предприятия и довольно серьезно оптимизировать (Отдельное восхищение вызвал PacketTracer)
Желаю вашему проекту дальнейщего развития. Ну и, конечно, продолжать радовать нас, самых маленьких 😉
Из пожеланий: PBR, IPSEC. В сети информации достаточно, более того — все это уже реализовано. Но очень хочется Best Practice, таксказать.
Еще раз, Спасибо!
Спасибо за твой титанический труд, и очень полезный и интересный курс. Начал смотреть — оторватся невозможно. А еще понял что я почти ничего не знаю о сетях, хотя и работаю админом. Есть куда расти. Продолжай в том же духе, с нетерпением ждем новых занятий.
По возможности поддержу «синей» кнопкой. Да и не я один, думаю 🙂
Марат, присоединяюсь к благодарностям, которые тут уже прозвучали! Действительно все понятно и как правило после просмотра курса все вопросы, которые появлялись в процессе прочтения бумажного варианта исчезают. =) Отдельное спасибо за задачи =)) очень помогают в освоении курса по сетям!
Ребятки, спасибо за Ваш труд. Реально интересно преподносите такие вещи. На счёт холивара, я за GNS3, так как он портирован и для виндов. Правда тут есть другая сторона медали, много девайсов не добавить и придётся всю сеть строить на рутерах с модулями ESW.
Господи, спасибо, что есть такие люди как Вы. Из предыдущего комментария увидел Ваше имя, теперь лично — Спасибо Марат. С удовольствием читаю Ваши статьи цикла. Ставлю по окончанию прочтения перед собой задачи немного отличные от Ваших, и выполняю их. Естественно не все сразу получается, но в итоге, после разбора полетов, все работает как надо! Еще раз спасибо! Если чем либо могу помочь, я всегда рад, ведь если помогаете Вы — почему я не могу 🙂
Марат, огромное спасибо Вам и Вашим и друзьям за проделанный труд в подготовке такого замечательного цикла статей и последней в особенности! Вашу работу невозможно переоценить. Надеюсь, это только начало 🙂
Кстати, если соединить свич Балаган-Телекома с роутером Красн. прямым, а не кросс-кабелем, то все тоже заработате без ввода команд
На свиче Балаган-Тедеком необходимо войти на интерфейс влан 8, который между Московй и Красноярском, после этого он приобретет статус up, хотя и до этой команды роутера Моск. и Красн. видят друг друга. После этой операции все будет работать нормально. Сам вообще не понял почему так. Скорее всего глюк РТ.
Возможно первый hello не был обработан соседом, т.к. на нем еще не запустился ospf. Например R1 шлет hello на R2, на R2 еще не запущен ospf, соответственно принятый hello не обрабатывается. Далее запускается ospf на R2, R2 шлет hello, на который отвечает R1 юникастовым hello.
Попытался смоделировать такое в UnetLab. В случае одновременного получения роутерами мультикастовых Hello (например, clear ip ospf process одновременно на обоих), каждый роутер выполняет те шаги, которые должен выполнить при получении hello: они отвечают друг другу юникастовым hello (если совпали параметры), устанавливают отношение смежности и т.д. Можно почитать RFC 2328 раздел 10.5
Всё очень интересно, познавательно и доступно. Спасибо!
Готово. Правда, возможно, он не подойдёт к вашей версии РТ.
А еще можно сбросить пароль. Как это сделать сказано в первой части цикла (не в нулевой)
Привет.
К сожалению, сейчас не могу помочь — ничего не осталось от тех лабораторных.
Придётся вам поиграться, собирая схему сети из статьи самостоятельно. Извините.
Собрал с нуля только одно Сибирское кольцо + Москва, без LAN’ов. Происходит тоже самое, при отключении любого из соседей Хабаровска — он теряет все маршруты, остаются только директы. Обновляет эту информацию только если принудительно отрубить на нем оставшегося соседа и включить заново. Однако, если после этого включить первого отключенного соседа, то он не пересчитывает кратчайший путь и отправляет пакеты через Хабаровск в Москву. Почему-то не отрабатывает вся автоматика протокола.
До разрыва:
==============================================================================
Москва:
Route table:
Gateway of last resort is 198.51.100.1 to network 0.0.0.0
172.16.0.0/16 is variably subnetted, 26 subnets, 4 masks
C 172.16.0.0/24 is directly connected, FastEthernet0/0.3
C 172.16.1.0/24 is directly connected, FastEthernet0/0.2
C 172.16.2.0/30 is directly connected, FastEthernet0/1.4
S 172.16.2.4/30 [1/0] via 172.16.2.2
C 172.16.2.16/30 is directly connected, FastEthernet0/1.5
C 172.16.2.128/30 is directly connected, FastEthernet0/1.8
O 172.16.2.160/30 [110/2] via 172.16.2.130, 00:00:47, FastEthernet0/1.8
O 172.16.2.192/30 [110/2] via 172.16.2.197, 00:00:47, FastEthernet0/1.911
C 172.16.2.196/30 is directly connected, FastEthernet0/1.911
C 172.16.3.0/24 is directly connected, FastEthernet0/0.101
C 172.16.4.0/24 is directly connected, FastEthernet0/0.102
C 172.16.5.0/24 is directly connected, FastEthernet0/0.103
C 172.16.6.0/24 is directly connected, FastEthernet0/0.104
S 172.16.16.0/21 [1/0] via 172.16.2.2
O 172.16.17.0/24 [110/3] via 172.16.2.2, 00:00:47, FastEthernet0/1.4
S 172.16.24.0/24 [1/0] via 172.16.2.18
O 172.16.128.0/24 [110/2] via 172.16.2.130, 00:00:47, FastEthernet0/1.8
O 172.16.144.0/24 [110/3] via 172.16.2.130, 00:00:47, FastEthernet0/1.8
[110/3] via 172.16.2.197, 00:00:47, FastEthernet0/1.911
O 172.16.160.0/24 [110/2] via 172.16.2.197, 00:00:47, FastEthernet0/1.911
C 172.16.255.1/32 is directly connected, Loopback0
O 172.16.255.32/32 [110/2] via 172.16.2.2, 00:00:47, FastEthernet0/1.4
O 172.16.255.33/32 [110/3] via 172.16.2.2, 00:00:47, FastEthernet0/1.4
O 172.16.255.48/32 [110/2] via 172.16.2.18, 00:00:47, FastEthernet0/1.5
O 172.16.255.80/32 [110/2] via 172.16.2.130, 00:00:47, FastEthernet0/1.8
O 172.16.255.96/32 [110/3] via 172.16.2.130, 00:00:47, FastEthernet0/1.8
[110/3] via 172.16.2.197, 00:00:47, FastEthernet0/1.911
O 172.16.255.112/32 [110/2] via 172.16.2.197, 00:00:47, FastEthernet0/1.911
198.51.100.0/28 is subnetted, 1 subnets
C 198.51.100.0 is directly connected, FastEthernet0/1.6
S* 0.0.0.0/0 [1/0] via 198.51.100.1
======================================
Trace:
Tracing the route to 172.16.255.96
1 172.16.2.130 0 msec 0 msec 1 msec
2 172.16.2.162 0 msec 0 msec 0 msec
==============================================================================
Хабаровск:
Route table:
Gateway of last resort is not set
172.16.0.0/16 is variably subnetted, 25 subnets, 3 masks
O 172.16.0.0/24 [110/3] via 172.16.2.161, 00:02:07, FastEthernet0/0
[110/3] via 172.16.2.194, 00:02:07, FastEthernet0/1
O 172.16.1.0/24 [110/3] via 172.16.2.161, 00:02:07, FastEthernet0/0
[110/3] via 172.16.2.194, 00:02:07, FastEthernet0/1
O 172.16.2.0/30 [110/3] via 172.16.2.161, 00:02:07, FastEthernet0/0
[110/3] via 172.16.2.194, 00:02:07, FastEthernet0/1
O 172.16.2.4/30 [110/4] via 172.16.2.161, 00:02:07, FastEthernet0/0
[110/4] via 172.16.2.194, 00:02:07, FastEthernet0/1
O 172.16.2.16/30 [110/3] via 172.16.2.161, 00:02:07, FastEthernet0/0
[110/3] via 172.16.2.194, 00:02:07, FastEthernet0/1
O 172.16.2.128/30 [110/2] via 172.16.2.161, 00:02:52, FastEthernet0/0
C 172.16.2.160/30 is directly connected, FastEthernet0/0
C 172.16.2.192/30 is directly connected, FastEthernet0/1
O 172.16.2.196/30 [110/2] via 172.16.2.194, 00:02:07, FastEthernet0/1
O 172.16.3.0/24 [110/3] via 172.16.2.161, 00:02:07, FastEthernet0/0
[110/3] via 172.16.2.194, 00:02:07, FastEthernet0/1
O 172.16.4.0/24 [110/3] via 172.16.2.161, 00:02:07, FastEthernet0/0
[110/3] via 172.16.2.194, 00:02:07, FastEthernet0/1
O 172.16.5.0/24 [110/3] via 172.16.2.161, 00:02:07, FastEthernet0/0
[110/3] via 172.16.2.194, 00:02:07, FastEthernet0/1
O 172.16.6.0/24 [110/3] via 172.16.2.161, 00:02:07, FastEthernet0/0
[110/3] via 172.16.2.194, 00:02:07, FastEthernet0/1
O 172.16.17.0/24 [110/5] via 172.16.2.161, 00:02:07, FastEthernet0/0
[110/5] via 172.16.2.194, 00:02:07, FastEthernet0/1
O 172.16.24.0/24 [110/4] via 172.16.2.161, 00:02:07, FastEthernet0/0
[110/4] via 172.16.2.194, 00:02:07, FastEthernet0/1
O 172.16.128.0/24 [110/2] via 172.16.2.161, 00:02:52, FastEthernet0/0
C 172.16.144.0/24 is directly connected, FastEthernet1/0.2
O 172.16.160.0/24 [110/2] via 172.16.2.194, 00:02:07, FastEthernet0/1
O 172.16.255.1/32 [110/3] via 172.16.2.161, 00:02:07, FastEthernet0/0
[110/3] via 172.16.2.194, 00:02:07, FastEthernet0/1
O 172.16.255.32/32 [110/4] via 172.16.2.161, 00:02:07, FastEthernet0/0
[110/4] via 172.16.2.194, 00:02:07, FastEthernet0/1
O 172.16.255.33/32 [110/5] via 172.16.2.161, 00:02:07, FastEthernet0/0
[110/5] via 172.16.2.194, 00:02:07, FastEthernet0/1
O 172.16.255.48/32 [110/4] via 172.16.2.161, 00:02:07, FastEthernet0/0
[110/4] via 172.16.2.194, 00:02:07, FastEthernet0/1
O 172.16.255.80/32 [110/2] via 172.16.2.161, 00:02:52, FastEthernet0/0
C 172.16.255.96/32 is directly connected, Loopback0
O 172.16.255.112/32 [110/2] via 172.16.2.194, 00:02:07, FastEthernet0/1
======================================
Trace:
Tracing the route to 172.16.255.1
1 172.16.2.161 1 msec 1 msec 0 msec
2 172.16.2.198 0 msec 0 msec 0 msec
==============================================================================
==============================================================================
После разрыва:
Москва:
Route table:
Gateway of last resort is 198.51.100.1 to network 0.0.0.0
172.16.0.0/16 is variably subnetted, 25 subnets, 4 masks
C 172.16.0.0/24 is directly connected, FastEthernet0/0.3
C 172.16.1.0/24 is directly connected, FastEthernet0/0.2
C 172.16.2.0/30 is directly connected, FastEthernet0/1.4
S 172.16.2.4/30 [1/0] via 172.16.2.2
C 172.16.2.16/30 is directly connected, FastEthernet0/1.5
C 172.16.2.128/30 is directly connected, FastEthernet0/1.8
O 172.16.2.160/30 [110/2] via 172.16.2.130, 00:06:17, FastEthernet0/1.8
C 172.16.2.196/30 is directly connected, FastEthernet0/1.911
C 172.16.3.0/24 is directly connected, FastEthernet0/0.101
C 172.16.4.0/24 is directly connected, FastEthernet0/0.102
C 172.16.5.0/24 is directly connected, FastEthernet0/0.103
C 172.16.6.0/24 is directly connected, FastEthernet0/0.104
S 172.16.16.0/21 [1/0] via 172.16.2.2
O 172.16.17.0/24 [110/3] via 172.16.2.2, 00:12:21, FastEthernet0/1.4
S 172.16.24.0/24 [1/0] via 172.16.2.18
O 172.16.128.0/24 [110/2] via 172.16.2.130, 00:12:21, FastEthernet0/1.8
O 172.16.144.0/24 [110/3] via 172.16.2.130, 00:00:12, FastEthernet0/1.8
O 172.16.160.0/24 [110/2] via 172.16.2.197, 00:12:21, FastEthernet0/1.911
C 172.16.255.1/32 is directly connected, Loopback0
O 172.16.255.32/32 [110/2] via 172.16.2.2, 00:12:21, FastEthernet0/1.4
O 172.16.255.33/32 [110/3] via 172.16.2.2, 00:12:21, FastEthernet0/1.4
O 172.16.255.48/32 [110/2] via 172.16.2.18, 00:12:21, FastEthernet0/1.5
O 172.16.255.80/32 [110/2] via 172.16.2.130, 00:12:21, FastEthernet0/1.8
O 172.16.255.96/32 [110/3] via 172.16.2.130, 00:00:12, FastEthernet0/1.8
O 172.16.255.112/32 [110/2] via 172.16.2.197, 00:12:21, FastEthernet0/1.911
198.51.100.0/28 is subnetted, 1 subnets
C 198.51.100.0 is directly connected, FastEthernet0/1.6
S* 0.0.0.0/0 [1/0] via 198.51.100.1
======================================
Trace:
Tracing the route to 172.16.255.96
1 172.16.2.130 0 msec 0 msec 1 msec
2 * * *
==============================================================================
Хабаровск:
Route table:
Gateway of last resort is not set
172.16.0.0/16 is variably subnetted, 3 subnets, 3 masks
C 172.16.2.160/30 is directly connected, FastEthernet0/0
C 172.16.144.0/24 is directly connected, FastEthernet1/0.2
C 172.16.255.96/32 is directly connected, Loopback0
======================================
Trace:
1 * * *
2 * * *
sh ip routing table в Москве и Хабаровске до обрыва и во время.
trace из Мск в Хбр и обратно во время проблемы.
В студию!
У каждой подсети, о которой знает EIGRP, на каждом роутере существует Successor- роутер из числа соседей, через который идет лучший (с меньшей метрикой), по мнению протокола, маршрут к этой подсети. © — очень громоздкая конструкция.
не лучше ли было написать что-то вроде «router successor — соседний роутер, через который проходит лучший маршрут к заданной сети (в рамках EIGRP)»
clip2net.com/s/3vjhilU
Не понял вопрос. Где там L3-коммутатор?
GNS достаточно прост.
На сайте об этом есть даже статья. Правда для старой версии: linkmeup.ru/blog/36.html
Есть и обзор предпоследней версии: linkmeup.ru/blog/151.html
И умерли они в один день.
В cisco packet tracer наверху «new Claster». Сначала задаете устройство (роутер или свитч) и выделяете его. Потом выбираете новый класер. Устройство автоматом переходит в него, и уже внутри кластера можете добавлять устройства. Подключатся к любому уст-ву извне можно не заходя в кластер, а дотачночно кликнув на него, выбрав устр-во — выбрав интерфейс.
P.S. Команде linkmeup огромное спасибо, в частности отдельное спасибо Марату. Если бы не Ваши статьи… В общем все отлично. Благодаря Вам задумал в нашей организации отдельный сервер для стенда, что бы обучались те, кого принимаем на работу. Правда там будет не только cisco, а так же juniper, huawei… Поскольку оборудование в нашей сети мультивендорное.
Самое главное забыл написать, я имел ввиду это все в packet tracer’e. Как сделать отдельную подсеть в облако, чтобы можно было кликать на него и смотреть уже отделенную сетку в отдельной вкладке, на основной вкладке оставить только BG а все что за ним спрятать, как у Марата)
А можете пояснить вопрос? Что в данном контексте Backhaul и что вы в него хотите вынести? 🙂
Потому что это удобно. Когда вы видите в дебаге Router ID, вы точно знаете, чьё это сообщение.
Кроме того принято, чтобы Router ID совпадал, например, с LSR-ID. И это тоже удобно.
В OSPFv3 вы уже обязаны задавать его вручную, и это правильно 🙂
В описанной ситуации ответ- никак не дойдет. Тут вопрос выбора- или у нас совсем не работает одна подсеть (за R1), или у нас плохо работают 2 (за R1 и R2). В принципе, линк между R4 и R5 может помочь в решении данной проблемы.
Поддерживаю вопрос. Марат, можешь разъяснить, пожалуйста?
1) 802.1q — это технологий канального уровня и нужна, соответственно, для разруливания трафика на втором уровне. Маршрутизаторы — это сетевой уровень. Поэтому на ваш вопрос так просто нельзя ответить.
2)Да, верно. Используйте GNS.
Конфиг с редистьебьютера(вообще CPT не дает написать redistribute ospf 1 external 1 external 2 internal, точнее дает и даже не ругается, но в конфиг не добавляется).
Схема(правый верхний угод и есть rip подсеть, Ptp1.18;1.21;1.30 — редистъебьютер).

И второй вопрос. Планировал поделить ospf сеть на 2 зоны(0 и 1), в итоге зоны работали независимо(маршруты не пересылались), в интернете нашел несколько вопросов с ответами, что CPT такое не умеет, это правда?
Готово. Спасибо.
Спасибо, а то я измучелся весь.
Здравствуйте. Кнопка Cluster на верхней панели. Выделяете нужные устройства и жмакаете кнопку.
Рад, что помогает 🙂
На каждый L3-интерфейс, насколько я помню. Но лучше проверить в лабе — сейчас нет времени.
Всё верно. Спасибо.
После окончания цикла я буду пересматривать/переписывать все статьи и там уже будет GNS.
не надо пепла )))
а все же, из вашего опыта с цисками, в случае аутентификации на зону, вы пароль вешали на любой один интерфейс, или на несколько?
Я так понял, что сейчас вы работаете с huawei больше, поэтому, если вспомните, буду весьма признателен 🙂
Артём, прошу прощения. Я вам нагло соврал.
Рассказываю с позиции Huawei, а у Cisco это иначе. Действительно пароль указывается только для интерфейса. Глобально можно включить только саму возможность аутентификации.
Посыпаю голову пеплом 🙂
Марат, благодарю!
А как вы делаете аутентификацию на зону: пароль на какой интерфейс вешаете, или на все?
Т.к. пароль в любом случае можно поставить только на интерфейс.
Есть две возможности для настройки аутентификации в OSPF:
1) Глобально на зону. Тогда все маршрутизаторы должны иметь одинаковый пароль.
2) Локальный для подсети/интерфейса. В этом случае пароль и режим настраивается на каждом IP-интерфейсе отдельно (в том числена сабинтерфейсах).
Если включены одновременно оба режима, интерфейсная аутентификация приоритетнее, чем настройка для зоны.
Я бы предложил собрать схему в GNS и, если проблема воспроизводится там, вникать в детали. Как никак, а глюков там явно меньше.
Добавлю еще то, что делал аутентификацию ospf для области area 0
Сергей, давайте попробуем разобраться вместе, если вопрос еще актуален.
В чем конкретно затруднение?
На бордере у вас должно происходить натирование. Я думаю именно в нём проблема. Либо этого адреса нет в АЦЛ для ната, либо нет команды ip nat inside на интерфейсе в сторону Питера.
Рад, что всё прояснилось и статья вам помогла)
Продолжение уже давно есть. Через полгода примерно будет ещё и про мультикаст.
Вынужден согласиться. В следующей редакции исключим РТ.
Я бы не сказал, что тут много сокращений, точнее их нет вообще. Да и абзац, вроде бы, максимально прозрачно описывает ситуацию.
Еще хочу добавить для мучеников как я: РТ реально глючит.
Настройка передачи маршрутов между различными протоколами — вроде должно работает, только что либо изменит тут же маршруты пропадают, причем ребут не помогает, только полный перезапуск РТ, два часа не могу понять где у меня ошибка.
Хорошо что решили отказаться от него.
Ну я так и подумал, в принципе.
Тесты да, только если выводить эмулятор двумя интерфейсами в мир. Буду ещё думать на этот счёт.
А так много раз, конечно, приходилось уже встречать и с SAToP и CESoPSN. Правда понимание поверхностное всё же.
А. Если строго, то PWE3, конечно. Вот он в следующей теме у вас упоминается, оказывается 🙂
Pwe это как раз эмуляция соединений точка-точка поверх пакетной сети. Может переносить tdm, atm и еще много чего вроде как. Я видел только реализацию передачи tdm (того самого несчастного e1) у Интракома, Nsn, и в виде сервиса cpipe в mpls сети у Alcatel-lucent.
По поводу как показать, в голову приходит только пара роутеров, с ограниченным тегированным линком между ними. На них создаем два vlan, через 802.1p промаркировываем кадры на access портах. В одном vlan запускаем пинг от хоста подключенному к одному роутеру, до хоста на другом роутере. А в другом vlan, который метим меньшим приоритетом, создаем через jperf на виртуальных опять же хостах трафик, заведомо превышающий емкость межроутерного. Не знаю только как это gns переварит все 🙂
У меня-то у самого в планах именно такое тестирование, только вот на живом железе, и вместо пинга будет pwe e1, выведенный на прибор, а с другой стороны шлейф.
Извините, что такое PWE?
Показать QoS на эмуляторах — очень сложно. Максимум — сделать маркировку.
L3VPN ещё оооочень не скоро) К сожалению. Сам хочу ей заняться.
Тут скорее интересно показать, как делается PWE, буферы на них и т.д. Заодно на этом фоне можно и прикручивать/демонстрировать QoS, приоретизацию по VLAN, DSCP маркировка.
Насколько я помню, у вас в команде есть инженер по решениям мобильных операторов — там такая схема сейчас повсеместно на MBH и пакетной РРЛ сети 🙂
P.S. С нетерпением ожидаю подробного описания L3VPN в MPLS с его MBGP, т.к. сам пока что-то плохо осиливаю как это работает 🙂
Не пробовали собрать в GNS. Что-то РТ больше никакой веры нет.
Спасибо, Максим. Отлично сработали.
Пожалуйста, Сергей.
В принципе EIGPR не сложнее OSPF, даже в каком-то плане легче. Но у меня у самого с ним трудности, потому что абсолютно нет практики. Но, кто знает, может, в скором будущем и у Huawei появится поддержка EIGRP.
К сожалению, файла нет, но, я думаю, вам не составит труда создать всё с нуля.
Всегда, пожалуйста, обращайтесь) И слушайте наши подкасты)
вот же стыдоба))) в память засело что он включен по умолчанию и не проверил, ну вланы с соседними подсетями… это конечно я погорячился со злости что не настраивается)) включил ip routing, убрал ip из вланов, всё заработало, спасибо!
eucariot, Вы мастер 🙂
ну они как минимум не нужны в обоих случаях, вы видите, что у вас в sh ip rout маршруты выглядят как directly connected, а не изученные через OSPF.
А ip routing включен? и какая конфигурация у хостов. Дайте скриншот.
добавил вланы соседних подсетей на обоих роутерах в тщетных попытках установить связь
Для чего вам на Switch0 vlan 12 c адресом из удалённой подсети?
Теоретически, с видео может немного не бить, хотя я, помнится, те же настройки делал.
Я рад, что вы замечаете такие вещи. И, если честно, даже думаю, что они полезны.
В одной из статьей была ошибка, и читатель несколько часов бился и пытался понять, что не так. Но в итоге он оказался рад, потому что в ходе решения этой проблемы, вызванной моей ошибкой, он разобрался глубже, чем если бы он просто перенёс конфиг и всё заработало.
Я имею в виду настройку krs-stolbi-gw, там vlan другой указан
О, это радостная весть обязательно прочту как только прочту урок по ВПН, спасибо.
Очень рад, приятно слышать. И хочу вас пригласить в понедельник 24-го июня к чтению новой статьи из цикла — про BGP.
Заработало после включения/выключения интерфейса Москвы ведущего в Калининград. Такие дела!
Спасибо за беспокойство!
На info@linkmeup.ru
Вышлите полную конфигурацию трёх устройств. Как будет время — посмотрю.
Спасибо. Дельное замечание. Добавим в статью.
Если K5=0, то используется другая формула:
Metric = (K1 * bw + (K2 * bw) / (256 — load) + (K3 * delay)
Мда аж стадно стало.
interface FastEthernet0/0
ip address 192.168.100.2 255.255.255.252
router ospf 1
router-id 172.16.100.2
log-adjacency-changes
network 172.16.0.0 0.0.255.255 area 0
Бывает, глаз замылился:
Боюсь, Е1 — довольно специфическая тема. Для понимания сетей она не принципиальна, документации о его работе полно — обычный TDM же.
Радиус… уже рекомендовали. Может, будет, но много-много позже. Так что лучше тоже практиковаться на коленках.
сори уже не нужно, просто не знал что одну и туже подсеть нелзя прокинуть через третий уровень
В OSPF задаётся только сеть. Указывать конкретные интерфейсы не нужно. Они выбираются автоматически. Если подсеть интерфейса попала в диапазон, прописанный в network, OSPF там включается.
A network не прописывали на klgr-balt-gw1? У меня аналогичная ситуация. В статье вроде бы про это нет, но ведь OSPF не будет работать, если ему не указать интерфейсы. Проблема в том, что он у меня и с указанием не работает )
Ну вот. Ещё один повод не доверять РТ. Кстати, следующий выпуск про переход на GNS. Будет через пару недель.
ждем с нетерпением!
Спасибо за добрые слова. На следующей неделе микровыпуск про переход на GNS3.
Спасибо, жду статью)
GNS выбрал по объективным причинам — гораздо проще в установке и использовании и меньше проблем с законностью. Подробно в следующей статье.
Удачи в изучении! 🙂
Ох, я еще не настолько специалист, пошел искать и просвещаться. Т.к вроде буквы знакомые, а связать не удается =D
Спасибо огромное за совет.
ps: Все таки решили остановится на GNS3, а чем IOU не устроил, или в след статье будет раскрыта причина выбора?
Цикл по BGP будет обязательно. Глубину проникновения пока не могу сказать, но это точно не ограничится типовым подключением к провайдеру — будут и AS и IBGP/EBGP и всяческие атрибуты.
Кроме того, я планирую и несколько статей по MPLS, по крайней мере базовые теории MPLS, L2/L3VPN.
Но всё это не в скором будущем — планов ещё много: VPN, QoS, Multicast. Возможно даже каждая из них будет не по одной статье включать.
По MPLS могу посоветовать следующее:
«MPLS Enabled Applications» — сам по ней занимался.
«MPLS and VPN Architectures».
На сайте cisco полно информации на эту тему.
Для терминологии, возможно, будет полезна эта заметка.
К сожалению, информации и доступного объяснения на русском крайне мало, поэтому рекомендую виртуальную лабораторию и несколько свободных недель на настройку и понимание, как это работает.
Например, у меня сейчас на работе мегазадача — организовать Inter-AS Option C с использованием RSVP и транспортом MPLS/BGP. Потратил на это дело 2 недели рабочего времени, но профит очевиден.
Спасибо за отличное пособие. А цикл статей про BGP будет? Не могли бы посоветовать литературу по MPLS, нигде не могу найти что-нибудь внятное, т.е. с подробными описаниями работы протокола, ну и с примерами настройки, использования и т.п.
Что думаете про Shortest Path Bridging?
Сорри за кол-во вопросов =)
Перенес с РТ на GNS3 все работает как часы 🙂
Ответил там же. Нет команды network при настройке ospf.
Почта указана в Эбаут.
Размер сообщения надо будет поправить, спасибо за информацию.
Так вот пинги между рутерами ходят. Вашу почту не нашел. Скинул в личку один конфиг, второй не получилось превышает максимальный предел.
Ну вот, мы на шаг ближе. Если нет соседей, значит не установились отношения соседства — либо неверная настройка, либо нет связности между узлами.
Покажите ваши конфиги обоих устройств (можно на почту) и проверьте IP-связность между ними.
Редистрибуция сейчас не к месту — надо сначала разобраться с пирингом, но делается это следующими командами:
соседей нет.
как это делается?
Спасибо, внесу поправки.
На одном и том же маршрутизаторе задаёте импорт маршрутов из одного протокола в другой и обратно? То есть у вас должен быть маршрутизатор (ASBR) на котором будет запущено два протокола.
Не сталкивался с такой ситуацией. Начать нужно с дебага, я думаю.
Попробовать также импортировать прямые или статические маршруты — появляются ли они.
Спасибо за советы. Очевидно, идею с задачами будем культивировать и продолжать. Вероятно, добавим и для старых выпусков.
Сноска про Nagios как раз для того и была, чтобы показать, что лучше не использовать адреса физических интерфейсов для таких целей.
Зачем?
Да и у нас виртуальный хостинг — минимум конфигурации.
Или вы про новый цикл статей?
Спасибо вам за фидбэк.
В качестве симулятора использовал Packet Tracer. Для записи видео recordMyDesktop, Kdenlive. Для записи звука Audacity.
В принципе, подробно описывал свой опыт на хабре: habrahabr.ru/post/141031/
Будут вопросы — пишите, не стесняйтесь.
Я не сталкивался с такой проблемой. Видимо, это что-то специфическое.
В первую очередь я бы советовал проверить физическую линию на предмет ошибок CRC и настройки OSPF — что они корректны на всех узлах, особенно, если у вас мультипротокольная сеть и несколько Area. Хотя type 3 не относится, конечно, к другим Area.
В основном касательно этой проблемы выводы о проблеме софта или железа cisco и рекомендуют обращаться в поддержку.
Хорошо. Тогда мы их продолжаем. Тем более труда они требую чуть ли не меньше всего.
ссылку забыл. это все, что выпущено официальным ЦискоПресс. вот что-то из этого смотрите. собственно к экзамену лучше готовиться по официальным книжкам. эта тема сто раз поднималась на форумах по сертификации, общий смысл такой: в экзамене будут вопросы, на которые нужно отвечать cisco-way. т.е., например, из двух правильных ответов (вопрос с одним вариантом только), нужно выбирать
православправильный.я учился по Одому в основном, кажется. Но Ламли (Todd Lammle) тоже прочитал. Плюс CBT, плюс придумывал себе задачи.
Я считаю, что задачи однозначно нужно продолжать! Ибо от них только польза! Заставляет встряхнуть мозги и лишний раз залезть в книгу или гугл, а там пока искал одно прицепом и еще что-нибудь зацепил почитал =)
Забыл еще отметить, что не понравилось, то, что вы вскользь прошли по понятию area в ospf. Понимаю, что всю информацию сложно вместить, но… вы упоминули лишь одним предложением про area 0, а, что это, зачем нужны вообще зоны, ни слова, хотя это одно из фундоментальных понятий и логики работы ospf.
Я боюсь, если бы мы затронул зоны, то пришлось бы рассматривать все в подробностях: каждый тип зоны, виртуальные линки, все виды LSA. Это ещё половина нашей статьи, которая без малого 100 000 символов. Возможно, мы вернёмся к этому на новом витке.
Спасибо. Темы не для самых маленьких только потому, что элементарную часть уже объяснили, и после её прочтения, я надеюсь, читатель будет готов к прыжку)
На самом деле из ССNP тут, пожалуй, только, описание работы OSPF и перераспределение маршрутов. Всё остальное вполне укладывается в CCNA.
Насчёт задачек непонятно. Фидбека по ним почти никакого нет и я не могу понять, нужно ли их продолжать.
Высшие абстракции, вроде BGP и MPLS, будут сильно позже. Это большой пласт, который надо поднять, перетряхнуть, упростить и заодно понять самому (как в анекдоте: Я пока объяснял им, уже сам всё понял, а они так и не поняли)
По симулятору буду думать. Надо попробовать IOU — я с ним ещё не работал.
Как бы то ни было, советую переходить нa GNS. Универсальнее получается. Или на IOU. Скорее всего, на последнем мы будем отрабатывать практику следующих выпусков.
Спасибо за предостережение.
Мне повезло, сегодня перенес в продакшн, глюков не замечено.
а VPN и 802.1х будет?
BGP будет точно. Будет и MPLS и возможно даже попробуем MPLS L2/L3 VPN.
Да, возможно. А вообще будет большая тема по резервированию и прочему, возможно там и об этом поговорить. Просто с ИБ у меня слабо и целый выпуск, наверно, не потяну.
Может какую-нибудь отдельную тему по безопасности запилить и туда?
VPN вместе с IPSec’ом будет в следующем же выпуске. 802.1x… Хорошая идея. Возможно, возьмём на вооружение, но пока не знаю, в какую тему запилить.
Спасибо. Поздравляю со следующим шагом) Но на PT сильно не полагайтесь. В нём есть некоторые глюки.
Статьи будут. IPSEC будет уже в следующем выпуск. А PBR — сравнительно простая технология. Там нет особой теории. На практике, конечно, по разному используется, но вряд ли мы этому посвятим отдельную статью.
QoS, Multicast также будет обязательно. Но с практикой там будет сложно)
про QoS чуть не забыл 🙂
Очень рад, что статьи полезны. Также надеюсь, что информации в статьях действительно достаточно для понимания. Ну и рассматривать их стоит, только как стимул читать дальше и больше. Даже в статической маршрутизации мы рассмотрели не всё, что уж говорить о чём-то сложнее.
Новые статьи будут. Незавершённым этот цикл останется только в каком-то совершенно исключительном случае.:)
Спасибо за поддержку.
На самом деле, пока пишу статьи, сам окончательно запутываюсь и ближе к финалу уже кажется, что всё — тупик — в этом никому не разобраться 🙂 Плюс глаз замыливается и некоторые непонятные моменты оказываются забыты. А после того, как перечитаешь статью через недельки две, хочется полностью всё переписать. 🙂
О IOU думаем только потому, что проще нашу сеть создать. То есть 7-10 маршрутизаторов.
Сам это чудо я ещё не ковырял. Если окажется, что сильно уж сложно в установке и настройке, то выбор будет очевиден.
Очень приятно читать такие слова, Александр.
Если будут какие-то вопрос, не стесняйтесь задавайте. На сайте есть наши контакты.
В качестве помощи сейчас нам нужны джингл для подкаста, музыка на фон и хороший недорогой хостинг. Ну и кнопочка синяя сверху теперь появилась)
Спасибо, Денис.
Надеюсь, статьи действительно будут полезны. Оставайтесь на связи. После НГ будет статья о подключении удалённых узлов. А до НГ мы планируем опубликовать первый выпуск подкаста.